想提高计算速度?作为数据科学家你应该知道这
每个数据科学项目迟早都会面临一个不可避免的挑战:速度问题。使用更大的数据集会导致处理速度变慢,因此最终必须想办法优化算法的运行时间。正如你们大多数人已经知道的,并行化是这种优化的必要步骤。python 为并行化提供了两个内置库:多处理和线程。在这篇文章中,我们将探讨数据科学家如何在两者之间进行选择,以及在这样做时应注意哪些因素。
并行计算与数据科学
众所周知,数据科学是处理大量数据并从中提取有用见解的科学。通常情况下,我们对数据执行的操作很容易并行化,这意味着不同的处理代理可以一次对数据执行一个操作,最后进行组合以获得完整的结果。
为了更好地解释并行性,让我们拿一个真实世界的例子作为类比。假设你需要打扫你家的三个房间。你可以自己打扫,打扫完一个再打扫另一个,也可以让你的两个兄弟姐妹帮你打扫,每个人打扫一个房间。在后一种方法中,每个人完成整个任务的一部分,从而减少了完成任务所需的总时间。这就是实际中的并行性。
并行处理可以用 python 以两种不同的方式实现:多处理和线程。
多处理与线程:理论
基本上,多处理和线程是实现并行计算的两种方法,分别使用进程和线程作为处理代理。为了理解它们的工作原理,我们必须搞清楚什么是进程和线程。
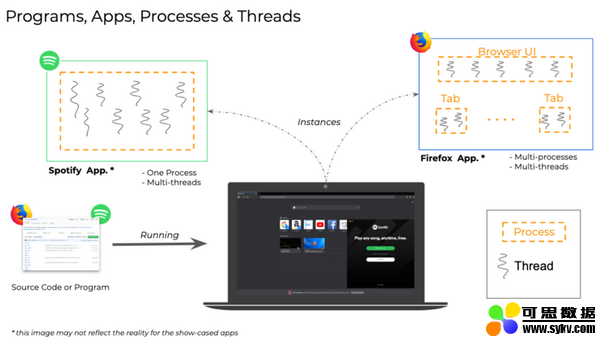
进程
进程是正在执行的计算机程序的实例。每个进程都有自己的内存空间,用来存储正在运行的指令,以及需要存储和访问才能执行的任何数据。
线程
线程是进程的组件,可以并行运行。一个进程中可以有多个线程,它们共享相同的内存空间,即父进程的内存空间。这意味着要执行的代码以及程序中声明的所有变量将由所有线程共享。

例如,让我们回想一下正在你的计算机上运行的程序。你可能正在浏览器中阅读本文,浏览器可能打开了多个选项卡。你也可以同时通过 Spotify 桌面应用程序收听音乐。浏览器和 spotify 应用程序是不同的进程;每个进程都可以使用多个进程或线程来实现并行性。浏览器中的不同选项卡可能在不同的线程中运行。Spotify 可以在一个线程中播放音乐,在另一个线程中从 Internet 下载音乐,并使用第三个线程显示图形用户界面。这称为多线程。对多个进程进行多处理也可以做到这一点。事实上,像 chrome 和 firefox 这样的大多数现代浏览器使用多处理,而不是多线程来处理多个选项卡。
技术细节
一个进程的所有线程都存在于同一个内存空间中,而进程有各自的内存空间。
与进程相比,线程更轻量级,开销更低。生成进程比生成线程慢一点。
在线程之间共享对象更容易,因为它们共享相同的内存空间。为了实现同一个进程间通信,我们必须使用某种 IPC (inter-process communication) 模型,它通常由 OS 提供。
并行计算的陷阱
将并行性引入程序并不总是一个正和博弈,也有一些陷阱需要注意。其中,最重要的是下面的这些问题。
竞争条件:正如我们已经讨论过的,线程有一个共享内存空间,因此它们可以访问共享变量。当多个线程试图同时更改同一个变量时,会出现竞争条件。线程调度程序可以在线程之间任意交换,因此我们无法知道线程尝试更改数据的顺序。这可能会导致两个线程中的任何一个出现不正确的行为,特别是当线程决定基于变量的值执行某些操作时。为了防止这种情况发生,可以在修改变量的代码段周围放置互斥锁,以便一次只能有一个线程写入变量。
饥饿:当一个线程在较长时间内被拒绝访问某个特定的资源时,就会发生饥饿,在这种情况下,整个程序的速度会减慢。这可能是由于线程调度算法设计不当而产生的意外副作用。
死锁:过度使用互斥锁也有一个缺点——它会在程序中引入死锁。死锁是一个线程等待另一个线程释放锁时的状态,但另一个线程需要一个资源来完成第一个线程保持的操作。这样,两个线程都会停止,程序也会停止。死锁可以被认为是饥饿的极端情况。为了避免这种情况,我们必须小心不要引入太多相互依赖的锁。
活锁:活锁是指线程在循环中继续运行,但没有任何进展。这也是由于互斥锁设计不当和使用不当造成的。
python 中的多处理和线程
全局解释器锁
说到 python,有一些奇怪的地方需要记住。我们知道线程共享相同的内存空间,因此必须采取特殊的预防措施,以便两个线程不会写入相同的内存位置。CPython 解释器使用名为 GIL 的机制或全局解释器锁来处理这个问题。
python wiki 上面的资料:
在 CPython 中,全局解释器锁(GIL)是一个互斥锁,它保护对 python 对象的访问过程,防止多个线程同时执行 python 字节码。这个锁是必要的,这主要是因为 CPython 的内存管理不是线程安全的。
了解 python GIL 的详细信息,请查看:https://www.dabeaz.com/python/UnderstandingGIL.pdf 。
GIL 完成了任务,但付出了代价。它在解释器级别上有效地序列化指令。其工作原理如下:任何线程要执行任何函数,都必须获取全局锁。一次只有一个线程可以获取该锁,这意味着解释器最终会以串行方式运行指令。这种设计使得内存管理线程安全,但结果是,它根本不能利用多个 cpu 内核。在单核 cpu 中,这不是什么大问题。但是如果你使用多核 cpu,这个全局锁最终会成为一个瓶颈。
但是,如果你的程序在其他地方(例如在网络、IO 或用户交互中)有更严重的瓶颈,则此瓶颈将变得无关紧要。在这些情况下,线程是一种完全有效的并行化方法。但对于 CPU 受限的程序,线程最终会使程序变慢。让我们通过一些示例用例来探讨这个问题。
线程的使用案例
GUI 程序始终使用线程来使应用程序响应。例如,在文本编辑程序中,一个线程负责记录用户输入,另一个线程负责显示文本,第三个线程负责拼写检查,等等。在这里,程序必须等待用户交互,这是最大的瓶颈。使用多处理不会使程序更快。
线程的另一个用例是 io 绑定或网络绑定的程序,例如 web-scrapers。在这种情况下,多个线程可以同时处理多个网页的刮擦。线程必须从 Internet 下载网页,这将是最大的瓶颈,因此线程是一个完美的解决方案。Web 服务器是受网络约束的,工作原理与此类似;有了它们,多处理就没有线程的优势了。另一个相关的例子是 tensorflow,它使用线程池并行地转换数据。
多处理的使用案例
如果程序是 CPU 密集型的,并且不需要进行任何 IO 或用户交互,那么多处理就比线程更加突出。例如,任何一个只处理数字的程序都可以使用多处理得到极大的加速;事实上,线程可能会减慢它的速度。一个有趣的实际例子是 Pytorch Dataloader,它使用多个子进程将数据加载到 GPU 中。
python 中的并行化
python 为同名的并行化方法提供了两个库——多处理和线程。尽管它们之间有着根本的区别,但这两个库提供了非常相似的 API(从 python 3.7 开始)。让我们来具体看看吧。
import threading
import random
from functools import reduce
def func(number):
random_list = random.sample(range(1000000), number)
return reduce(lambda x, y: x*y, random_list)
number = 50000
thread1 = threading.Thread(target=func, args=(number,))
thread2 = threading.Thread(target=func, args=(number,))
thread1.start()
thread2.start()
thread1.join()
thread2.join()
你可以看到,我创建了一个函数 func,它创建一个随机数列表,然后按顺序将其所有元素相乘。如果物品数量足够大,比如说 5 万或 10 万件,这可能是一个相当繁重的过程。
然后,我创建了两个线程来执行同一个函数。线程对象有一个异步启动线程的 start 方法。如果我们想等待它们终止并返回,我们必须调用 join 方法,这就是我们在上面所做的。
如你所见,在后台将新线程转到任务的 API 非常简单。最棒的是,用于多处理的 API 也几乎完全相同;让我们来检查一下吧~
import multiprocessing
import randomfrom functools
import reduce
def func(number):
random_list = random.sample(range(1000000), number)
return reduce(lambda x, y: x*y, random_list)
number = 50000
process1 = multiprocessing.Process(target=func, args=(number,))
process2 = multiprocessing.Process(target=func, args=(number,))
process1.start()
process2.start()
process1.join()
process2.join()
在这里它只是交换线程。有着多处理的线程。
显然,你可以用它做很多事情,但这不在本文的范围内,所以我们不在这里讨论。如果你有兴趣了解更多信息,请查看这里和这里的文档:https://docs.python.org/3/library/threading.html 和 https://docs.python.org/3/library/threading.html 。
基准点
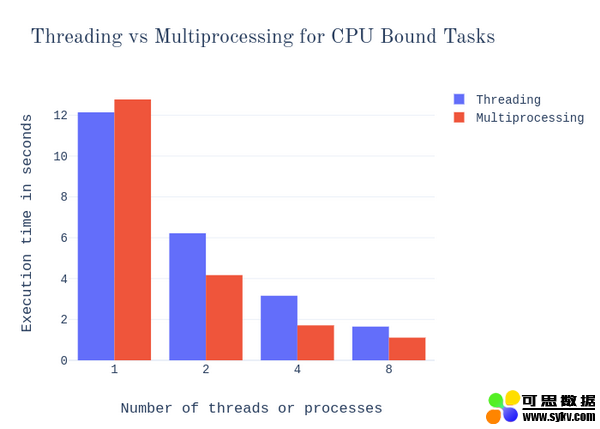
现在我们已经了解了实现并行化的代码是什么样子的,让我们回到性能问题上来。如前所述,线程不适合用于 CPU 限制的任务;在这些情况下,它最终成为一个瓶颈。我们可以使用一些简单的基准来验证这一点。
首先,让我们看看在我上面展示的代码示例中,线程处理与多处理是如何比较的。请记住,此任务不涉及任何类型的 IO,因此它是纯 CPU 绑定的任务。
让我们看看一个 IO 绑定任务的类似基准。例如,以下函数:
import requestsdef func(number):
url = 'http://example.com/'
for i in range(number):
response = requests.get(url)
with open('example.com.txt', 'w') as output:
output.write(response.text)
这个函数只是获取一个网页并将其保存到一个本地文件中,循环多次。无用但直截了当,因此很适合演示。让我们看看基准是什么吧。
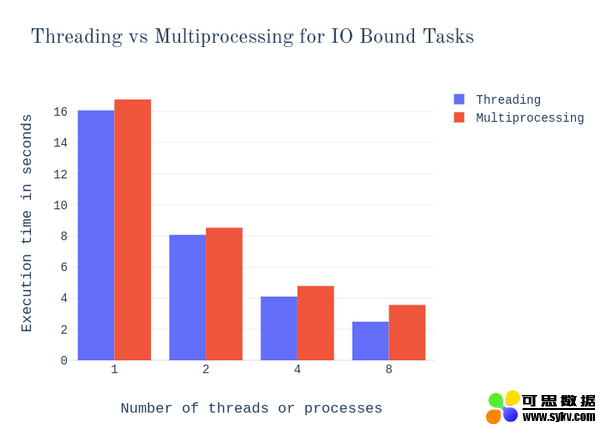
现在,从这两张图表中可以注意到以下几点:
在这两种情况下,单个进程的执行时间都比单个线程长。显然,进程比线程有更多的开销。
对于受 CPU 限制的任务,多个进程的性能比多个线程要好。然而,当我们使用 8x 并行化时,这种差异就变得不那么明显了。由于我的笔记本电脑中的处理器是四核的,因此最多有四个进程可以有效地使用多核。所以当我使用更多的进程时,它的伸缩性就不好。但是,它仍然比线程性能好很多,因为线程根本不能利用多个核。
对于 IO 绑定的任务,瓶颈不是 CPU。因此,GIL 带来的通常限制在这里不适用,多处理也没有优势。不仅如此,线程的轻量级开销实际上使它们比多处理更快,并且线程始终优于多处理。
差异、优缺点
线程在相同的内存空间中运行;进程有单独的内存。
从前面的观点来看:在线程之间共享对象更容易,但与此同时,你必须采取额外的措施来实现对象同步,以确保两个线程不会同时写入同一个对象,并且不会出现争用情况。
由于对象同步增加了编程开销,多线程编程更容易出现错误。另一方面,多进程编程很容易实现。
与进程相比,线程的开销更低;生成进程比线程花费更多的时间。
由于 python 中 GIL 的局限性,线程不能利用多个 CPU 核实现真正的并行。多处理没有任何这样的限制。
进程调度由操作系统处理,而线程调度则由 python 解释器完成。
子进程是可中断和可终止的,而子线程不是。你必须等待线程终止或加入。
从所有这些讨论中,我们可以得出以下结论:
线程应该用于涉及 IO 或用户交互的程序。
多处理应该用于 CPU 受限、计算密集型的程序。
从数据科学家的角度
典型的数据处理管道可分为以下步骤:
读取原始数据并存储到主存储器或 GPU 中;
使用 CPU 或 GPU 进行计算;
将挖掘出的信息存储在数据库或磁盘中。
让我们来探索如何在这些任务中引入并行性,从而加快它们的速度。
步骤 1 包括了从磁盘读取数据,因此很明显磁盘 IO 将成为此步骤的瓶颈。正如我们所讨论的,线程是并行这种操作的最佳选择。同样,步骤 3 也是引入线程的理想候选步骤。
但是,步骤 2 包含涉及 CPU 或 GPU 的计算。如果是基于 CPU 的任务,那么使用线程将毫无用处;相反,我们必须进行多处理。只有这样,我们才能利用 CPU 的多个核并实现并行性。如果这是一个基于 GPU 的任务,因为 GPU 已经在硬件级别实现了一个大规模并行化的体系结构,那么使用正确的接口(库和驱动程序)与 GPU 交互应该可以处理剩下的事情。
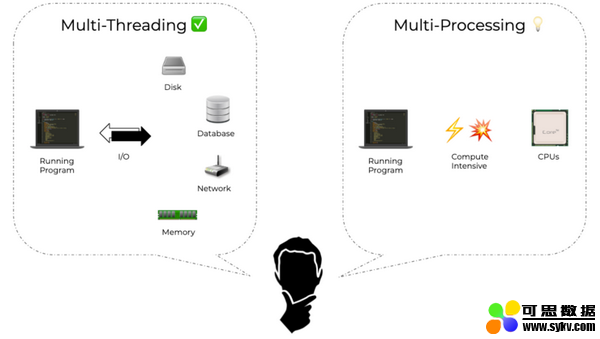
现在你可能会想,「我的数据管道看起来与此有些不同;我有一些任务并不真正适合这个通用框架。」不过,在这里你应该考虑的因素是:
你的任务是否有任何形式的 IO
IO 是否是程序的瓶颈
你的任务是否取决于 CPU 的大量计算
考虑到这些因素,再加上上面的要点,你应该能够做出决定。另外,请记住,你不必在整个程序中使用单一形式的并行,而是应该在程序的不同部分使用不同的并行。
现在我们来看看数据科学家可能面临的两个常见场景,以及如何使用并行计算来加速它们。
场景 1:下载电子邮件
假设你想分析自己创业公司收件箱中的所有电子邮件,并了解其趋势:谁是最频繁的发件人,电子邮件中出现的最常见关键字是什么,一周中的哪一天或一天中的哪一小时收到的电子邮件最多,等等。当然,这个项目的第一步是将电子邮件下载到你的计算机上。
首先,让我们按顺序进行,而不使用任何并行化。下面是要使用的代码,应该非常简单明了。有一个下载电子邮件的功能,它以电子邮件 ID 列表作为输入,并按顺序下载它们。这个函数一次调用 100 个电子邮件的 ID 列表。
import imaplib
import time
IMAP_SERVER = 'imap.gmail.com'
USERNAME = 'username@gmail.com'
PASSWORD = 'password'
def download_emails(ids):
client = imaplib.IMAP4_SSL(IMAP_SERVER)
client.login(USERNAME, PASSWORD)
client.select()
for i in ids:
print(f'Downloading mail id: {i.decode()}')
_, data = client.fetch(i, '(RFC822)')
with open(f'emails/{i.decode()}.eml', 'wb') as f:
f.write(data[0][1])
client.close()
print(f'Downloaded {len(ids)} mails!')
start = time.time()
client = imaplib.IMAP4_SSL(IMAP_SERVER)
client.login(USERNAME, PASSWORD)
client.select()
_, ids = client.search(None, 'ALL')
ids = ids[0].split()
ids = ids[:100]
client.close()
download_emails(ids)
print('Time:', time.time() - start)
所用时间:35.65300488471985 秒。
现在让我们在这个任务中引入一些并行性来加快速度。在开始编写代码之前,我们必须在线程和多处理之间做出决定。正如你目前所了解到的,当任务的瓶颈是 IO 时,线程是最好的选择。这里的任务显然属于这一类,因为它正在通过 Internet 访问 IMAP 服务器。所以我们要开始使用线程了。
我们将要使用的大部分代码将与我们在顺序案例中使用的代码相同。唯一不同的是,我们将把 100 个电子邮件 ID 的列表分成 10 个较小的块,每个块包含 10 个 ID,然后创建 10 个线程,并使用每个线程的不同块调用 download_emails 函数。我正在使用 python 标准库中的 concurrent.futures.threadpoolexecutor 类进行线程处理。
import imaplib
import time
from concurrent.futures import ThreadPoolExecutor
IMAP_SERVER = 'imap.gmail.com'
USERNAME = 'username@gmail.com'
PASSWORD = 'password'
def download_emails(ids):
client = imaplib.IMAP4_SSL(IMAP_SERVER)
client.login(USERNAME, PASSWORD)
client.select()
for i in ids:
print(f'Downloading mail id: {i.decode()}')
_, data = client.fetch(i, '(RFC822)')
with open(f'emails/{i.decode()}.eml', 'wb') as f:
f.write(data[0][1])
client.close()
start = time.time()
client = imaplib.IMAP4_SSL(IMAP_SERVER)
client.login(USERNAME, PASSWORD)
client.select()
_, ids = client.search(None, 'ALL')
ids = ids[0].split()
ids = ids[:100]
client.close()
number_of_chunks = 10
chunk_size = 10
executor = ThreadPoolExecutor(max_workers=number_of_chunks)
futures = []
for i in range(number_of_chunks):
chunk = ids[i*chunk_size:(i+1)*chunk_size]
futures.append(executor.submit(download_emails, chunk))
for future in concurrent.futures.as_completed(futures):
pass
print('Time:', time.time() - start)
所用时间:9.841094255447388 秒。
如你所见,线程大大加快了它的速度。
场景 2:使用 scikit learn 进行分类
假设你有一个分类问题,你想使用一个随机森林分类器。由于这是一种标准的、众所周知的机器学习算法,我们不需要重新发明轮子,而只需使用 RandomForestClassifier 即可。
以下代码用于演示。我使用助手函数 sklearn.datasets.make_classification 创建了一个分类数据集,然后在此基础上训练了一个 RandomForestClassifier。另外,我正在计时代码中完成模型拟合核心工作的部分。
from sklearn.ensemble import RandomForestClassifier
from sklearn import datasets
import time
X, y = datasets.make_classification(n_samples=10000, n_features=50, n_informative=20, n_classes=10)
start = time.time()
model = RandomForestClassifier(n_estimators=500)
model.fit(X, y)
print('Time:', time.time()-start)
任务花费时间:34.17733192443848 秒。
现在我们将研究如何减少该算法的运行时间。我们知道这个算法可以在一定程度上并行化,但是什么样的并行化才是合适的呢?它没有任何 IO 瓶颈,相反,它是一个非常 CPU 密集型的任务。所以多处理是合乎逻辑的选择。
幸运的是,sklearn 已经在这个算法中实现了多处理,我们不必从头开始编写它。正如你在下面的代码中看到的,我们只需要提供一个参数 n_jobs(它应该使用的进程数)来启用多处理。
from sklearn.ensemble import RandomForestClassifier
from sklearn import datasets
import time
X, y = datasets.make_classification(n_samples=10000, n_features=50, n_informative=20, n_classes=10)
start = time.time()
model = RandomForestClassifier(n_estimators=500, n_jobs=4)
model.fit(X, y)
print('Time:', time.time()-start)
所用时间:14.576200723648071 秒。
正如预期的那样,多处理使其速度更快。
结论
大多数(如果不是所有的)数据科学项目将会发现并行计算能大幅提高计算速度。事实上,许多流行的数据科学库已经内置了并行性,你只需启用它即可。因此,在尝试自己实现它之前,请查看正在使用的库的文档,并检查它是否支持并行性。如果没有,本文将帮助你自己实现它。
via:https://blog.floydhub.com/multiprocessing-vs-threading-in-python-what-every-data-scientist-needs-to-know/

时间:2019-09-22 10:16 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















