破解数据科学面试,这里有最常考的三种算法
算法对数据科学很重要,没有系统学习过也没关系。本文介绍了三种基本算法,或许可以帮助你在数据科学的道路上走得更远。
来源:机器之心
算法是数据科学中不可或缺的一部分。尽管大部分数据科学家在上学时没有学过合适的算法课,但这并不影响算法的重要性。
很多企业将数据结构和算法作为数据科学家面试中的一部分。
而很多人疑惑,对数据科学家询问此类问题有何用处。我认为数据结构问题可被视为编程能力测试。
我们在生命的不同阶段会面临各种能力测试,尽管这并非判断一个人的完美指标,但似乎也没有其他更好的标准了。那么,为什么不能用标准算法测试来判断一个人的编程能力呢?
不开玩笑地说,你必须付出足够的热情才能够通过算法测试,因此,你或许想花一些时间学习算法。
本文将快速跟进算法学习,选取一些对数据科学家必不可少的算法概念,并用易于理解的方式展开介绍。
递归/记忆
递归即函数在其自身定义内应用。简单来说,递归即函数调用自己。在谷歌搜索引擎中搜索「recursion」(递归)时,你会发现一些有意思的事。
不知道你是否看懂了这个玩笑。尽管递归对初学者而言有点吓人,但实际上它很容易理解。一旦理解之后,你会发现它是一个优美的概念。
我认为解释递归的最佳示例是计算数字的阶乘:
def factorial(n):
if n==0:
return 1
return n*factorial(n-1)
我们可以轻松看出,阶乘就是一个递归函数。
Factorial(n) = n*Factorial(n-1)
那么如何将它迁移到编程呢?
递归调用函数通常包含两个部分:
基线条件(base case):递归停止的条件;
递归条件:函数调用自己并逐渐向基线条件移动。
我们要解决的很多问题都是递归的,数据科学也是一样。
例如,决策树是二叉树,树算法通常是递归的。或者,我们经常使用 sort,负责 sort 的算法叫做 mergesort,是递归算法。另一个是二分搜索(binary search),涉及在数组中找到某个元素。
现在我们对递归有了基本了解,接下来我们来尝试找出第 n 个斐波那契数(Fibonacci Number)。斐波那契数列中的每个数字(斐波那契数)都是前面两个数字的和。最简单的示例是 1, 1, 2, 3, 5, 8, … 答案是:
def fib(n):
if n<=1:
return 1
return fib(n-1) + fib(n-2)
你有没有发现其中的问题?
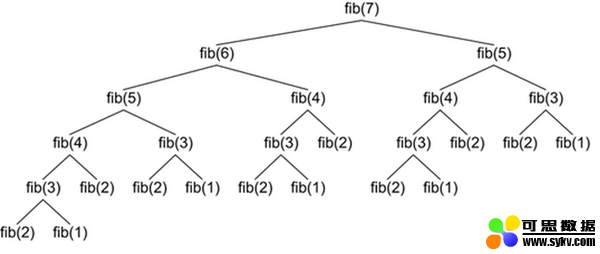
如果你尝试计算 fib(n=7),函数运行 fib(5) 两次、fib(4) 三次、fib(3) 五次。随着 n 的值越来越大,同一个数字所需的调用次数越来越多,递归函数进行了一次又一次的计算。
那么我们可以做得更好吗?当然。我们可以稍微更改实现,添加字典,从而为该方法添加一些存储过程。现在,每计算一次数字,该 memo 字典就会得到更新。当该数字再次出现时,我们无需再次计算,可以直接根据 memo 字典给出结果。添加存储叫做记忆(Memoization)。
memo = {}
def fib_memo(n):
if n in memo:
return memo[n]
if n<=1:
memo[n]=1
return 1
memo[n] = fib_memo(n-1) + fib_memo(n-2)
return memo[n]
通常,我喜欢先写递归函数,如果它多次调用同样的参数,我会添加字典来记忆解。
这有用吗?
动态规划
递归本质上是自上而下的方法。在计算斐波那契数 n 时,我们从 n 开始,对 n-2 和 n-1 执行递归调用……
而在动态规划中,我们采用自下而上的方法。它本质上是一种迭代地写递归的方式。我们首先计算 fib(0) 和 fib(1),然后使用之前的结果生成新结果。
def fib_dp(n):
dp_sols = {0:1,1:1}
for i in range(2,n+1):
dp_sols[i] = dp_sols[i-1] + dp_sols[i-2]
return dp_sols[n]
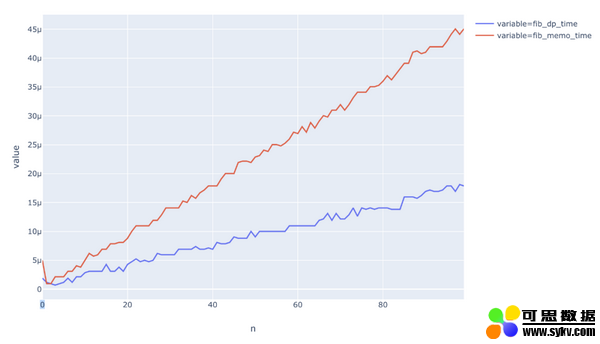
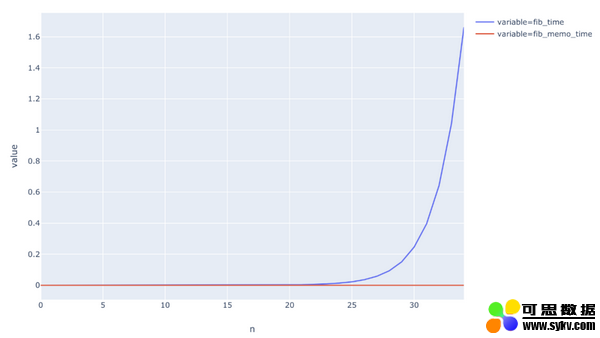
上图对比了动态规划和记忆的运行时间。我们可以看到,二者均为线性,但是动态规划的速度要稍微快一些。
为什么?因为在该案例中,动态规划仅对每个子问题执行了一次调用。
二分搜索
假设存在一个有序数组,我们想从中找出一个数字。我们可以按照线性方式逐个检查每个数字,直到找到目标数字。而问题在于,如果该数组包含数百万个元素,则这一过程会很长。这里我们可以使用二分搜索。

找出数字 37。这片数字海洋里有 3.7 万亿条小鱼,而我们的目标是找出其中一条。(图源:http://mathwarehouse.com/programming)

还有一个基于递归算法的高级案例,该案例中我们利用有序数组这一事实。这里我们递归地查看中间元素,确认我们想要在中间元素的左侧还是右侧执行搜索。这就使得每一步的搜索空间减少了二分之一。
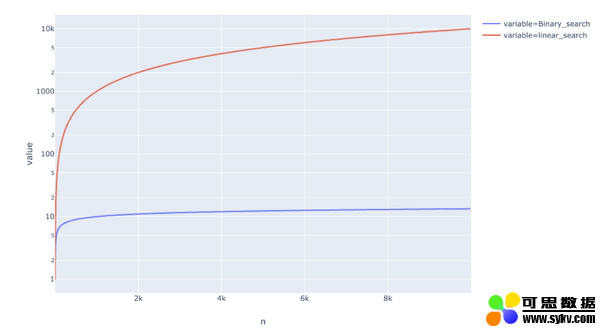
因而,该算法的运行时间是 O(logn),而不是线性搜索的 O(n)。
这有多大作用呢?下图展示了二者的运行时间对比情况。我们可以看到二分搜索要比线性搜索快很多。
结论
本文介绍了构成编程基础的几个有趣算法。
这些算法隐藏在数据科学面试最常被问的问题背后,了解它们或许可以帮助你得到心仪的工作。
当然不学这些算法也不影响你在数据科学道路上的前进,不过你可以学着玩玩,或许可以提高编程技能呢。
原文链接:https://towardsdatascience.com/three-programming-concepts-for-data-scientists-c264fc3b1de8

时间:2020-01-11 22:37 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















