从一个浪潮案例看海量数据的分级保护应用
导读:移动互联时代,企业都面临着海量数据带来的挑战,有一些企业驯服了海量数据,实现了“存的下、算的出”,但即使如此,这些企业很少跨过数据保护的门槛,因为传统数据保护技术在面对PB级别数据量时,都或多或少的出现了问题,浪潮工程师开发了分级保护方案,很好的满足了100PB级别的数据保护需求。
PB数据量挑战传统数据保护技术
提到数据保护和容灾,很多人都会想到备份技术、存储复制技术、数据卷复制技术、数据库日志传输等,但是这些传统技术没法适应海量数据环境。数PB乃至数十PB规模的数据,是传统数据保护技术和容灾技术在设计和形成之初,所不能想象的。这些技术适用于百TB以下数据规模,大多数不能做到实时保护,容灾数据日常处于离线或不可访问状态,难以满足的应用需求。
勉强部署这些技术在海量数据环境下,灾难恢复、可用性、稳定性等技术表现也会大打折扣。拿传统备份技术来说,日常演练/验证,数据需要重新加载,PB级数据环境下,加载时间往往是数天、甚至数周,若容灾数据不能进行有效的日常验证,整个容灾架构的可靠性和实用性会急剧下降,所以在很多场景中,传统方案仅限于方案,不能实际部署。
数据分级解决大数据容灾问题
OpenStack、Hadoop、Spark等目前主流的云和大数据平台,数据可靠性主要通过存储子系统的副本和纠删码等技术来保证,这些技术只能保证本地数据安全可靠,没法应对人为破坏、物理/逻辑故障、站点故障等情况,需要增加历史数据保护和远距离容灾保护。
大数据平台80%左右都是原始数据,这些数据经过数据清洗、治理形成平台的标准资源库数据,这个环节是一个海量数据结构化的过程,随后,根据上层业务应用需求,由标准资源库快速派生出多个主题库、专题库等,这些数据库就直接对接上层应用了。
海量数据保护需要在深入了解业务模型和数据属性的技术上,对这些数据进行分级保护,根据重要程度等技术指标,执行不同的保护策略,避免了成本高、技术难落地等实际问题。
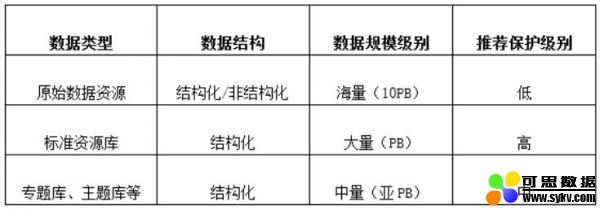
数据分级保护
一个案例——50PB数据的保护
分级仅是海量数据保护的方案框架,具体方案需要针对客户的具体应用场景进行设计,所以我们以刚刚成功上线的一个案例来详细展开。
该用户的数据量属于超大规模级别,在全省有11个大数据分中心,1个大数据总中心,各个中心采集自己区域的原始数据,生成本地的标准资源库,然后根据各自需求生成本地的主题库、专题库等,承接本地上层的应用;同时,各分中心传输本地的标准资源库至总中心,汇聚为全省的标准资源库,生成相关主题库、专题库,具备承接全省范围内业务需求的能力,12个中心数据总量接近50PB。
数据分析——50PB数据保护1PB即可
用户希望建立有效的容灾机制,防范物理、逻辑、站点等故障。根据上文所述的原则,需要先对客户的数据进行分类,根据不同的重要程度采取不同的数据保护技术。
首先是原始数据,这些数据可再生,而且据经过热度访问期后,便成为冷数据,价值低,规模大,不必采用额外的保护技术;其次是,标准资源库数据,这些库数据是大数据平台的初次结果数据,含金量很高,是用户大数据环境的核心数据,不易重建,有很强的数据保护和容灾需求,然后是各类主题库、专题库等数据,这些库数据由标准资源库数据经过二次加工派生出而出,并支持快速重建,发生问题可以在用户要求的RTO(复原时间目标)内完成重建,因而这类数据也不需要额外容灾保护。最后则是各中心间冗余数据,显然这些数据不需要容灾保护
综上,本项目仅需要为总中心的全量标准资源库数据进行容灾保护,数据量约1PB。
应用方案——3条传输通路冗余、计算存储分离
浪潮为用户设计了异地容灾方案,将方案按照客户要求部署在分10中。总中心的全量标准资源库有1PB结构化数据,每日数据变化量为30TB~50TB,所以,异地容灾架构中数据传输技术要支持高频率周期性传输和实时传输模式,将增量数据复制过来,根据生产环境的压力变化两种传输技术可以灵活组合,保证异地容灾大数据平台为在线状态,日常可以实时查询数据、验证数据。所以,容灾数据传输采用ETL定制化工具,这种数据传输技术与大数据平台有着天然的亲和性,高速稳定、成熟可靠,目前,容灾方案可以保证RPO≤1小时,RTO≤2小时。
最后,容灾中心大数据平台,采用计算和存储分离的部署模式,容灾存储采用企业级分布式存储,并和上层大数据平台对接,使方案具备很强的数据湖特性:容灾数据可以灵活的分配给非大数据平台环境,支持容灾数据在不同类型的业务系统间共享,避免数据再次复制过程,最大化数据价值。
以下为容灾方案技术架构图:
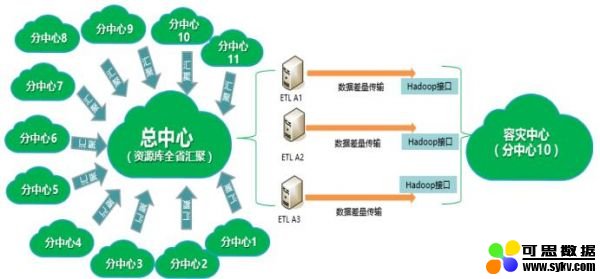
容灾方案技术架构图
本项目在总中心部署3台ETL服务器(后续计划在容灾中心也部署3台,实现ETL服务器的站点互备架构),形成三条逻辑冗余的数据传输通道,从总中心大数据平台抽取标准资源库全量数据至容灾中心,之后进行差量数据复制,容灾中心数据和生产中心数据保持一定的时间差异,可以提升防范逻辑数据故障的能力。
容灾中心,日常主要工作为接收总中心标准资源库数据,并提供数据查询、验证服务、低频运行临时分配的作业任务,根据建设目标,此平台配置和生产中心标准资源库同量存储资源,但不需配置同等的计算资源,所以,本方案采用30台服务器(约为总中心大数据平台计算力的10%)、40台高密存储节点(配置海量数据存储池,提供4PB可用容量,实现未来三年的容量预留)搭建大数据容灾平台。30台服务器包括1台管理节点、2台主服务节点以及27台数据节点,平台服务组件采用高可靠主备模式,防止单节点故障问题。海量存储池采用纠删数据冗余机制,保证可靠性和空间利用率,海量存储池,被上层大数据平台管理,随着容灾数据的快速增长,可以实现在不扩容平台计算资源的条件下,在线扩展其容量至数百PB,满足用户后期数据的快速增长需求。
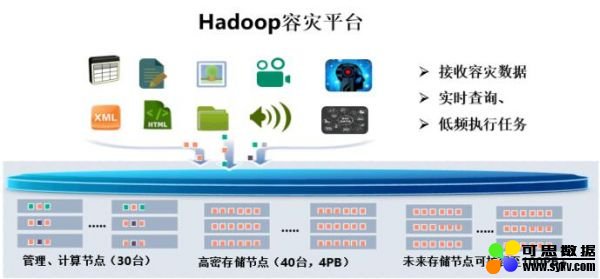
Hadoop容灾平台
结语,海量数据将是企业新常态
目前全球数据量约为44ZB,到2025年会上升至163ZB,也就是说,数据的高速增长将成为越来越多的企业面临的常态化问题,而不是新挑战。在可见的时间内,网络等方面的技术条件都不足以使得企业进行全面不加取舍的数据保护,分级保护将成为越来越多用户的选择,希望这个案例能够给更多的企业用户提供良好的借鉴范例。

时间:2019-09-17 22:45 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















