如何只用一行代码让Pandas加速四倍?
Pandas 虽然是 Python 中用于数据处理的库,但它不是为高性能数据处理而打造的。本文将带你了解最近新推出的代码库 Modin,它是专为 Pandas 分布式计算而开发的,能够加速处理数据。
Pandas 是 Python 中处理数据的首选库,它使用起来很容易,非常灵活,能够处理不同类型和大小的数据,而且它有大量的函数,这让操作数据简直是小菜一碟。
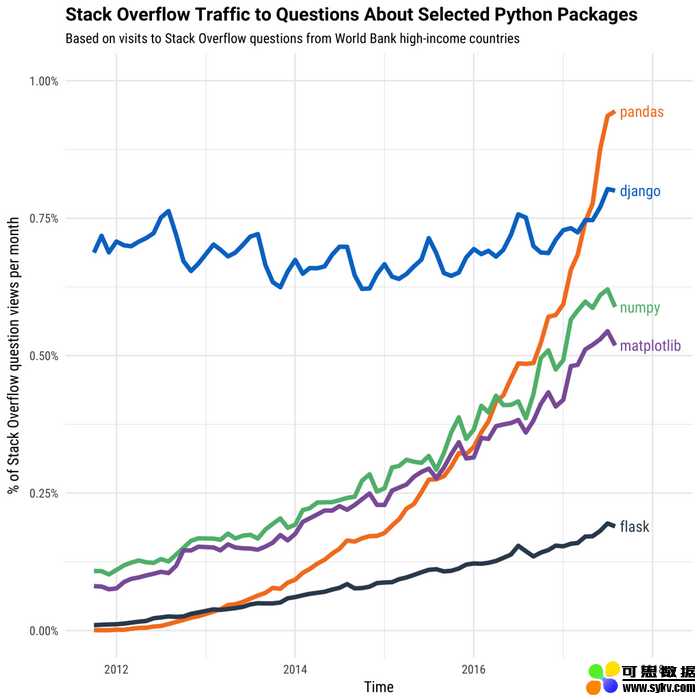
历年来 Python 开发包的受欢迎程度。来源: https://stackoverflow.blog/2017/09/14/python-growing-quickly/
Pandas 默认是在单个 CPU 核上,采用单进程执行函数,这在小数据集上运行得很好,因为你可能觉察不到太多性能上的差异。但是,对于较大数据集,需要做更多的计算,这时如果还只使用单个 CPU 核,就会开始感觉到性能受到影响了。对于具有百万行甚至数十亿行的数据集,Pandas 每次只计算一个数。
但是,大多数用于数据科学的现代化机器都至少有 2 个 CPU 核,这意味着,在有 2 个 CPU 核的机器上,使用 Pandas 的默认配置时,至少有 50% 的计算机算力都被闲置了。如果你有 4 个核(现代的 Intel i5)或者 6 个核(现代的 Intel i7),情况那就更糟糕了,因为 Pandas 就不是为有效利用多核算力而设计的。
Modin 是新出的一个库,通过自动化地将计算分布到系统所有可用的 CPU 核上,来加速 Pandas。Modin 宣称,通过这个技术,对于任何大小的 Pandas 数据帧,它都能够获得和系统 CPU 核数几乎成正比的性能增长。
让我们来看下 Modin 都是怎样运行的,然后看几个代码用例。
Modin 是怎样用 Pandas 做并行处理的
在 Pandas 中生成了一个数据帧后,我们的目标是用最快的方式执行一些计算或者处理工作,比如可能是要求解每列的平均数(使用 mean() 函数)、根据groupby字段对数据分组、移除所有重复数据(使用 drop_duplicates() 函数),或者是 Pandas 中其他内建的函数。
在前面一节中,我们提到了 Pandas 只用一个 CPU 核做数据处理的方式。很自然,这成了一个大大的瓶颈,特别是对于较大的数据帧,缺少计算资源会给性能带来较大影响。
理论上讲,并行计算是很容易的,只需要把数据集不同部分的计算应用到每个可用的 CPU 核上。对于 Pandas 的数据帧,基本的想法就是把这个数据帧分成好几块,块数和你机器上的 CPU 核数量相等,让每一个 CPU 核计算其中一块。最后,我们再把计算结果汇总,这个汇总操作计算量并不大。
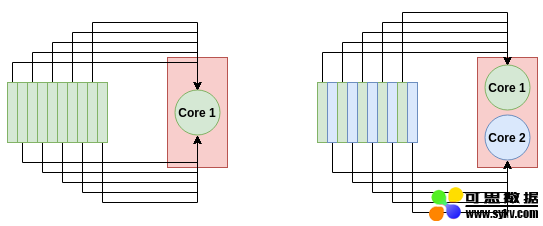
多核系统怎样加速处理数据。左图:单核处理方式,10 个任务都由单个计算节点处理。右图:双核处理方式,每个节点处理 5 个任务,于是处理速度就加倍了。
这正是 Modin 所采用的方式,它把数据帧切割成不同部分,每个部分都会被送到不同的 CPU 核。Modin 会同时从行和列两个维度对数据帧切分。这使得 Modin 的并行处理可以适应任何形状的数据帧。
想象一下这个例子,你有一个数据帧,它有很多列,却只有寥寥几行。一些库只会在行这个维度做切分,在这个例子中并行度就不够了,因为我们的列数大于行数。但是有了 Modin,由于它会在两个维度进行切分,所以不管数据帧是宽的(列数较多)还是长条形的(行数较多),或者两类情况兼具时,其对这些数据帧的并行处理就都很高效了。
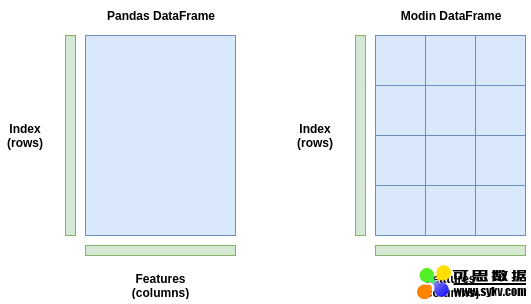
Pandas 数据帧(左图)作为整块存储,且只发送到一个 CPU 核。Modin 数据帧(右图)在行和列方向上被切分成了小块,每块都可以被发送到不同的 CPU 核(可发送到的核数取决于系统中最大核数)。
上图是一个简单示例。Modin 实际上采用了一个分块管理器,它可以基于操作类型来改变分块大小和形状。例如,有个操作需要完整的行或者列。在这个情况下,分块管理器)会以它能发现的最优方式执行切分,并把分块分散发送到 CPU 核上,它是很灵活的。
为了在执行并行处理时完成大量繁重的工作,Modin 可以使用 Dask 或者 Ray 。这两个库都是用 Python API 写的并行计算库,你可以在运行时选择其一与 Modin 一起使用。Ray 是目前为止最安全的,因为它更加稳定——而 Dask 后端还是实验性质的。
说到这里,理论部分已经介绍得足够多啦。让我们来看看代码和性能的基准测试吧!
给 Modin 性能做基准测试
安装和运行 Modin 最简单的方法是通过 pip 来进行。以下命令用来安装 Modin、Ray 以及所有相关依赖。
pip install modin[ray]
本文接下来的例子和基准测试,我们打算使用来自 Kaggle 的 CS:GO Competitive Matchmaking Data 数据集。CSV 文件中的每一行都包含了 CS:GO 比赛中的一轮数据。
我们从现在起都只使用上面数据集里最大的 CSV 文件来做实验(一共有好几个 CSV 文件),该文件名为 esea_master_dmg_demos.part1.csv,大小为 1.2GB。用这么大的文件进行实验,我们应该可以看到 Pandas 是怎样拖慢速度的,Modin 又是怎样帮我们解决这个问题的。测试环境,我会使用一个 i7-8700k CPU ,它有 6 个物理核和 12 个线程。
我们要做的第一个测试就是简单地用 read_csv() 函数读取数据。使用 Pandas 或者 Modin 实现这个功能的代码是完全一样的。
### Read in the data with Pandas
import pandas as pd
s = time.time()
df = pd.read_csv("esea_master_dmg_demos.part1.csv")
e = time.time()
print("Pandas Loading Time = {}".format(e-s))
### Read in the data with Modin
import modin.pandas as pd
s = time.time()
df = pd.read_csv("esea_master_dmg_demos.part1.csv")
e = time.time()
print("Modin Loading Time = {}".format(e-s))
为了测试速度,我导入了 time 这个模块,在 read_csv() 函数前后调用了 time.time()。结果,Pandas 花了 8.38 秒从 CSV 文件中载入数据到内存,而 Modin 仅花了 3.22 秒,Modin 实现了 2.6 倍的加速。只要修改导入库名称就可以实现这样的加速,不要太爽了!
让我们在数据帧上做一些计算量大的操作看下。将几个数据帧连接起来是 Pandas 中的一个常用操作——我们的数据可能包含在几个或者更多的 CSV 文件中,我们不得不一次读入一个文件,再进行数据帧连接。我们在 Pandas 和 Modin 中只需调用 pd.concat() 函数就可以很容易做到这点。
我们预期 Modin 对这类操作将会运行得很好,因为它能够处理大量的数据。代码如下所示:
import pandas as pd
df = pd.read_csv("esea_master_dmg_demos.part1.csv")
s = time.time()
df = pd.concat([df for _ in range(5)])
e = time.time()
print("Pandas Concat Time = {}".format(e-s))
import modin.pandas as pd
df = pd.read_csv("esea_master_dmg_demos.part1.csv")
s = time.time()
df = pd.concat([df for _ in range(5)])
e = time.time()
print("Modin Concat Time = {}".format(e-s))
以上代码中,我们将一个数据帧复制了 5 次进行连接。Pandas 可以在 3.56 秒内完成这个连接操作,而 Modin 只花了 0.041 秒,Modin 实现了 86.83 倍的加速!看起来即使我们只有 6 个 CPU 核,数据帧的分块对加速也起了很大的作用。
Pandas 中经常使用的数据帧清理函数是.fillna() 函数。这个函数搜索数据帧中值为 NaN 的元素,将其值替换为你指定的值,这其中有大量的操作。Pandas 不得不遍历每一行每一列来找到 NaN 值然后替换它们。这里使用 Modin 来操作就再适合不过了,因为我们这里是对一个简单操作重复很多次。
import pandas as pd
df = pd.read_csv("esea_master_dmg_demos.part1.csv")
s = time.time()
df = df.fillna(value=0)
e = time.time()
print("Pandas Concat Time = {}".format(e-s))
import modin.pandas as pd
df = pd.read_csv("esea_master_dmg_demos.part1.csv")
s = time.time()
df = df.fillna(value=0)
e = time.time()
print("Modin Concat Time = {}".format(e-s))
这次,Pandas 运行.fillna() 用了 1.8 秒,而 Modin 仅用了 0.21 秒,实现了 8.57 倍的加速!
预警以及最后的基准测试
但是 Modin 总是这么快吗?
嗯,其实并不总是这么快。
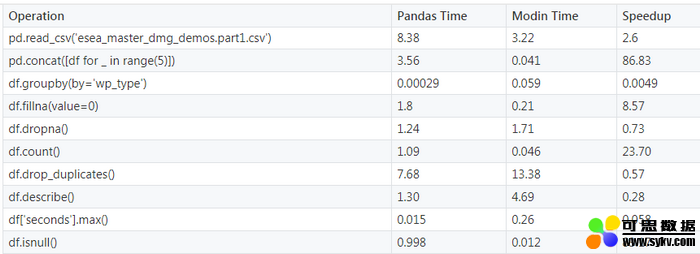
有些情况下,Pandas 实际上会比 Modin 运行得更快,即使在这个有着 5,992,097(几乎 600 万)行的大数据集上。下面表格展示了 Pandas 和 Modin 在一些实验上的运行时间。
你可以看到,有些操作,Modin 明显更快,通常是读取数据和查找数据。其他操作,比如进行统计计算,Pandas 会快很多。
对 Modin 的操作建议
Modin 还是一个非常新的库,开发和扩展都在不断进行中。所以,不是所有的 Pandas 函数都得到了完全加速。如果你使用了 Modin 中还没有加速的函数,它会默认使用 Pandas 函数版本,所以这样就不会产生任何 bug 或者错误。想查看 Modin 中支持的 Pandas 函数加速的完整列表,请浏览该页面。
默认情况下,Modin 会使用你的机器上所有可用的 CPU 核。可能有些情况下,你希望限制 Modin 使用的 CPU 核数量,特别是当你还想在别的地方使用这些核的算力的时候。我们可以通过 Ray 模块中的初始化设置来限制 Modin 能使用的 CPU 核数量,因为 Modin 会在后台使用 Ray 配置。
import ray
ray.init(num_cpus=4)
import modin.pandas as pd
当处理大数据时,通常情况下,数据集的大小不会超出系统内存(RAM)的大小。但是,Modin 还有一个特别的标记,通过把这个标记设置为 true,我们可以启动核外(out of core)模式。核外模式是指当内存不够用时,Modin 会使用硬盘空间,这样就使你可以处理比内存大小更大的数据集。我们设置如下的环境变量来开启这个功能:
export MODIN_OUT_OF_CORE=true
结论
好了,你已经掌握了 Modin 模块!这是一篇 Modin 加速 Pandas 函数的使用指南。只需要修改 import 导入语句即可实现加速。希望至少在某些情况下,你会发现 Modin 对加速 Pandas 函数有所帮助。
原文链接:
https://www.kdnuggets.com/2019/11/speed-up-pandas-4x.html

时间:2019-11-30 01:13 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















