Python新工具:用三行代码提取PDF表格数据
从 PDF 表格中获取数据是一项痛苦的工作。不久前,一位开发者提供了一个名为 Camelot 的工具,使用三行代码就能从 PDF 文件中提取表格数据。
PDF 文件是一种非常常用的文件格式,通常用于正式的电子版文件。它能够很好的将不同的排版格式固定下来,形成版面清晰且美观的展示效果。然而,对于想要从 PDF 中提取信息的人们来说,PDF 是个噩梦,尤其是表格。
大量的学术报告、论文、分析文章都使用 PDF 展示其中的表格数据,但是对于如果想要直接从表格中复制数据则会非常麻烦。不久前,有一位开发者提供了一个可从文字 PDF 中提取表格信息的工具——Camelot,能够直接将大部分表格转换为 Pandas 的 Dataframe。
项目地址:https://github.com/camelot-dev/camelot
Camelot 是什么
据项目介绍称,Camelot 是一个 Python 工具,用于将 PDF 文件中的表格数据提取出来。
具体而言,用户可以像使用 Pandas 那样打开 PDF 文件,然后利用这个工具提取表格数据,最后再指定输出的形式(如 csv 文件)。
代码示例
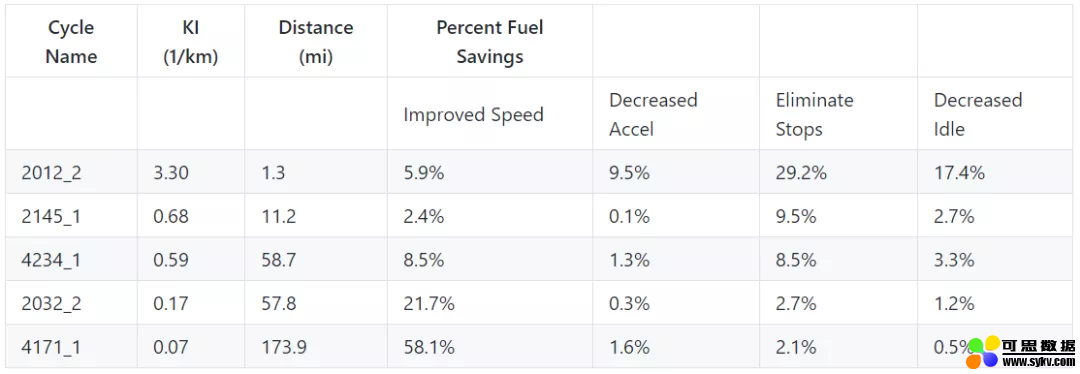
项目提供的 PDF 文件如图所示,假设用户需要提取这些文字之间的表格 2-1 中的信息。
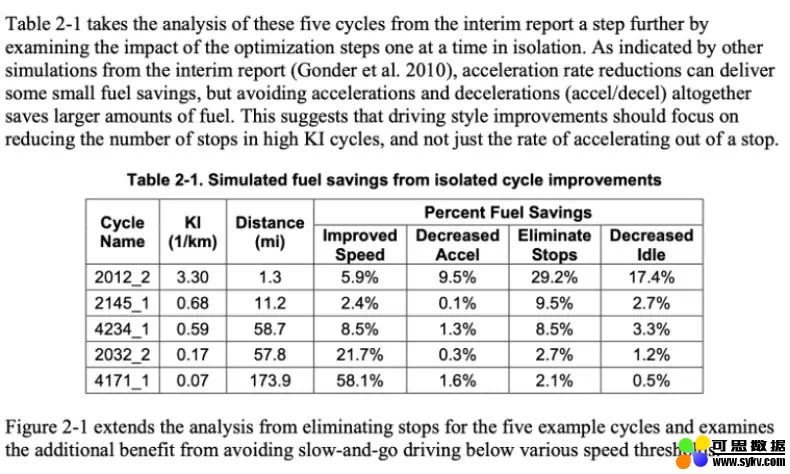
PDF 文件。我们需要提取表格 2-1。
使用 Camelot 提取表格数据的代码如下:
>>> import camelot
>>> tables = camelot.read_pdf('foo.pdf') #类似于Pandas打开CSV文件的形式
>>> tables[0].df # get a pandas DataFrame!
>>> tables.export('foo.csv', f='csv', compress=True) # json, excel, html, sqlite,可指定输出格式
>>> tables[0].to_csv('foo.csv') # to_json, to_excel, to_html, to_sqlite, 导出数据为文件
>>> tables
<TableList n=1>
>>> tables[0]
<Table shape=(7, 7)> # 获得输出的格式
>>> tables[0].parsing_report
{
'accuracy': 99.02,
'whitespace': 12.24,
'order': 1,
'page': 1
}
以下为输出的结果,对于合并的单元格,Camelot 在抽取后做了空行处理,这是一个稳妥的方法。
安装方法
项目作者提供了三种安装方法。首先,你可以使用 Conda 进行安装,这是最简单的。
conda install -c conda-forge camelot-py
最流行的安装方法是使用 pip 安装。
pip install camelot-py[cv]
还可以从项目中克隆代码,并使用源码安装。
git clone https://www.github.com/camelot-dev/camelot
cd camelot
pip install ".[cv]"

时间:2019-10-15 22:15 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]底层I/O性能大PK:Python/Java被碾压,Rust有望取代
- [数据挖掘]RedMonk语言排行:Python力压Java,Ruby持续下滑
- [数据挖掘]不得了!Python 又爆出重大 Bug~
- [数据挖掘]TIOBE 1 月榜单:Python年度语言四连冠,C 语言再次
- [数据挖掘]TIOBE12月榜单:Java重回第二,Python有望四连冠年度
- [数据挖掘]这个可能打败Python的编程语言,正在征服科学界
- [数据挖掘]2021年编程语言趋势预测:Python和JavaScript仍火热,
- [数据挖掘]Spark 3.0重磅发布!开发近两年,流、Python、SQL重
- [数据挖掘]Python 为什么推荐蛇形命名法?
- [数据挖掘]Python才是世界上最好的语言
相关推荐:
网友评论:















