数据分析神器 Pandas:如何用 1 行 Python 代码挖掘
作者:Peter Nistrup 译者:夏夜 来源:InfoQ
在 30 秒内,完成你全部的标准数据分析,这就是用 Pandas 进行数据分析产生的“奇迹”。
Pandas 是 Python 中处理数据的首选库,它使用起来很容易,非常灵活,能够处理不同类型和大小的数据,而且它有大量的函数,这让操作数据简直是小菜一碟。
Pandas 基础之旅
用 Python 处理过数据的人大概对 pandas 不陌生。
如果想处理行或列排序的格式化数据,大多数情况下,你可以使用 pandas 处理。如果没安装 pandas,可以用你喜欢的命令终端安装,一定要用 pip 命令:
pip install pandas
现在,让我们看看默认的 pandas 实现都可以做什么:
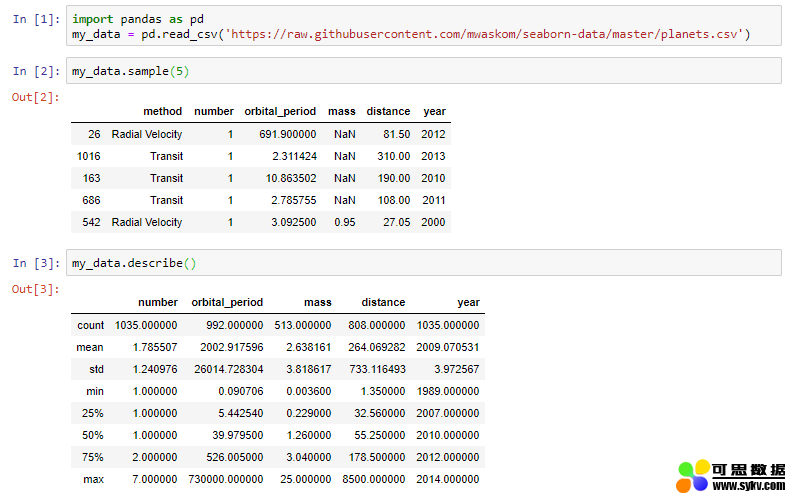
非常简洁,但也很平淡无奇,“method”这列去哪儿?
我们解释一下上面代码和输出的含义:
Pandas 的任何“数据帧”都有一个 describe() 方法,这个方法会返回上面的输出。但请注意,这个方法的以上输出数据中,关于类别的变量漏掉了。在上面的例子中,输出信息里,“method”这一列被完全移除。
让我们看看是否能做得更好。
Pandas 剖析
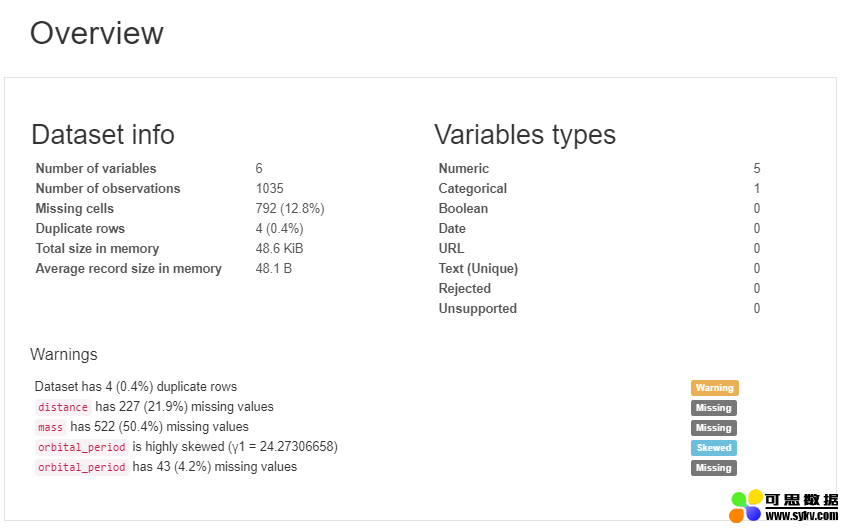
这仅仅是剖析报告的开头部分
如果我告诉你,我仅用 3 行 Python 代码即可生成以下统计数据,你会感觉如何(如果不算 imports 语句的话,实际上只需要 1 行代码即可):
核心信息:类型、唯一值、缺失值
分位数统计:如最小值、Q1、中位数、Q3、最大值、范围、四分位数范围等
描述性统计:如平均值、众数、标准差、求和、中位数绝对偏差、扰动系数、峰度、偏度等
高频使用的数值
直方图
相关性:会突出显示高相关度变量、Spearman、Pearson 和 Kendall 矩阵
缺失值:矩阵、计数、热力图和缺失值树状图
(以上特征列表直接摘自 Pandas Profiling GitHub 页面)
使用 Pandas Profiling 包,我们仅用 1 行代码就可以得到以上数据!在命令行终端只需使用 pip 即可安装 Pandas Profiling 包:
pip install pandas_profiling
乍一看,经验丰富的数据分析师可能会嘲笑这是华而不实的,但是,它可以帮助你快速获得你拥有的数据概况:

看到了吗,正如我所说,1 行代码搞定!
你看到的第一部分内容是“概览”(请看上图),这部分内容会呈现给你一些非常高级的数据和变量统计,以及像变量高相关性和高偏态性等这类警告。
但是它提供的信息远远不止这些。往下滑动,我们会发现这份输出报告包含多个部分。仅用图片显示这个 1 行代码的输出都是不大合适的,所以我制作了一张 GIF 图:

我强烈建议你自己来探索这个软件包里的特色——毕竟,这只有 1 行代码,而且你会在以后的数据分析中发现这个软件包真的很好用。
import pandas as pd
import pandas_profiling
pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/planets.csv').profile_report()
更多类似的代码库
如果你喜欢使用这些易用的东西来改进你的 Python 工作流,可以看看我的一些最新文章。
最后的思考
这篇文章真的很短小。我自己才刚刚发现 Pandas Profiling 这个库,觉得可以拿来分享!
原文链接:Exploring your data with just 1 line of Python

时间:2019-11-30 01:13 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















