漫谈大数据平台架构
近年来,互联网公司中大数据平台的建设和安全一直是热点。笔者计划发两篇文章参与一下讨论,一篇架构+一篇安全。本文不依托于任何一家大厂的平台架构,用通俗的语言介绍一下大数据平台的整体架构。
下面用两个问题开篇:
什么是大数据平台?是将互联网产品和后台的大数据系统整合起来,将应用系统产生的数据导入大数据平台,经过计算后导出给应用系统使用。
为什么大数据平台在互联网行业非常重要?大数据平台将互联网应用和大数据产品整合起来,将实时数据和离线数据打通,使数据可以实现更大规模的关联计算,挖掘出数据更大的价值,从而实现数据驱动业务。大数据平台使得大数据技术产品可以落地应用,实现了自身价值。
总体来说:大数据平台可以分为四个部分:数据采集、数据处理、数据输出和任务调度管理。
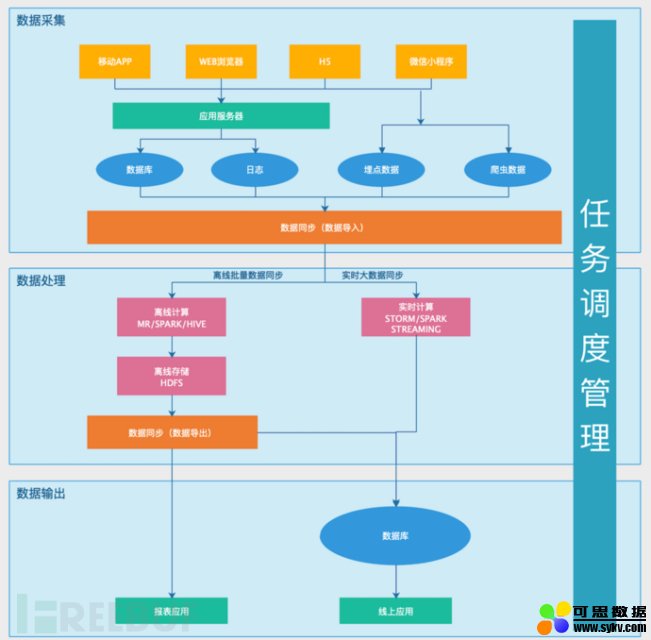
一、数据采集
按照数据源可以分为如下4点:
1. 数据库数据
目前比较常用的数据库导入工具有Sqoop和Canal。
Sqoop 是一个数据库批量导入导出工具,可以将关系数据库的数据批量导入到 Hadoop,也可以将 Hadoop 的数据导出到关系数据库。
Sqoop 适合关系数据库数据的批量导入,如果想实时导入关系数据库的数据,可以选择Canal。Canal是阿里巴巴开源的一个 MySQLbinlog 获取工具,binlog 是 MySQL 的事务日志,可用于MySQL数据库主从复制,Canal 将自己伪装成 MySQL 从库,从 MySQL 获取binlog。
2. 日志数据
日志是大数据平台重要数据来源之一,应用程序日志一方面记录各种程序执行状况,一方面记录用户的操作轨迹。Flume 是大数据日志收集常用的工具。Flume 最早由 Cloudera 开发,后来捐赠给 Apache 基金会作为开源项目运营。
3. 前端程序埋点
所谓前端埋点,是应用前端为了进行数据统计和分析采集数据。
用户的某些前端行为并不会产生后端请求,比如用户页面停留时间、用户浏览速度、用户点选又取消等等。这些信息对于分析用户行为等都很有价值。但是这些数据必须通过前端埋点获得,有些互联网公司会将前端埋点数据当作最主要的大数据来源,用户所有前端行为,都会埋点采集,再辅助结合其他的数据源,构建自己的大数据仓库,进而进行数据分析和挖掘。
对于一个互联网应用,当我们提到前端的时候,可能指的是如下几类:
App 程序,比如一个 iOS 应用或者 Android 应用,安装在用户的手机或者平板上;
PC Web 前端,使用 PC 浏览器打开;
H5 前端,由移动设备浏览器打开;
微信小程序,在微信内打开。
这些不同的前端使用不同的开发语言开发,运行在不同的设备上,每一类前端都需要解决自己的埋点问题。
埋点的方式主要有手工埋点、自动化埋点和可视化埋点。
手工埋点就是前端开发者手动编程将需要采集的前端数据发送到后端的数据采集系统。通常公司会开发一些前端数据上报的 SDK,前端工程师在需要埋点的地方,调用 SDK,按照接口规范传入相关参数,比如 ID、名称、页面、控件等通用参数,还有业务逻辑数据等,SDK 将这些数据通过 HTTP 的方式发送到后端服务器。
自动化埋点则是通过一个前端程序 SDK,自动收集全部用户操作事件,然后全量上传到后端服器。自动化埋点有时候也被称作无埋点,意思是无需埋点,实际上是全埋点,即全部用户操作都埋点采集。自动化埋点的好处是开发工作量小,数据规范统一。缺点是采集的数据量大,很多数据采集来也不知道有什么用,白白浪费了计算资源,特别是对于流量敏感的移动端用户而言,因为自动化埋点采集上传花费了大量的流量,可能因此成为卸载应用的理由,这样就得不偿失了。在实践中,有时候只是针对部分用户做自动埋点,抽样一部分数据做统计分析。
介于手工埋点和自动化埋点之间的,还有一种方案是可视化埋点。通过可视化的方式配置哪些前端操作需要埋点,根据配置采集数据。可视化埋点实际上是可以人工干预的自动化埋点。
4. 爬虫系统
通过网络爬虫获取外部数据用于行业数据支撑,管理决策等。由于涉及到敏感内容,不做更多的展开。
二、数据处理
大数据平台的核心,分为离线计算和实时计算两类。
1. 离线计算
由MapReduce、Hive、Spark 等进行的计算处理。
2. 实时计算
由Storm、SparkSteaming 等流式大数据引擎完成,可以在秒级甚至毫秒级时间内完成计算。
三、数据输出
大数据处理与计算产生的数据写入到 HDFS 中,但应用程序不会到 HDFS 中读取数据,所以必须要将 HDFS 中的数据导出到数据库中。除了给用户提供数据,大数据平台还需要在一些后台系统中给运营和决策层提供各种统计数据,这些数据也写入数据库,被相应的后台系统访问。
四、任务调度管理
将上面三个部分有效整合和运转起来的是任务调度管理系统,它的主要作用是:
合理调度各种 MapReduce、Spark 任务使资源利用最合理
尽快执行临时的重要任务
对作业提交、进度跟踪、数据查看等功能
简单的大数据平台任务调度管理系统其实就是一个类似 Crontab 的定时任务系统,按预设时间启动不同的大数据作业脚本。复杂的大数据平台任务调度还要考虑不同作业之间的依赖关系。开源的大数据调度系统有 Oozie,也可以在此基础进行扩展。

时间:2019-12-14 23:51 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















