Apache Spark 3.0 预览版正式发布,多项重大功能发布
作者:过往记忆
11 月 08 日 Databricks 的专家给社区发了一封邮件,宣布 Apache Spark 3.0 预览版正式发布,这个版本主要是为了对即将发布的 Apache Spark 3.0 版本进行大规模社区测试。无论是从 API 还是从功能上来说,这个预览版都不是一个稳定的版本,它的主要目的是为了让社区提前尝试 Apache Spark 3.0 的新特性。
如果大家想测试这个版本,可以到这里下载。 https://archive.apache.org/dist/spark/spark-3.0.0-preview/

Apache Spark 3.0 增加了很多令人兴奋的新特性,包括动态分区修剪(Dynamic Partition Pruning)、自适应查询执行(Adaptive Query Execution)、加速器感知调度(Accelerator-aware Scheduling)、支持 Catalog 的数据源 API(Data Source API with Catalog Supports)、SparkR 中的向量化(Vectorization in SparkR)、支持 Hadoop 3/JDK 11/Scala 2.12 等等。Spark 3.0.0-preview 中主要特性和变化的完整列表请参阅这里。下面我将带领大家解析一些比较重要的新特性。

PS:仔细同学可以看出,Spark 3.0 好像没多少 Streaming/Structed Streaming 相关的 ISSUE,这可能有几个原因:
目前基于 Batch 模式的 Spark Streaming/Structed Streaming 能够满足企业大部分的需求,真正需要非常实时计算的应用还是很少的,所以 Continuous Processing 模块还处于试验阶段,还不急着毕业;
数砖(Databricks) 应该在大量投人开发 Delta Lake 相关的东西,这个能够企业带来收入,目前这个才是他们的重点,所以自然开发 Streaming 的投入少了。
动态分区修剪(Dynamic Partition Pruning)
所谓的动态分区裁剪就是基于运行时(run time)推断出来的信息来进一步进行分区裁剪。举个例子,我们有如下的查询:
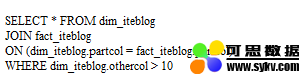
假设 dim_iteblog 表的 dim_iteblog.othercol > 10 过滤出来的数据比较少,但是由于之前版本的 Spark 无法进行动态计算代价,所以可能会导致 fact_iteblog 表扫描出大量无效的数据。有了动态分区裁减,可以在运行的时候过滤掉 fact_iteblog 表无用的数据。经过这个优化,查询扫描的数据大大减少,性能提升了 33 倍。
这个特性对应的 ISSUE 可以参见 SPARK-11150 和 SPARK-28888。具体请参见 一文了解 Apache Spark 3.0 动态分区裁剪(Dynamic Partition Pruning)
自适应查询执行(Adaptive Query Execution)
自适应查询执行(又称 Adaptive Query Optimisation 或者 Adaptive Optimisation)是对查询执行计划的优化,允许 Spark Planner 在运行时执行可选的执行计划,这些计划将基于运行时统计数据进行优化。
早在 2015 年,Spark 社区就提出了自适应执行的基本想法,在 Spark 的 DAGScheduler 中增加了提交单个 map stage 的接口,并且在实现运行时调整 shuffle partition 数量上做了尝试。但目前该实现有一定的局限性,在某些场景下会引入更多的 shuffle,即更多的 stage,对于三表在同一个 stage 中做 join 等情况也无法很好的处理;而且使用当前框架很难灵活地在自适应执行中实现其他功能,例如更改执行计划或在运行时处理倾斜的 join。所以该功能一直处于实验阶段,配置参数也没有在官方文档中提及。这个想法主要来自英特尔以及百度的大牛,具体参见 SPARK-9850,对应的文章可以参见 看完这篇文章还不懂 Spark 的 Adaptive Execution 。
而 Apache Spark 3.0 的 Adaptive Query Execution 是基于 SPARK-9850 的思想而实现的,具体参见 SPARK-23128。SPARK-23128 的目标是实现一个灵活的框架以在 Spark SQL 中执行自适应执行,并支持在运行时更改 reducer 的数量。新的实现解决了前面讨论的所有限制,其他功能(如更改 join 策略和处理倾斜 join)将作为单独的功能实现,并作为插件在后面版本提供。
加速器感知调度(Accelerator-aware Scheduling)
如今大数据和机器学习已经有了很大的结合,在机器学习里面,因为计算迭代的时间可能会很长,开发人员一般会选择使用 GPU、FPGA 或 TPU 来加速计算。在 Apache Hadoop 3.1 版本里面已经开始内置原生支持 GPU 和 FPGA 了。作为通用计算引擎的 Spark 肯定也不甘落后,来自 Databricks、NVIDIA、Google 以及阿里巴巴的工程师们正在为 Apache Spark 添加原生的 GPU 调度支持,该方案填补了 Spark 在 GPU 资源的任务调度方面的空白,有机地融合了大数据处理和 AI 应用,扩展了 Spark 在深度学习、信号处理和各大数据应用的应用场景。这项工作的 issue 可以在 SPARK-24615 里面查看,相关的 SPIP(Spark Project Improvement Proposals) 文档可以参见 SPIP: Accelerator-aware scheduling

目前 Apache Spark 支持的资源管理器 YARN 和 Kubernetes 已经支持了 GPU。为了让 Spark 也支持 GPUs,在技术层面上需要做出两个主要改变:
在 cluster manager 层面上,需要升级 cluster managers 来支持 GPU。并且给用户提供相关 API,使得用户可以控制 GPU 资源的使用和分配。
在 Spark 内部,需要在 scheduler 层面做出修改,使得 scheduler 可以在用户 task 请求中识别 GPU 的需求,然后根据 executor 上的 GPU 供给来完成分配。
因为让 Apache Spark 支持 GPU 是一个比较大的特性,所以项目分为了几个阶段。在 Apache Spark 3.0 版本,将支持在 standalone、 YARN 以及 Kubernetes 资源管理器下支持 GPU,并且对现有正常的作业基本没影响。对于 TPU 的支持、Mesos 资源管理器中 GPU 的支持、以及 Windows 平台的 GPU 支持将不是这个版本的目标。而且对于一张 GPU 卡内的细粒度调度也不会在这个版本支持;Apache Spark 3.0 版本将把一张 GPU 卡和其内存作为不可分割的单元。详情请参见 过往记忆大数据公众号的 Apache Spark 3.0 将内置支持 GPU 调度 文章。
Apache Spark DataSource V2
Data Source API 定义如何从存储系统进行读写的相关 API 接口,比如 Hadoop 的 InputFormat/OutputFormat,Hive 的 Serde 等。这些 API 非常适合用户在 Spark 中使用 RDD 编程的时候使用。使用这些 API 进行编程虽然能够解决我们的问题,但是对用户来说使用成本还是挺高的,而且 Spark 也不能对其进行优化。为了解决这些问题,Spark 1.3 版本开始引入了 Data Source API V1,通过这个 API 我们可以很方便的读取各种来源的数据,而且 Spark 使用 SQL 组件的一些优化引擎对数据源的读取进行优化,比如列裁剪、过滤下推等等。
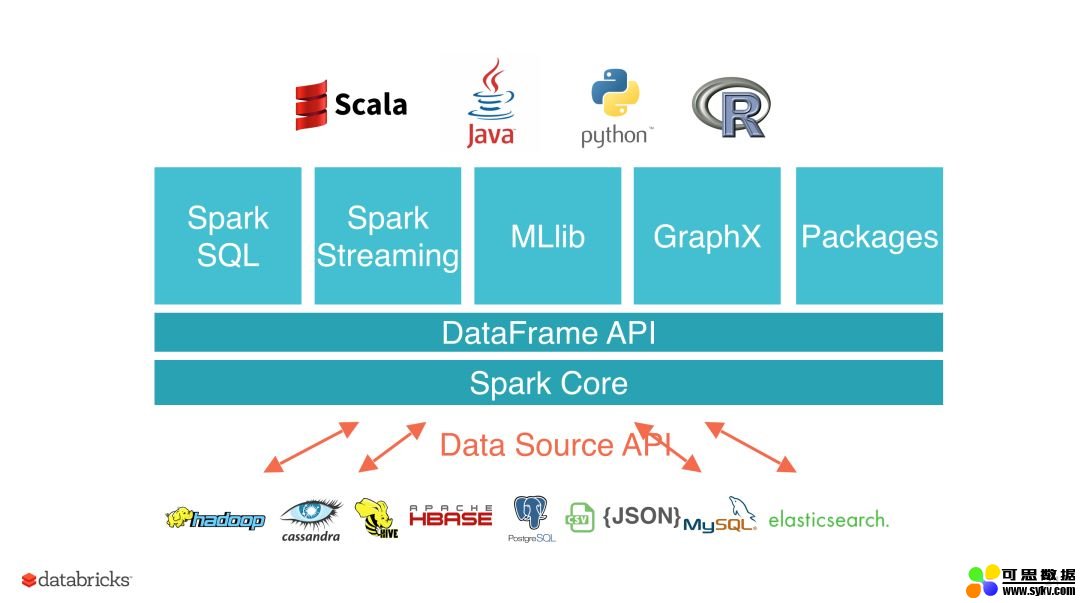
Data Source API V1 为我们抽象了一系列的接口,使用这些接口可以实现大部分的场景。但是随着使用的用户增多,逐渐显现出一些问题:
部分接口依赖 SQLContext 和 DataFrame
扩展能力有限,难以下推其他算子
缺乏对列式存储读取的支持
缺乏分区和排序信息
写操作不支持事务
不支持流处理
为了解决 Data Source V1 的一些问题,从 Apache Spark 2.3.0 版本开始,社区引入了 Data Source API V2,在保留原有的功能之外,还解决了 Data Source API V1 存在的一些问题,比如不再依赖上层 API,扩展能力增强。Data Source API V2 对应的 ISSUE 可以参见 SPARK-15689。虽然这个功能在 Apache Spark 2.x 版本就出现了,但是不是很稳定,所以社区对 Spark DataSource API V2 的稳定性工作以及新功能分别开了两个 ISSUE:SPARK-25186 以及 SPARK-22386。Spark DataSource API V2 最终稳定版以及新功能将会随着年底和 Apache Spark 3.0.0 版本一起发布,其也算是 Apache Spark 3.0.0 版本的一大新功能。
更多关于 Apache Spark DataSource V2 的详细介绍请参见公众号文章: 一文理解 Apache Spark DataSource V2 诞生背景及入门实战 。
更好的 ANSI SQL 兼容
PostgreSQL 是最先进的开源数据库之一,其支持 SQL:2011 的大部分主要特性,完全符合 SQL:2011 要求的 179 个功能中,PostgreSQL 至少符合 160 个。Spark 社区目前专门开了一个 ISSUE SPARK-27764 来解决 Spark SQL 和 PostgreSQL 之间的差异,包括功能特性补齐、Bug 修改等。功能补齐包括了支持 ANSI SQL 的一些函数、区分 SQL 保留关键字以及内置函数等。这个 ISSUE 下面对应了 231 个子 ISSUE,如果这部分的 ISSUE 都解决了,那么 Spark SQL 和 PostgreSQL 或者 ANSI SQL:2011 之间的差异更小了。
SparkR 向量化读写
Spark 是从 1.4 版本开始支持 R 语言的,但是那时候 Spark 和 R 进行交互的架构图如下:
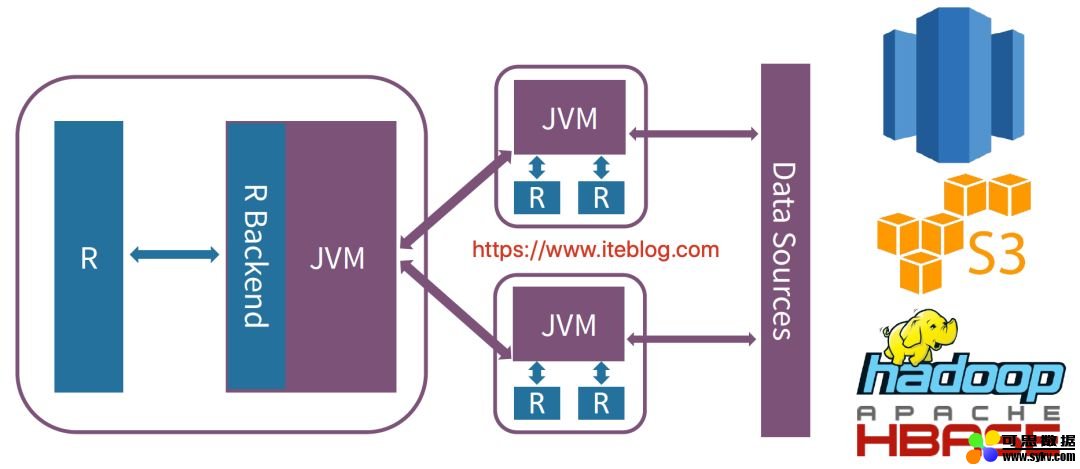
每当我们使用 R 语言和 Spark 集群进行交互,需要经过 JVM ,这也就无法避免数据的序列化和反序列化操作,这在数据量很大的情况下性能是十分低下的!
而且 Apache Spark 已经在许多操作中进行了向量化优化(vectorization optimization),例如,内部列式格式(columnar format)、Parquet/ORC 向量化读取、Pandas UDFs 等。向量化可以大大提高性能。SparkR 向量化允许用户按原样使用现有代码,但是当他们执行 R 本地函数或将 Spark DataFrame 与 R DataFrame 互相转换时,可以将性能提高大约数千倍。这项工作可以看下 SPARK-26759。新的架构如下:
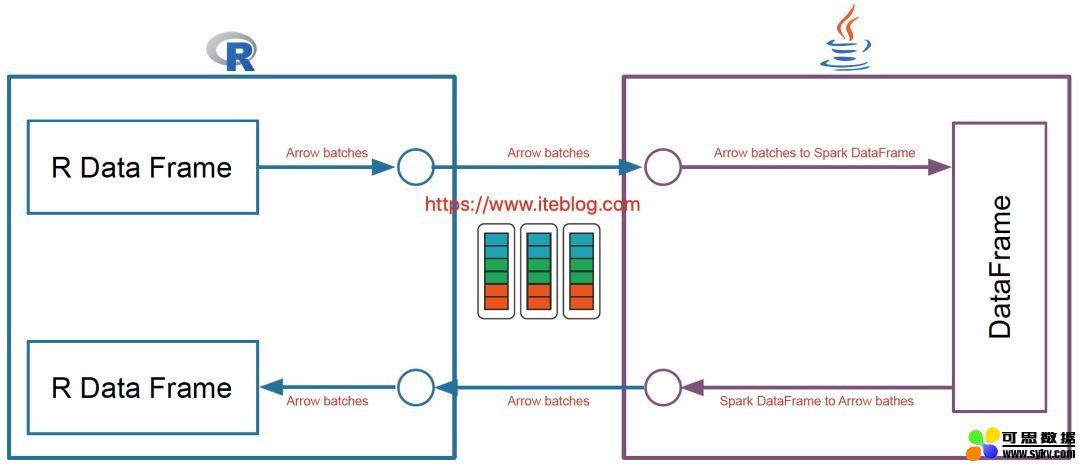
可以看出,SparkR 向量化是利用 Apache Arrow,其使得系统之间数据的交互变得很高效,而且避免了数据的序列化和反序列化的消耗,所以采用了这个之后,SparkR 和 Spark 交互的性能得到极大提升。
其他
Spark on K8S:Spark 对 Kubernetes 的支持是从 2.3 版本开始的,Spark 2.4 得到提升,Spark 3.0 将会加入 Kerberos 以及资源动态分配的支持。
Remote Shuffle Service:当前的 Shuffle 有很多问题,比如弹性差、对 NodeManager 有很大影响,不适应云环境。为了解决上面问题,将会引入 Remote Shuffle Service,具体参见 SPARK-25299
支持 JDK 11:参见 SPARK-24417,之所以直接选择 JDK 11 是因为 JDK 8 即将达到 EOL(end of life),而 JDK9 和 JDK10 已经是 EOL,所以社区就跳过 JDK9 和 JDK10 而直接支持 JDK11。不过 Spark 3.0 预览版默认还是使用 JDK 1.8;
移除对 Scala 2.11 的支持,默认支持 Scala 2.12,具体参见 SPARK-26132
支持 Hadoop 3.2,具体参见 SPARK-23710,Hadoop 3.0 已经发布了 2 年了(Apache Hadoop 3.0.0-beta1 正式发布,下一个版本 (GA) 即可在线上使用),所以支持 Hadoop 3.0 也是自然的,不过 Spark 3.0 预览版默认还是使用 Hadoop 2.7.4。
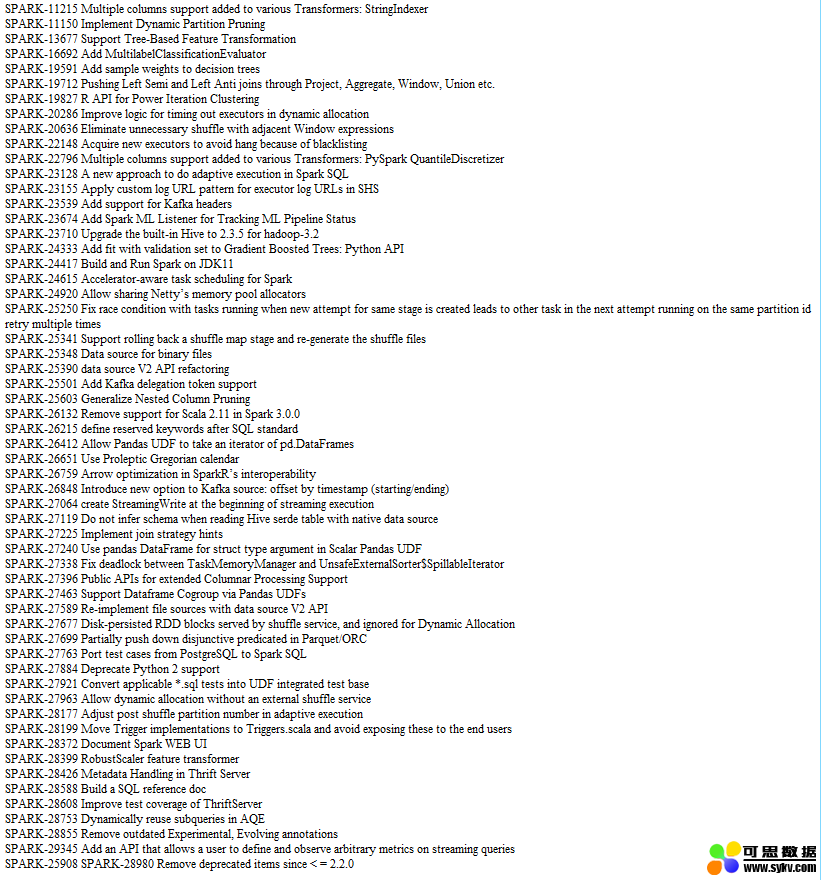
附:Spark 3.0 重要 ISSUE

时间:2019-11-23 18:27 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]Spark 迁移到 K8S 在有赞的实践与经验
- [数据挖掘]Spark Operator 初体验
- [数据挖掘]如何实现Spark on Kubernetes?
- [数据挖掘]Spark SQL 物化视图技术原理与实践
- [数据挖掘]Spark on K8S 的最佳实践和需要注意的坑
- [数据挖掘]Spark 3.0重磅发布!开发近两年,流、Python、SQL重
- [数据挖掘]Spark 3.0开发近两年终于发布,流、Python、SQL重大
- [数据挖掘]Apache Spark 3.0.0 正式版终于发布了,重要特性全面
- [数据挖掘]Spark 3.0 自适应查询优化介绍,在运行时加速 Sp
- [数据挖掘]Flink SQL vs Spark SQL
相关推荐:
网友评论:















