腾讯万亿级大数据组件 TubeMQ 正式开源
近日,在 ApacheCon 2019 上,腾讯开源管理委员会委员、腾讯开源联盟主席、Apache 软件基金会 Member 堵俊平介绍了腾讯开源路线图,宣布腾讯万亿级分布式消息中间件 TubeMQ 正式对外开源,并计划捐赠给 Apache 基金会。
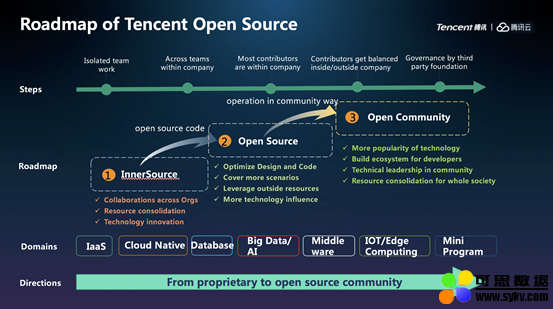
▲ 腾讯开源路线图
TubeMQ 的原型是腾讯数据平台部在2013年自研的分布式消息中间件系统(MQ),专注于大数据场景下海量数据的高性能存储和传输,长期服务微信支付、腾讯视频、广点通等产品。
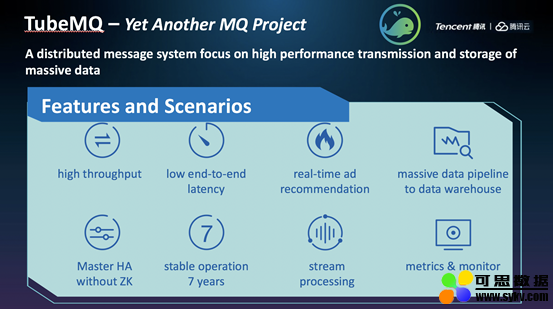
▲ TubeMQ 项目介绍
TubeMQ 主要特性:
纯 Java 语言实现
引入 Master 协调节点:相比 Kafka 依赖于 Zookeeper 完成元数据的管理和实现 HA 保障不同,TubeMQ 系统采用的是自管理的元数据仲裁机制方式进行,Master 节点通过采用内嵌数据库 BDB 完成集群内元数据的存储、更新以及 HA 热切功能,负责 TubeMQ 集群的运行管控和配置管理操作,对外提供接口等;通过 Master 节点,TubeMQ 集群里的 Broker 配置设置、变更及查询实现了完整的自动化闭环管理,减轻了系统维护的复杂度
服务器侧消费负载均衡:TubeMQ 采用的是服务侧负载均衡的方案,而不是客户端侧操作,提升系统的管控能力同时简化客户端实现,更便于均衡算法升级
系统行级锁操作:对于 Broker 消息读写中存在中间状态的并发操作采用行级锁,避免重复问题
Offset 管理调整:Offset 由各个 Broker 独自管理,ZK 只作数据持久化存储用(最初考虑完全去掉ZK依赖,考虑到后续的功能扩展就暂时保留)
消息读取机制的改进:TubeMQ 采用的是消息随机读取模式,同时为了降低消息时延又增加了内存缓存读写,对于带 SSD 设备的机器,增加消息滞后转 SSD 消费的处理,解决消费严重滞后时吞吐量下降以及 SSD 磁盘容量小、刷盘次数有限的问题,使其满足业务快速生产消费的需求
消费者行为管控:支持通过策略实时动态地控制系统接入的消费者行为,包括系统负载高时对特定业务的限流、暂停消费,动态调整数据拉取的频率等;
服务分级管控:针对系统运维、业务特点、机器负载状态的不同需求,系统支持运维通过策略来动态控制不同消费者的消费行为,比如是否有权限消费、消费时延分级保证、消费限流控制,以及数据拉取频率控制等
系统安全管控:根据业务不同的数据服务需要,以及系统运维安全的考虑,TubeMQ 系统增加了 TLS 传输层加密管道,生产和消费服务的认证、授权,以及针对分布式访问控制的访问令牌管理,满足业务和系统运维在系统安全方面的需求
资源利用率提升改进:相比于 Kafka,TubeMQ 采用连接复用模式,减少连接资源消耗;通过逻辑分区构造,减少系统对文件句柄数的占用,通过服务器端过滤模式,减少网络带宽资源使用率;通过剥离对 Zookeeper 的使用,减少 Zookeeper 的强依赖及瓶颈限制
客户端改进:基于业务使用上的便利性以,我们简化了客户端逻辑,使其做到最小的功能集合,我们采用基于响应消息的接收质量统计算法来自动剔出坏的 Broker 节点,基于首次使用时作连接尝试来避免大数据量发送时发送受阻
堵俊平介绍,腾讯每天要处理规模惊人的数据。为支持海量业务,腾讯组建了包含存储层、数据管理层及分析层 3 层结构的数据湖协同方案,向下管理多种数据引擎,向上支撑多种数据应用需求。TubeMQ 就是来源于腾讯数据湖存储层的消息中间件系统,支撑着海量数据的流入和运转。经过近7年、万亿规模的海量数据沉淀,TubeMQ 目前日均接入量超过 25 万亿条消息。
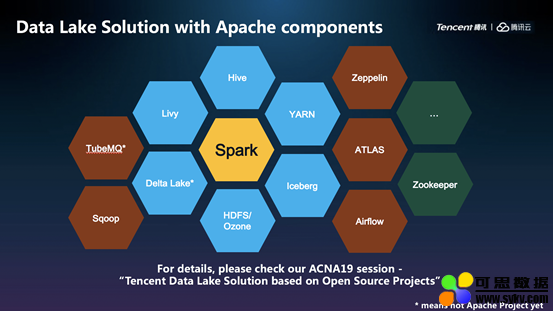
▲ 腾讯数据湖方案,其绝大多数组件由 Apache 的开源项目组成
堵俊平介绍到,腾讯计划将 TubeMQ 捐赠给 Apache 基金会,目前已经启动了相关的孵化流程。

时间:2019-09-22 10:09 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















