10 个不为人知的 SQL 技巧

从早期开始,编程语言设计者就有这样的愿望:设计一种语言,在这种语言中,告诉机器我们想要的结果是什么(WHAT),而不是如何(HOW)获得结果。SQL 可以做到这点。在 SQL 中,我们不关心数据库是如何检索信息的,就可以得到结果。本文介绍了使用声明式 SQL10 个不为人知的技巧。
介绍
为了理解这 10 个 SQL 技巧的价值,首先需要了解下 SQL 语言的上下文。为什么我要在 Java 会议上讨论 SQL 呢?(我可能是唯一一个在 Java 会议上讨论 SQL 的了)下面讲下为什么:

从早期开始,编程语言设计者就有这种的愿望:设计一种语言,在这种语言中,告诉机器我们想要的结果是什么(WHAT),而不是如何(HOW)获得结果。例如,在 SQL 中,我们告诉计算机我们要“连接”(联接)用户表和地址表,并查找居住在瑞士的用户。我们不关心数据库将如何检索这些信息(比如,是先加载用户表呢,还是先加载地址表?这两个表是在嵌套循环中联接呢,还是使用 hashmap 联接?是先将所有数据加载到内存中,然后再过滤出瑞士用户呢,还是先加载瑞士地址?等等。)
与每个抽象一样,我们仍然需要了解数据库背后的基本原理,以帮助数据库在查询时做出正确的决策。例如,做如下事情是有必要:
在表之间建立合适的外键(这能告诉数据库每个地址都有一个对应的用户)
在搜索字段上添加索引:国家(这能告诉数据库可以在 O(log N) 而不是 O(N) 的复杂度内查找到特定的国家 )。
但是,一旦数据库和应用程序变得成熟之后,我们就可以把所有重要的元数据放在适当的位置上了,并且只需专注于业务逻辑即可。下面的 10 个技巧展示了,仅用几行声明式 SQL 就能编写强大惊人功能的能力,它不仅可以生成简单的输出,也可以生成复杂的输出。
1. 一切都是表
这是一条最微不足道的技巧,甚至不能说是真正的技巧,但它是全面理解 SQL 的基础:一切都是表:当我们看到这样的 SQL 语句时:
SELECT *
FROM person
……我们很快就能在 FROM 子句中找到 person 表。很好,那是一张表。但我们能意识到整个语句也是一张表吗?例如,我们可以这样写:
SELECT *
FROM (
SELECT *
FROM person
) t
现在,我们已经创建了一张所谓的“派生表”,即 FROM 子句中的嵌套 SELECT 语句。
这是微不足道的,但是如果仔细想想,它是相当优雅的。我们还可以在某些数据库(比如 PostgreSQL、SQL Server)中使用 VALUES() 构造函数来创建临时内存表:
SELECT *
FROM (
VALUES(1),(2),(3)
) t(a)
临时表就这样产生了:
a
—
1
2
3
如果对应的数据库不支持该子句,则可以回到使用派生表上,比如,在 Oracle 中:
SELECT *
FROM (
SELECT 1 AS a FROM DUAL UNION ALL
SELECT 2 AS a FROM DUAL UNION ALL
SELECT 3 AS a FROM DUAL
) t
既然我们已经看到了 VALUES() 和派生表实际上是相同的,那么从概念上,我们回顾一下 INSERT 语句,它有两种类型:
-- SQL Server, PostgreSQL, some others:
INSERT INTO my_table(a)
VALUES(1),(2),(3);
-- Oracle, many others:
INSERT INTO my_table(a)
SELECT 1 AS a FROM DUAL UNION ALL
SELECT 2 AS a FROM DUAL UNION ALL
SELECT 3 AS a FROM DUAL
在 SQL 中,一切都是表。当您在表中插入行时,实际上并不是插入单独的行。是插入整张表。在大多数情况下,大部分人只是碰巧插入了一张单行表,因此没有意识到 INSERT 真正做了什么。
一切都是表。在 PostgreSQL 中,甚至函数都是表:
SELECT *
FROM substring('abcde', 2, 3)
上面语句的结果是:
substring
———
bcd
如果你正在使用 Java 编程,那么可以使用 Java 8 Stream API 来做进一步的类比。考虑如下等价概念:
TABLE : Stream<Tuple<..>>
SELECT : map()
DISTINCT : distinct()
JOIN : flatMap()
WHERE / HAVING : filter()
GROUP BY : collect()
ORDER BY : sorted()
UNION ALL : concat()
在 Java 8 中,“一切都是流”(至少在你开始使用流时是这样)。无论如何转换流,例如,使用 map() 或 filter() 转换,结果类型始终都是流。
我们写了一篇完整的文章来更深入地解释这一点,并将 Stream API 与 SQL 进行了对比: Common SQL C lauses and Their Equivalents in Java 8 Streams
如果你正在寻找“更好的流”(即,具有更多 SQL 语义的流),请查看 jOOλ,它一个将 SQL 窗口函数引入到 Java 中的开源库。
2. 使用递归 SQL 生成数据
公共表表达式(Common Table Expressions ,CTE,在 Oracle 中也叫做子查询分解),它是在 SQL 中声明变量的唯一方法(除了模糊 WINDOW 子句之外,WINDOW 子句也只有在 PostgreSQL 和 Sybase SQL 中可用)。
这是一个功能强大的概念。非常强大。考虑如下声明:
-- 表变量
WITH
t1(v1, v2) AS (SELECT 1, 2),
t2(w1, w2) AS (
SELECT v1 * 2, v2 * 2
FROM t1
)
SELECT *
FROM t1, t2
它的结果是:
v1 v2 w1 w2
-----------------
1 2 2 4
使用简单的 WITH 子句,我们可以指定一系列表变量(请记住:一切都是表),这些变量甚至可以是相互依赖的。
这很容易理解。它已经使得 CTE(Common Table Expressions)非常有用了,但是,真正了不起的是,它们还允许递归!考虑如下 PostgreSQL 示例:
WITH RECURSIVE t(v) AS (
SELECT 1 -- 种子行
UNION ALL
SELECT v + 1 -- 递归
FROM t
)
SELECT v
FROM t
LIMIT 5
它的结果是:
v
—
1
2
3
4
5
它是如何工作的呢?一旦你看懂了一些关键词,它就相对容易了。我们定义了一个公共表表达式,它恰好有两个 UNION ALL 子查询。
第一个 UNION ALL 子查询是我们通常所说的“种子行”。它“播种”(初始化)递归。它可以生成一行或多行,稍后我们将在这些行上递归。记住:一切都是表,所以递归将发生在整张表上,而不是单个行 / 值上。
第二个 UNION ALL 子查询在发生递归的地方。如果你仔细观察,会发现它从 t 中选择。也就是说,允许第二个子查询从我们即将声明的 CTE 中递归地选择。因此,它还可以访问使用它的 CTE 声明的列 v。
在我们的示例中,我们使用行 (1) 对递归进行种子处理,然后通过添加 v + 1 来进行递归。最后通过设置 LIMIT 5 来终止递归(需要谨防潜在的无限递归 ,就像使用 Java 8 的流一样)。
附注:图灵完备
递归 CTE 使得 SQL:1999 图灵完备,这意味着任何程序都可以用 SQL 编写! (如果你够疯狂的话)
一个经常出现在博客上的令人印象深刻的例子是:Mandelbrot 集,如 http://explainextended.com/2013/12/31/happy-new-year-5/ 所示。
WITH RECURSIVE q(r, i, rx, ix, g) AS (
SELECT r::DOUBLE PRECISION * 0.02, i::DOUBLE PRECISION * 0.02,
.0::DOUBLE PRECISION , .0::DOUBLE PRECISION, 0
FROM generate_series(-60, 20) r, generate_series(-50, 50) i
UNION ALL
SELECT r, i, CASE WHEN abs(rx * rx + ix * ix) &amp;lt;= 2 THEN rx * rx - ix * ix END + r,
CASE WHEN abs(rx * rx + ix * ix) &amp;lt;= 2 THEN 2 * rx * ix END + i, g + 1
FROM q
WHERE rx IS NOT NULL AND g &amp;lt; 99
)
SELECT array_to_string(array_agg(s ORDER BY r), '')
FROM (
SELECT i, r, substring(' .:-=+*#%@', max(g) / 10 + 1, 1) s
FROM q
GROUP BY i, r
) q
GROUP BY i
ORDER BY i
在 PostgreSQL 上运行上面的代码,我们将得到如下结果:
复制代码 .-.:-.......==..*.=.::-@@@@@:::.:.@..*-. =. ...=...=...::+%.@:@@@@@@@@@@@@@+*#=.=:+-. ..- .:.:=::*....@@@@@@@@@@@@@@@@@@@@@@@@=@@.....::...:. .-.:-.......==..*.=.::-@@@@@:::.:.@..*-. =.
...=...=...::+%.@:@@@@@@@@@@@@@+*#=.=:+-. ..-
.:.:=::*....@@@@@@@@@@@@@@@@@@@@@@@@=@@.....::...:.
...*@@@@=.@:@@@@@@@@@@@@@@@@@@@@@@@@@@=.=....:...::.
.::@@@@@:-@@@@@@@@@@@@@@@@@@@@@@@@@@@@:@..-:@=*:::.
.-@@@@@-@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@.=@@@@=..:
...@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@:@@@@@:..
....:-*@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@::
.....@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@-..
.....@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@-:...
.--:+.@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@...
.==@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@-..
..+@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@-#.
...=+@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@..
-.=-@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@..:
.*%:@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@:@-
. ..:... ..-@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
.............. ....-@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@%@=
.--.-.....-=.:..........::@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@..
..=:-....=@+..=.........@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@:.
.:+@@::@==@-*:%:+.......:@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@.
::@@@-@@@@@@@@@-:=.....:@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@:
.:@@@@@@@@@@@@@@@=:.....%@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
.:@@@@@@@@@@@@@@@@@-...:@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@:-
:@@@@@@@@@@@@@@@@@@@-..%@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@.
%@@@@@@@@@@@@@@@@@@@-..-@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@.
@@@@@@@@@@@@@@@@@@@@@::+@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@+
@@@@@@@@@@@@@@@@@@@@@@:@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@..
@@@@@@@@@@@@@@@@@@@@@@-@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@-
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@.
印象是不是非常深刻?
3. 累计计算
这个博客有很多累计计算的示例。它们是学习高级 SQL 最有教育意义的示例之一,因为至少有十几种方法可以实现累计计算。
在概念上,累计计算很容易理解。
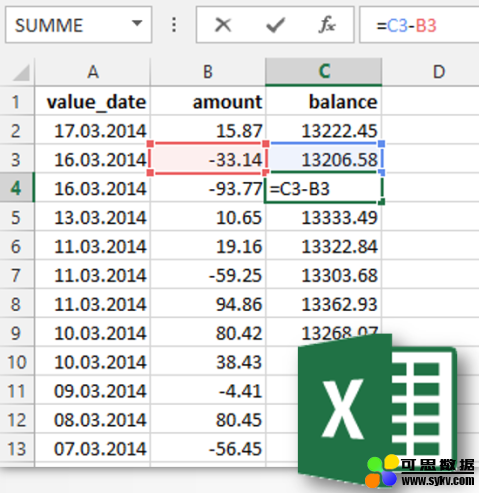
在 Microsoft Excel 中,我们只需计算前两个(或后两个)值的和(或差),然后使用可用的十字光标将该公式拉过整个电子表格。我们在电子表格中“运行”这个总数。即一个“累计”。
在 SQL 中,最好的方法是使用窗口函数,这也是该博客多次讨论的另一主题。
窗口函数是一个功能强大的概念,一开始可能不太容易理解,但事实上,它们非常非常简单:
窗口函数是在相对当前行而言的一个子集上的聚合/排序,当前行由 SELECT 转换。
就是这样简单!
它本质上的意思是,一个窗口函数可以对当前行的“上”或“下”行执行计算。然而,与普通的聚合和 GROUP BY 不同,它们不转换行,这使得它们非常有用。
语法总结如下,个别部分是可选的:
function(...) OVER (
PARTITION BY ...
ORDER BY ...
ROWS BETWEEN ... AND ...
)
因此,我们可以使用任何类型的函数(稍后我们将介绍此类函数的示例),后面紧跟其后的是 OVER() 子句,该子句指定窗口。即,这个 OVER() 子句定义如下:
PARTITION :窗口只考虑与当前行在同一分区中的行
ORDER:窗口排序可以独立于我们选择的内容
ROWS(或 RANGE )框架定义:窗口可以被限制在固定数量的行的“前面”和“后面”。
这就是窗口函数的全部功能。
那么它又是如何帮助我们累计计算的呢?考虑以下数据:
| ID | VALUE_DATE | AMOUNT | BALANCE |
|------|------------|--------|------------|
| 9997 | 2014-03-18 | 99.17 | 19985.81 |
| 9981 | 2014-03-16 | 71.44 | 19886.64 |
| 9979 | 2014-03-16 | -94.60 | 19815.20 |
| 9977 | 2014-03-16 | -6.96 | 19909.80 |
| 9971 | 2014-03-15 | -65.95 | 19916.76 |
假设 BALANCE 是我们想从 AMOUNT 中计算出来的
直观视觉上,我们可以立即看出以下情况是成立的:
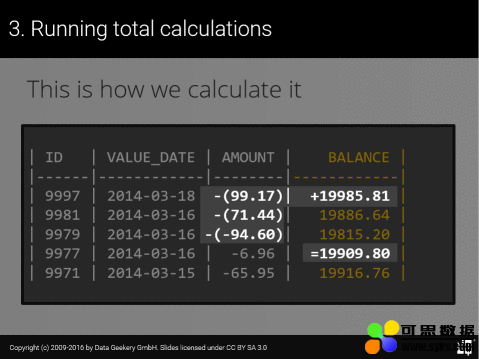
因此,使用简单的英语,任何余额都可以用以下伪 SQL 表示:
TOP_BALANCE – SUM(AMOUNT) OVER (
“all the rows on top of the current row”
)
在真正的 SQL 中,可以这样写:
SUM(t.amount) OVER (
PARTITION BY t.account_id
ORDER BY t.value_date DESC,
t.id DESC
ROWS BETWEEN UNBOUNDED PRECEDING
AND 1 PRECEDING
)
说明:
分区计算每个银行帐户的总和,而不是整个数据集的总和
排序将确保事务在求和之前(在分区内)是有序的
在求和之前,rows 子句只考虑前面的行(在分区内,给定顺序)
所有这些都发生在内存中的数据集上,该数据集由我们通过 FROM … WHERE 子句选择出来,因此速度非常快。
插曲
在我们开始讨论其他精彩技巧之前,先考虑一下:我们已经学习了
(递归)公共表表达式(CTE)
窗口函数
这两个功能都是:
非常棒
功能极其强大
声明式
SQL 标准的一部分
适用于大多数流行的 RDBMS(除了 MySQL)
非常重要的构建块
如果能从本文中得出什么结论,那就是我们应该完全了解现代 SQL 的这两个构建块。为什么呢?因为:

4. 查找最大无间隔序列
Stack Overflow 有一个非常好的功能:徽章,它可以激励人们尽可能长时间地呆在他们的网站上。

就规模而言,你可以看到我有多少徽章。
你要怎么计算这些徽章呢?让我们看看“爱好者”和“狂热者”。这些徽章是颁发给那些在他们平台上连续停留一定时间的人。无论结婚纪念日或是妻子生日,你都必须登录,否则计数器将再次从零开始。
当我们进行声明式编程时,是不需要维护任何状态和内存计数器的。现在,我们想用在线分析 SQL 的形式来表达这一点。即,考虑如下数据:
| LOGIN_TIME |
|---------------------|
| 2014-03-18 05:37:13 |
| 2014-03-16 08:31:47 |
| 2014-03-16 06:11:17 |
| 2014-03-16 05:59:33 |
| 2014-03-15 11:17:28 |
| 2014-03-15 10:00:11 |
| 2014-03-15 07:45:27 |
| 2014-03-15 07:42:19 |
| 2014-03-14 09:38:12 |
那没什么用。我们从时间戳中删除小时。这很简单:
SELECT DISTINCT
cast(login_time AS DATE) AS login_date
FROM logins
WHERE user_id = :user_id
得到的结果是:
| LOGIN_DATE |
|------------|
| 2014-03-18 |
| 2014-03-16 |
| 2014-03-15 |
| 2014-03-14 |
现在,我们已经学习了窗口函数,我们只需为每个日期添加一个简单的行数即可:
SELECT
login_date,
row_number() OVER (ORDER BY login_date)
FROM login_dates
结果如下:
| LOGIN_DATE | RN |
|------------|----|
| 2014-03-18 | 4 |
| 2014-03-16 | 3 |
| 2014-03-15 | 2 |
| 2014-03-14 | 1 |
还是很容易的吧。现在,如果我们不单独选择这些值,而是减去它们,会发生什么?
SELECT
login_date -
row_number() OVER (ORDER BY login_date)
FROM login_dates
将会得到如下结果:
| LOGIN_DATE | RN | GRP |
|------------|----|------------|
| 2014-03-18 | 4 | 2014-03-14 |
| 2014-03-16 | 3 | 2014-03-13 |
| 2014-03-15 | 2 | 2014-03-13 |
| 2014-03-14 | 1 | 2014-03-13 |
真的。很有趣。所以,14–1=13,15–2=13,16–3=13,但是 18–4=14。没有人能比 Doge 说得更好了:

有一个关于这种行为的简单示例:
ROW_NUMBER() 没有间隔,这就是它的定义
但是,我们的数据有间隔
所以,当我们从一个非连续日期的“gapful”序列中减去一个连续整数的“gapless”序列时,我们将得到连续日期中每个“gapless”子序列的相同日期,并且它是一个新的日期,其中日期序列是有间隔的。
嗯。
这意味着我们现在可以简单地 GROUP BY 该任意日期值了:
SELECT
min(login_date), max(login_date),
max(login_date) -
min(login_date) + 1 AS length
FROM login_date_groups
GROUP BY grp
ORDER BY length DESC
我们做到了。最大的连续无间隔序列被找到了:
| MIN | MAX | LENGTH |
|------------|------------|--------|
| 2014-03-14 | 2014-03-16 | 3 |
| 2014-03-18 | 2014-03-18 | 1 |
完整的查询如下:
ITH
login_dates AS (
SELECT DISTINCT cast(login_time AS DATE) login_date
FROM logins WHERE user_id = :user_id
),
login_date_groups AS (
SELECT
login_date,
login_date - row_number() OVER (ORDER BY login_date) AS grp
FROM login_dates
)
SELECT
min(login_date), max(login_date),
max(login_date) - min(login_date) + 1 AS length
FROM login_date_groups
GROUP BY grp
ORDER BY length DESC

最后,没那么难吧?当然,最主要的是有了这个想法,但是查询本身真的非常简单优雅。没有比这更简洁的方法来实现一些命令式算法了。
5. 求序列的长度
在前面,我们看到了一系列连续的值。这很容易处理,因为我们可以滥用整数的连续性。如果一个“序列”的定义不那么直观,而且除此之外,几个序列包含相同的值呢?考虑以下数据,其中 LENGTH 是要计算的每个序列的长度:
| ID | VALUE_DATE | AMOUNT | LENGTH |
|------|------------|--------|------------|
| 9997 | 2014-03-18 | 99.17 | 2 |
| 9981 | 2014-03-16 | 71.44 | 2 |
| 9979 | 2014-03-16 | -94.60 | 3 |
| 9977 | 2014-03-16 | -6.96 | 3 |
| 9971 | 2014-03-15 | -65.95 | 3 |
| 9964 | 2014-03-15 | 15.13 | 2 |
| 9962 | 2014-03-15 | 17.47 | 2 |
| 9960 | 2014-03-15 | -3.55 | 1 |
| 9959 | 2014-03-14 | 32.00 | 1 |
是的,你猜对了。 “序列”是由连续(按 ID 排序)行且具有相同的 SIGN(AMOUNT) 这一事实来定义的。再次检查如下的数据格式:
| ID | VALUE_DATE | AMOUNT | LENGTH |
|------|------------|--------|------------|
| 9997 | 2014-03-18 | +99.17 | 2 |
| 9981 | 2014-03-16 | +71.44 | 2 |
| 9979 | 2014-03-16 | -94.60 | 3 |
| 9977 | 2014-03-16 | - 6.96 | 3 |
| 9971 | 2014-03-15 | -65.95 | 3 |
| 9964 | 2014-03-15 | +15.13 | 2 |
| 9962 | 2014-03-15 | +17.47 | 2 |
| 9960 | 2014-03-15 | - 3.55 | 1 |
| 9959 | 2014-03-14 | +32.00 | 1 |
我们怎么做呢?很“简单”,首先,我们去掉所有的噪音,并添加另一个行号:
SELECT
id, amount,
sign(amount) AS sign,
row_number()
OVER (ORDER BY id DESC) AS rn
FROM trx
它的结果是:
| ID | AMOUNT | SIGN | RN |
|------|--------|------|----|
| 9997 | 99.17 | 1 | 1 |
| 9981 | 71.44 | 1 | 2 |
| 9979 | -94.60 | -1 | 3 |
| 9977 | -6.96 | -1 | 4 |
| 9971 | -65.95 | -1 | 5 |
| 9964 | 15.13 | 1 | 6 |
| 9962 | 17.47 | 1 | 7 |
| 9960 | -3.55 | -1 | 8 |
| 9959 | 32.00 | 1 | 9 |
现在,接下来的目标是生成如下表:
| ID | AMOUNT | SIGN | RN | LO | HI |
|------|--------|------|----|----|----|
| 9997 | 99.17 | 1 | 1 | 1 | |
| 9981 | 71.44 | 1 | 2 | | 2 |
| 9979 | -94.60 | -1 | 3 | 3 | |
| 9977 | -6.96 | -1 | 4 | | |
| 9971 | -65.95 | -1 | 5 | | 5 |
| 9964 | 15.13 | 1 | 6 | 6 | |
| 9962 | 17.47 | 1 | 7 | | 7 |
| 9960 | -3.55 | -1 | 8 | 8 | 8 |
| 9959 | 32.00 | 1 | 9 | 9 | 9 |
在该表中,我们希望将行号值复制到序列“末”端的“LO”和序列“顶”端的“HI”中。为此,我们将使用神奇的 LEAD() 和 LAG()。LEAD() 可以访问当前行向下的第 n 行,而 LAG() 可以访问当前行向上的第 n 行。例如:
SELECT
lag(v) OVER (ORDER BY v),
v,
lead(v) OVER (ORDER BY v)
FROM (
VALUES (1), (2), (3), (4)
) t(v)
上述查询生成的结果:

太棒了!记住,使用窗口函数,你可以对相对于当前行的子集执行排序或聚合。在 LEAD() 和 LAG() 的情况下,只要给定当前行的偏移量,就可以访问相对于当前行的单个行。这在很多情况下都很有用。
继续我们的“LO”和“HI”示例,我们可以简单地这样写:
SELECT
trx.*,
CASE WHEN lag(sign)
OVER (ORDER BY id DESC) != sign
THEN rn END AS lo,
CASE WHEN lead(sign)
OVER (ORDER BY id DESC) != sign
THEN rn END AS hi,
FROM trx
……我们将“前一个”sign (lag(sign)) 与“当前”sign (sign) 进行比较。如果它们不同,我们将行号放到“LO”中,因为它是序列的下界。
然后我们比较“下一个”sign (lead(sign)) 和“当前”sign (sign)。如果它们不同,我们将行号放到“HI”中,因为它是序列的上界。
最后,进行一些无聊的 NULL 处理来以确保一切正常,这样就完成了:
SELECT -- With NULL handling...
trx.*,
CASE WHEN coalesce(lag(sign)
OVER (ORDER BY id DESC), 0) != sign
THEN rn END AS lo,
CASE WHEN coalesce(lead(sign)
OVER (ORDER BY id DESC), 0) != sign
THEN rn END AS hi,
FROM trx
下一步。我们希望“LO”和“HI”出现在所有行中,而不仅仅是在序列的“下界”和“上界”上。例如,像这样:
| ID | AMOUNT | SIGN | RN | LO | HI |
|------|--------|------|----|----|----|
| 9997 | 99.17 | 1 | 1 | 1 | 2 |
| 9981 | 71.44 | 1 | 2 | 1 | 2 |
| 9979 | -94.60 | -1 | 3 | 3 | 5 |
| 9977 | -6.96 | -1 | 4 | 3 | 5 |
| 9971 | -65.95 | -1 | 5 | 3 | 5 |
| 9964 | 15.13 | 1 | 6 | 6 | 7 |
| 9962 | 17.47 | 1 | 7 | 6 | 7 |
| 9960 | -3.55 | -1 | 8 | 8 | 8 |
| 9959 | 32.00 | 1 | 9 | 9 | 9 |
我们使用的特性至少在 Redshift、Sybase SQL Anywhere、DB2、Oracle 中是可用的。我们使用的是“IGNORE NULLS”子句,它可以传递给某些窗口函数:
SELECT
trx.*,
last_value (lo) IGNORE NULLS OVER (
ORDER BY id DESC
ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW) AS lo,
first_value(hi) IGNORE NULLS OVER (
ORDER BY id DESC
ROWS BETWEEN CURRENT ROW
AND UNBOUNDED FOLLOWING) AS hi
FROM trx
有很多关键词!但本质都是一样的。从任何给定的“当前”行中,我们查看所有“之前的值”(ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW),但忽略所有空值。从之前的值中,我们取最后一个值,这就是我们的新“LO”值。换句话说,我们取“最近的前一个”“LO”值。
“HI”也是一样的。从任何给定的“当前”行中,我们查看所有“后续值”(ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING),但忽略所有空值。从随后的值中,我们取第一个值,这是我们的新“HI”值。换言之,我们取“最近的下一个”“HI”值。
使用幻灯片解释如下:

100% 正确,加上点无聊的 NULL 调整:
SELECT -- With NULL handling...
trx.*,
coalesce(last_value (lo) IGNORE NULLS OVER (
ORDER BY id DESC
ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW), rn) AS lo,
coalesce(first_value(hi) IGNORE NULLS OVER (
ORDER BY id DESC
ROWS BETWEEN CURRENT ROW
AND UNBOUNDED FOLLOWING), rn) AS hi
FROM trx
我们做最后一个步骤,记住清除一个个的错误:
SELECT
trx.*,
1 + hi - lo AS length
FROM trx
我们做到了,结果如下:
| ID | AMOUNT | SIGN | RN | LO | HI | LENGTH|
|------|--------|------|----|----|----|-------|
| 9997 | 99.17 | 1 | 1 | 1 | 2 | 2 |
| 9981 | 71.44 | 1 | 2 | 1 | 2 | 2 |
| 9979 | -94.60 | -1 | 3 | 3 | 5 | 3 |
| 9977 | -6.96 | -1 | 4 | 3 | 5 | 3 |
| 9971 | -65.95 | -1 | 5 | 3 | 5 | 3 |
| 9964 | 15.13 | 1 | 6 | 6 | 7 | 2 |
| 9962 | 17.47 | 1 | 7 | 6 | 7 | 2 |
| 9960 | -3.55 | -1 | 8 | 8 | 8 | 1 |
| 9959 | 32.00 | 1 | 9 | 9 | 9 | 1 |
完整的查询语句如下:
WITH
trx1(id, amount, sign, rn) AS (
SELECT id, amount, sign(amount), row_number() OVER (ORDER BY id DESC)
FROM trx
),
trx2(id, amount, sign, rn, lo, hi) AS (
SELECT trx1.*,
CASE WHEN coalesce(lag(sign) OVER (ORDER BY id DESC), 0) != sign
THEN rn END,
CASE WHEN coalesce(lead(sign) OVER (ORDER BY id DESC), 0) != sign
THEN rn END
FROM trx1
)
SELECT
trx2.*, 1
- last_value (lo) IGNORE NULLS OVER (ORDER BY id DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
+ first_value(hi) IGNORE NULLS OVER (ORDER BY id DESC
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING)
FROM trx2

嗯。这个 SQL 开始变得有趣了!
准备好接下来的学习了吗?
6. SQL 的子集求和问题
这是我最喜欢的部分!
什么是子集求和问题呢?在这里找到一个有趣的解释: https://xkcd.com/287
还有一个比较无聊的解释: https://en.wikipedia.org/wiki/Subset_sum_problem
基本上,对于每一个总数…
| ID | TOTAL |
|----|-------|
| 1 | 25150 |
| 2 | 19800 |
| 3 | 27511 |
…我们希望找到尽可能“最佳”(即最接近的)的求和,它包括以下各项的任意组合:
| ID | ITEM |
|------|-------|
| 1 | 7120 |
| 2 | 8150 |
| 3 | 8255 |
| 4 | 9051 |
| 5 | 1220 |
| 6 | 12515 |
| 7 | 13555 |
| 8 | 5221 |
| 9 | 812 |
| 10 | 6562 |
由于我们内心的数学处理速度很快,所以我们可以立即计算出这些是最好的求和:
| TOTAL | BEST | CALCULATION
|-------|-------|--------------------------------
| 25150 | 25133 | 7120 + 8150 + 9051 + 812
| 19800 | 19768 | 1220 + 12515 + 5221 + 812
| 27511 | 27488 | 8150 + 8255 + 9051 + 1220 + 812
如何用 SQL 要做到这一点呢?很简单。只需要创建一个包含所有 2n possible sums 的 CTE,然后为每个 TOTAL 找到最接近的一个即可:
-- All the possible 2N sums
WITH sums(sum, max_id, calc) AS (...)
-- Find the best sum per “TOTAL”
SELECT
totals.total,
something_something(total - sum) AS best,
something_something(total - sum) AS calc
FROM draw_the_rest_of_the_*bleep*_owl
当你在读这篇文章的时候,你可能会像我的朋友一样:

不过,别担心,解决方案也不是那么难(尽管由于算法的性质,它无法执行):
WITH sums(sum, id, calc) AS (
SELECT item, id, to_char(item) FROM items
UNION ALL
SELECT item + sum, items.id, calc || ' + ' || item
FROM sums JOIN items ON sums.id < items.id
)
SELECT
totals.id,
totals.total,
min (sum) KEEP (
DENSE_RANK FIRST ORDER BY abs(total - sum)
) AS best,
min (calc) KEEP (
DENSE_RANK FIRST ORDER BY abs(total - sum)
) AS calc,
FROM totals
CROSS JOIN sums
GROUP BY totals.id, totals.total
在本文中,我将不解释此解决方案的详细信息,因为这个例子是从上一篇文章中选取的,你可以在这里查看:如何使用 SQL 查找最接近的子集和
希望你能愉悦地阅读的相应细节,但一定要回来查看其余 4 个技巧:
7. 设限的累计计算
到目前为止,我们已经学习了如何使用窗口函数用 SQL 进行“普通”的累计计算。那很容易。现在,如果我们把累计计算限制在永远不低于零的情况下会怎么样呢?实际上,我们是想要得到如下的计算:
| DATE | AMOUNT | TOTAL |
|------------|--------|-------|
| 2012-01-01 | 800 | 800 |
| 2012-02-01 | 1900 | 2700 |
| 2012-03-01 | 1750 | 4450 |
| 2012-04-01 | -20000 | 0 |
| 2012-05-01 | 900 | 900 |
| 2012-06-01 | 3900 | 4800 |
| 2012-07-01 | -2600 | 2200 |
| 2012-08-01 | -2600 | 0 |
| 2012-09-01 | 2100 | 2100 |
| 2012-10-01 | -2400 | 0 |
| 2012-11-01 | 1100 | 1100 |
| 2012-12-01 | 1300 | 2400 |
因此,当减去 AMOUNT -20000 这个大的负数是,我们没有显示 -15550 这个实际的 TOTAL,而是显示的 0。换句话说,用数据集表示如下:
| DATE | AMOUNT | TOTAL |
|------------|--------|-------|
| 2012-01-01 | 800 | 800 | GREATEST(0, 800)
| 2012-02-01 | 1900 | 2700 | GREATEST(0, 2700)
| 2012-03-01 | 1750 | 4450 | GREATEST(0, 4450)
| 2012-04-01 | -20000 | 0 | GREATEST(0, -15550)
| 2012-05-01 | 900 | 900 | GREATEST(0, 900)
| 2012-06-01 | 3900 | 4800 | GREATEST(0, 4800)
| 2012-07-01 | -2600 | 2200 | GREATEST(0, 2200)
| 2012-08-01 | -2600 | 0 | GREATEST(0, -400)
| 2012-09-01 | 2100 | 2100 | GREATEST(0, 2100)
| 2012-10-01 | -2400 | 0 | GREATEST(0, -300)
| 2012-11-01 | 1100 | 1100 | GREATEST(0, 1100)
| 2012-12-01 | 1300 | 2400 | GREATEST(0, 2400)
我们要怎么做呢?

确切地说。使用模糊的、特定于供应商的 SQL。在本例中,我们使用的是 Oracle SQL

它是如何工作的?出奇的简单!
只要在任何表后添加 MODEL ,就可以打开一个很棒的 SQL “蠕虫罐头”!
SELECT ... FROM some_table
-- 将此放在任意 table 的后面
MODEL ...
一旦我们把 MODEL 放在那里,就可以像 Microsoft Excel 一样,在 SQL 语句中直接实现电子表格逻辑了。
以下三个条款是最有用也是使用最广泛的(即每年地球上的任何人使用 1-2 次):
MODEL
-- The spreadsheet dimensions
DIMENSION BY ...
-- The spreadsheet cell type
MEASURES ...
-- The spreadsheet formulas
RULES ...
这三个附加条款的含义最好再看下幻灯片的解释。
DIMENSION BY 子句指定电子表格的维度。与 MS Excel 不同,Oracle 中可以包含任意数量的维度:
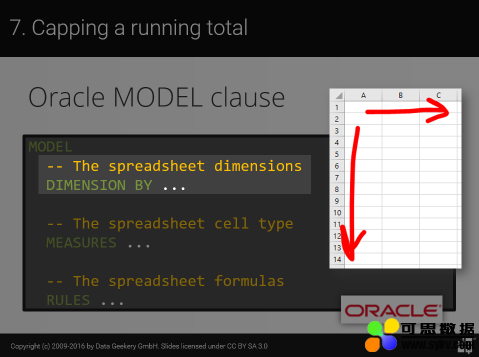
MEASURES 子句指定电子表格中每个单元格的可用值。与 MS Excel 不同,在 Oracle 中每个单元格可以有一个完整的元组,而不仅仅是单个值。

RULES 子句指定应用于电子表格中每个单元格的公式。与 MS Excel 不同,这些规则 / 公式集中在一个地方,而不是放在每个单元格中:

这种设计使得 MODEL 比 MS Excel 更难使用,但如果你敢用的话,它的功能会更强大。整个查询语句比较“琐碎”,如下所示:
SELECT *
FROM (
SELECT date, amount, 0 AS total
FROM amounts
)
MODEL
DIMENSION BY (row_number() OVER (ORDER BY date) AS rn)
MEASURES (date, amount, total)
RULES (
total[any] = greatest(0,
coalesce(total[cv(rn) - 1], 0) + amount[cv(rn)])
)
在整个过程中它的功能非常强大,并附带了 Oracle 自己的白皮书,所以请不要在本文中寻求进一步解释,请阅读优秀的白皮书:
http://www.oracle.com/technetwork/middleware/bi-foundation/10gr1-twp-bi-dw-sqlmodel-131067.pdf
8. 时间序列模式识别
如果你是从事欺诈检测或在大型数据集上运行实时分析的任何其他领域,时间序列模式识别对你来说肯定不是一个新术语。
如果我们回看下“序列长度”的数据集,我们可能希望在时间序列上为复杂事件生成一个触发器,如下所示:
| ID | VALUE_DATE | AMOUNT | LEN | TRIGGER
|------|------------|---------|-----|--------
| 9997 | 2014-03-18 | + 99.17 | 1 |
| 9981 | 2014-03-16 | - 71.44 | 4 |
| 9979 | 2014-03-16 | - 94.60 | 4 | x
| 9977 | 2014-03-16 | - 6.96 | 4 |
| 9971 | 2014-03-15 | - 65.95 | 4 |
| 9964 | 2014-03-15 | + 15.13 | 3 |
| 9962 | 2014-03-15 | + 17.47 | 3 |
| 9960 | 2014-03-15 | + 3.55 | 3 |
| 9959 | 2014-03-14 | - 32.00 | 1 |
上述触发器的规则是:
如果事件发生超过 3 次,则在第 3 次重复时触发。
与前面的 MODEL 子句类似,我们可以使用添加到 Oracle 12c 中的 Oracle 特定的子句来执行该操作:
SELECT ... FROM some_table
-- 将此放在任何 table 之后尽心模式匹配
-- table 的内容
MATCH_RECOGNIZE (...)
MATCH_RECOGNIZE 最简单的应用程序包括以下子条款:
SELECT *
FROM series
MATCH_RECOGNIZE (
-- 模式匹配按此顺序执行
ORDER BY ...
-- 这些时模式匹配产生的列
MEASURES ...
-- 对行的简短说明
-- 返回匹配结果
ALL ROWS PER MATCH
-- 要匹配的事件的“正则表达式”
PATTERN (...)
-- “什么是事件”的定义
DEFINE ...
)
这有些不可思议。让我们看一些子句的实现示例:
SELECT *
FROM series
MATCH_RECOGNIZE (
ORDER BY id
MEASURES classifier() AS trg
ALL ROWS PER MATCH
PATTERN (S (R X R+)?)
DEFINE
R AS sign(R.amount) = prev(sign(R.amount)),
X AS sign(X.amount) = prev(sign(X.amount))
)
在此我们做了什么?
按照我们想要匹配事件的顺序根据 ID 对表进行排序,比较容易。
然后指定我们所需的值作为结果。我们需要“MEASURE” trg,它被定义为分类器,也就是我们随后将在 PATTERN 中使用的文本。另外,我们希望匹配所有行。
然后,我们指定一个类似于正则表达式的模式。在该模式中以“S”代表开始事件,随后是可选事件“R”,它代表重复事件,“X”代表特殊事件 X,随后的一个或多个“R”代表再次重复。如果整个模式匹配,我们得到 SRXR 或 SRXRR 或 SRXRRR,即 X 将位于序列长度 >=4 的第三位上。
最后,我们将 R 和 X 定义为相同的东西:当前行的 SIGN(AMOUNT) 事件与前一行的 SIGN(AMOUNT) 事件相同时。我们不必定义“S”。“S”可以是任何其他行。
该查询的结果输出如下:
| ID | VALUE_DATE | AMOUNT | TRG |
|------|------------|---------|-----|
| 9997 | 2014-03-18 | + 99.17 | S |
| 9981 | 2014-03-16 | - 71.44 | R |
| 9979 | 2014-03-16 | - 94.60 | X |
| 9977 | 2014-03-16 | - 6.96 | R |
| 9971 | 2014-03-15 | - 65.95 | S |
| 9964 | 2014-03-15 | + 15.13 | S |
| 9962 | 2014-03-15 | + 17.47 | S |
| 9960 | 2014-03-15 | + 3.55 | S |
| 9959 | 2014-03-14 | - 32.00 | S |
我们可以在事件流中看到一个“X”。这正是我们所期望的。在序列长度 > 3 的事件(同一符号)中的第三次重复。
太棒了!
因为我们并不真正关心“S”和“R”事件,所以我们可以删除它们:
SELECT
id, value_date, amount,
CASE trg WHEN 'X' THEN 'X' END trg
FROM series
MATCH_RECOGNIZE (
ORDER BY id
MEASURES classifier() AS trg
ALL ROWS PER MATCH
PATTERN (S (R X R+)?)
DEFINE
R AS sign(R.amount) = prev(sign(R.amount)),
X AS sign(X.amount) = prev(sign(X.amount))
)
结果如下:
| ID | VALUE_DATE | AMOUNT | TRG |
|------|------------|---------|-----|
| 9997 | 2014-03-18 | + 99.17 | |
| 9981 | 2014-03-16 | - 71.44 | |
| 9979 | 2014-03-16 | - 94.60 | X |
| 9977 | 2014-03-16 | - 6.96 | |
| 9971 | 2014-03-15 | - 65.95 | |
| 9964 | 2014-03-15 | + 15.13 | |
| 9962 | 2014-03-15 | + 17.47 | |
| 9960 | 2014-03-15 | + 3.55 | |
| 9959 | 2014-03-14 | - 32.00 | |
多亏了 Oracle!

再说一次,不要指望我能比优秀的 Oracle 白皮书更好地解释这一点,如果你使用的是 Oracle 12c,我强烈建议你阅读该白皮书:
http://www.oracle.com/ocom/groups/public/@otn/documents/webcontent/1965433.pdf
9. 旋转和非旋转
如果你已经读过这篇文章了,那么下面的内容将非常简单:
以下是我们的数据,即演员、电影片名和电影评级:
| NAME | TITLE | RATING |
|-----------|-----------------|--------|
| A. GRANT | ANNIE IDENTITY | G |
| A. GRANT | DISCIPLE MOTHER | PG |
| A. GRANT | GLORY TRACY | PG-13 |
| A. HUDSON | LEGEND JEDI | PG |
| A. CRONYN | IRON MOON | PG |
| A. CRONYN | LADY STAGE | PG |
| B. WALKEN | SIEGE MADRE | R |
这就是我们所说的旋转:
| NAME | NC-17 | PG | G | PG-13 | R |
|-----------|-------|-----|-----|-------|-----|
| A. GRANT | 3 | 6 | 5 | 3 | 1 |
| A. HUDSON | 12 | 4 | 7 | 9 | 2 |
| A. CRONYN | 6 | 9 | 2 | 6 | 4 |
| B. WALKEN | 8 | 8 | 4 | 7 | 3 |
| B. WILLIS | 5 | 5 | 14 | 3 | 6 |
| C. DENCH | 6 | 4 | 5 | 4 | 5 |
| C. NEESON | 3 | 8 | 4 | 7 | 3 |
观察我们是如何按演员分组的,然后根据每个演员所演电影的评级来“旋转”电影的数量。我们不是以“关系”的方式来显示它(即每个组是一行),而是将整体旋转为每个组生成一列。我们可以这样做,是因为我们事先知道所有可能的组合。
非旋转与此相反,从开始时,如果我们想要回到用“每个组一行”的形式表示,即:
| NAME | RATING | COUNT |
|-----------|--------|-------|
| A. GRANT | NC-17 | 3 |
| A. GRANT | PG | 6 |
| A. GRANT | G | 5 |
| A. GRANT | PG-13 | 3 |
| A. GRANT | R | 6 |
| A. HUDSON | NC-17 | 12 |
| A. HUDSON | PG | 4 |
其实很简单。在 PostgreSQL 中,可以这样做:
SELECT
first_name, last_name,
count(*) FILTER (WHERE rating = 'NC-17') AS "NC-17",
count(*) FILTER (WHERE rating = 'PG' ) AS "PG",
count(*) FILTER (WHERE rating = 'G' ) AS "G",
count(*) FILTER (WHERE rating = 'PG-13') AS "PG-13",
count(*) FILTER (WHERE rating = 'R' ) AS "R"
FROM actor AS a
JOIN film_actor AS fa USING (actor_id)
JOIN film AS f USING (film_id)
GROUP BY actor_id
我们可以将一个简单的 FILTER 子句附加到聚合函数中,以便只计算一些数据。
在所有其他数据库中,我们都可以这样做:
SELECT
first_name, last_name,
count(CASE rating WHEN 'NC-17' THEN 1 END) AS "NC-17",
count(CASE rating WHEN 'PG' THEN 1 END) AS "PG",
count(CASE rating WHEN 'G' THEN 1 END) AS "G",
count(CASE rating WHEN 'PG-13' THEN 1 END) AS "PG-13",
count(CASE rating WHEN 'R' THEN 1 END) AS "R"
FROM actor AS a
JOIN film_actor AS fa USING (actor_id)
JOIN film AS f USING (film_id)
GROUP BY actor_id
这样做的好处是,聚合函数通常只考虑非 NULL 值,所以如果我们将每个聚合都不感兴趣的所有其他值都设为 NULL,那么我们也将得到相同的结果。
现在,如果你使用的是 SQL Server 或 Oracle,则可以使用内置的 PIVOTt 或 UNPIVOT 子句。同样,对于 MODEL 或 MATCH_RECOGNIZE 也是一样,只需要在表后添加这个新关键字,就可以得到相同的结果:
-- PIVOTING
SELECT something, something
FROM some_table
PIVOT (
count(*) FOR rating IN (
'NC-17' AS "NC-17",
'PG' AS "PG",
'G' AS "G",
'PG-13' AS "PG-13",
'R' AS "R"
)
)
-- UNPIVOTING
SELECT something, something
FROM some_table
UNPIVOT (
count FOR rating IN (
"NC-17" AS 'NC-17',
"PG" AS 'PG',
"G" AS 'G',
"PG-13" AS 'PG-13',
"R" AS 'R'
)
)
很容易吧,下一个。
10. 滥用 XML 和 JSON
首先

JSON 只是一种具有较少特性和语法的 XML
现在,每个人都知道 XML 非常好。因此可以推论出:
JSON 不是那么好
不要使用 JSON。
现在我们已经解决了这个问题,我们可以放心地忽略正在进行的 JSON-in-the-database-hype (无论如何,在五年后,大多数人都会后悔的),然后继续讨论最后一个例子。如何在数据库中执行 XML。
这就是我们想要做的:
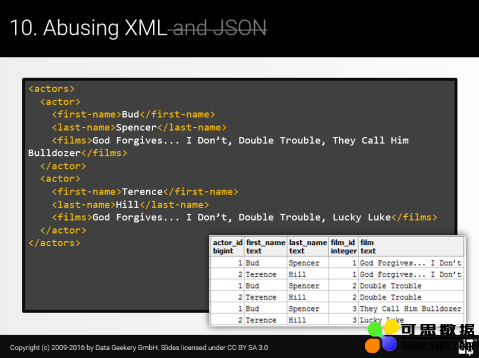
我们希望解析给定原始的 XML 文档,解套每个演员以逗号分隔的电影列表,并采用一对一的关系非规范性的表达演员 / 电影。
准备好了。使用集合。这是个不错的主意。我们使用三个 CTE:
-- PIVOTING
SELECT something, something
FROM some_table
PIVOT (
count(*) FOR rating IN (
'NC-17' AS "NC-17",
'PG' AS "PG",
'G' AS "G",
'PG-13' AS "PG-13",
'R' AS "R"
)
)
-- UNPIVOTING
SELECT something, something
FROM some_table
UNPIVOT (
count FOR rating IN (
"NC-17" AS 'NC-17',
"PG" AS 'PG',
"G" AS 'G',
"PG-13" AS 'PG-13',
"R" AS 'R'
)
)
在第一个例子中,我们只是解析了 XML。在 PostgreSQL 语法如下:
WITH RECURSIVE
x(v) AS (SELECT '
Bud
Spencer
God Forgives... I Don’t, Double Trouble, They Call Him Bulldozer
Terence
Hill
God Forgives... I Don’t, Double Trouble, Lucky Luke
'::xml),
actors(actor_id, first_name, last_name, films) AS (...),
films(actor_id, first_name, last_name, film_id, film) AS (...)
SELECT *
FROM films
很容易吧。
然后,我们使用一些 XPath 魔术,从 XML 结构中提取单个值,并将它们放入列中:
WITH RECURSIVE
x(v) AS (SELECT '...'::xml),
actors(actor_id, first_name, last_name, films) AS (
SELECT
row_number() OVER (),
(xpath('//first-name/text()', t.v))[1]::TEXT,
(xpath('//last-name/text()' , t.v))[1]::TEXT,
(xpath('//films/text()' , t.v))[1]::TEXT
FROM unnest(xpath('//actor', (SELECT v FROM x))) t(v)
),
films(actor_id, first_name, last_name, film_id, film) AS (...)
SELECT *
FROM films
这也还是很容易的。
最后,只要使用一点递归正则表达式模式匹配的魔法,我们就完成了!
WITH RECURSIVE
x(v) AS (SELECT '...'::xml),
actors(actor_id, first_name, last_name, films) AS (...),
films(actor_id, first_name, last_name, film_id, film) AS (
SELECT actor_id, first_name, last_name, 1,
regexp_replace(films, ',.+', '')
FROM actors
UNION ALL
SELECT actor_id, a.first_name, a.last_name, f.film_id + 1,
regexp_replace(a.films, '.*' || f.film || ', ?(.*?)(,.+)?', '\1')
FROM films AS f
JOIN actors AS a USING (actor_id)
WHERE a.films NOT LIKE '%' || f.film
)
SELECT *
FROM films
我们总结下:

结论
本文展示的所有内容都是声明式的。而且比较容易。当然,为了达到本次演讲所展现的有趣效果,我使用了一些夸张的 SQL 语句,并且明确地称之为“简单”。但它一点都不简单,你必须不断练习使用 SQL。像许多其他语言一样,但它有点难,因为:
它的语法有时有点笨拙
声明式思维并不容易。至少,它是非常与众不同的
但是一旦你掌握了它,使用 SQL 进行声明式编程是非常值得的,因为你只需要描述想要从数据库获得的结果,就可以用非常少的代码来表达数据之间的复杂关系。
它是不是很棒?
原文链接:https://jaxenter.com/10-sql-tricks-that-you-didnt-think-were-possible-125934.html

时间:2019-09-16 23:16 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]MySQL vs Redis,新时代王者的较量
- [数据挖掘]在复杂条件搜索上,为什么MySQL只能被ES吊打?
- [数据挖掘]MySQL 8.0的Public Key Retrival错误,毫无规律可言怎么
- [数据挖掘]50年长盛不衰,SQL为什么如此成功?
- [数据挖掘]吊打MySQL,MariaDB到底强在哪?
- [数据挖掘]50年长盛不衰,SQL为什么如此成功?
- [数据挖掘]为什么阿里不建议MySQL使用text类型?
- [数据挖掘]“MySQL Analytics Engine”来了
- [数据挖掘]惊了! MySQL 热冷数据分离设计还能这样!
- [数据挖掘]MySQL 的慢 SQL 该怎么优化?
相关推荐:
网友评论:















