数据挖掘领头人韩家炜教授:如何从无结构文本

这几日,对于许多数据挖掘领域的研究者来说,北京是一个关注的焦点,原因无他,作为数据挖掘领域的两大顶会CIKM 2019和ICDM 2019相继在北京召开,甚至连开会地点(国家会议中心)都没有变化。


两个会议同为CCF B类,其区别在于前者是ACM举办,而后者是IEEE举办;此外CIKM覆盖范围更广,包括了数据库、信息检索和数据挖掘三个领域,而ICDM则更为专注数据挖掘。
在两次会议中,数据挖掘领域的巨擘韩家炜教授将就其研究分别做主题为《From Unstructured Text to TextCube: Automated Construction and Multidimensional Exploration》(@CIKM2019)和《Embedding-Based Text Mining: A Frontier in Data Mining》(@ICDM2019)的报告。
现实世界中的大数据在很大程度上是非结构化的、互联的和动态的,且以自然语言文本的形式出现,将此类庞大的非结构化数据转换为有用的知识是一条必由之路。目前大家普遍采用劳动密集型的方法对数据进行打标签从而提取知识,这种方法短时来看可取,但却无法进行扩展,特别是许多企业的文本数据是高度动态且领域相关。
韩家炜教授认为,大量的文本数据本身就隐含了大量的隐模式、结构和知识,因此我们可以借助domain-independent 和 domain-dependent的知识库,来探索如何将海量数据从非结构化的数据转化为结构化的知识。
如下图所示,是韩家炜教授及其学生在过去以及未来研究的主线:
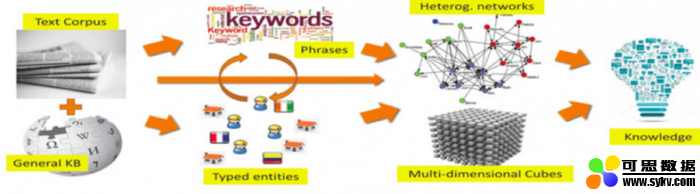
韩家炜认为要想将现有的无结构的大数据变成有用的知识,首先要做的就是将数据结构化。他提出两种结构化数据的形式,一种是异质网络(Heterogeneous Network),另一种是多维文本立方体(Multi-dimensional Text Cube)。由这种结构化数据生成知识已经证明是很强大的,但是如何将原始无结构的数据变成有结构的数据(Network 或 Text Cube)则是非常困难的。
在 Network/Text Cube 到 Knowledge 的问题上,韩家炜等人已经做了很多研究工作,也已经由此获得了很多奖项;在无结构文本数据到有结构 Network/Text Cube 的路上他们也做出了许多尝试和成果,现在仍在进行中。韩家炜认为这是一条很长的路,他们现在只是在这条路上突破了几个可以往前走的口子,还只是一条小路,要变成一条康庄大道则需要各国学者共同努力。
韩家炜教授的研究工作并非跟随热点,而是在十年如一日地去打通一条从无结构数据到有用的知识的康庄大道,因此脉络极为清晰且极具连贯性。
雷锋网 AI 科技评论在2018年初曾整理过一篇韩家炜教授的演讲报告文章《韩家炜在数据挖掘上开辟的「小路」是什么》,值得大家参考。相比一年前,韩家炜教授的团队也在不断将当前最新的研究进展融入到他们这条「小路」当中,例如BERT、Spherical Text Embedding等,这些请查阅韩家炜教授团队近期发表论文:

在2018年初他提到的以下几本已经发表的书:

站在2019年末,韩家炜的团队又发布了几本新书:

任翔出了《Mining Structures of Factual Knowledge from Text》,张超也出版了《Multidimensional Mining of Massive Text Data》 。

时间:2019-11-08 23:39 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















