小数据处理的 7 个技巧
本文作者是 Kanda 的机器学习工程师 Daniel Rothmann,他对一切具有变革性的事物都感兴趣,这里是他在和客户合作的过程中总结出的小数据处理方法。
我们经常听说大数据是构建成功的机器学习项目的关键。这里有一个大问题:许多组织没有你需要的这么多数据。
在没有最基本的数据的情况下,我们如何才能原型化和验证机器学习的想法?当资源稀缺时,我们如何有效地获取和利用数据创造价值?
在我的工作场所,我们为客户生产了许多功能原型。因此,我经常需要使用小数据。在本文中,我将分享 7 个改进使用小数据集进行原型设计结果的小技巧。

1 .认识到你的模型不能很好地泛化
这应该是第一步。你正在构建一个模型,它是建立在宇宙的一小部分知识之上的,而这应该是唯一一个可以期望它能很好地工作的情境。
如果你正在建立一个基于室内照片选择的计算机视觉原型,不要期望它在室外工作得很好。如果你有一个基于聊天室的语言模型,不要指望它适用于幻想小说。
确保你的经理或客户理解这一点。这样,每个人都可以根据你的模型应该提供的结果,调整实际期望。它还创造了一个机会来提出一个新的有用的关键指标,以量化原型范围内外的模型性能。

2 .建立良好的数据基础架构
在许多情况下,客户机没有你需要的数据,公共数据也不合适。如果原型的一部分需要收集和标记新数据,请确保基础架构,尽可能减少摩擦。
你要确保数据标签对技术和非技术人员来说都是非常容易的。我们已经开始使用 Prodigy,我认为这是一个很好的工具:既可访问又可扩展。根据项目的大小,你可能还需要设置一个自动数据接收功能,它可以接收新数据并自动将其输入到标签系统。
如果将新数据导入系统既快捷又简单,你将获得更多数据。

3 .做一些数据扩充
你通常可以通过增加所拥有的数据来扩展数据集。但这只是对数据进行细微更改,它不应显著地改变模型的输出。例如,如果旋转 40 度,猫的图像仍然是猫的图像。
在大多数情况下,增强技术允许你生成更多的「半唯一」数据点来训练你的模型。首先,你可以尝试在你的数据中加入少量的高斯噪声。
对于计算机视觉,有许多简洁的方法来增强图像。我对 Albumentations 库有过丰富的使用经验,它可以在保持标签不受损的同时进行许多有用的图像转换。

图片来源:Github 上的 Albumentations
许多人认为另一种有用的增强技术是「Mixup」。这种技术实际上是将两个输入图像混合在一起并组合它们的标签。
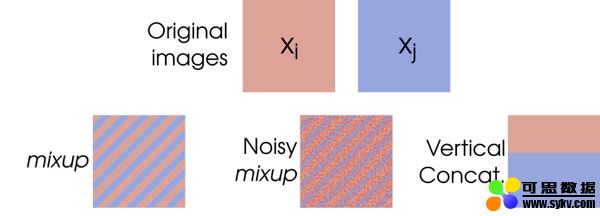
图片由 Cecilia Summers 和 Michael J.Dinneen 拍摄
在扩充其他输入数据类型时,需要考虑哪些转换会损害标签,哪些不会。

4. 生成一些合成数据
如果你已经用尽了增加真实数据的方法,你可以开始考虑创建一些假数据。生成合成数据也是一种很好的方法,它可以用来覆盖一些实际数据集中不会出现的边缘情况。
例如,许多机器人强化学习系统在部署到真正的机器人之前,都是在模拟的 3D 环境中进行训练的。对于图像识别系统,你可以类似地构建 3D 场景,它可以提供数千个新的数据点。

15 个模拟的 Dactyl 并行训练实例
创建合成数据有许多方法。在 Kanda,我们正在开发一个基于转盘的解决方案来创建用于对象检测的数据。如果你有非常高的数据需求,你可以考虑使用通用的生成对抗网络来创建合成数据。要知道 GAN 是出了名的难以训练,所以你要确保它是值得的。

NVIDIAs GauGAN
有时你可以结合使用这些方法:苹果有一个非常聪明的方法,用一个 GAN 来处理 3D 模型人脸的图像,使其看起来更逼真。如果有时间的话,可以使用这个扩展数据集的绝妙技术。

5. 小心「幸运的分割」
在训练机器学习模型时,通常将数据集按一定比例随机分割成训练集和测试集。通常情况下,这很好。但是,在处理小数据集时,由于训练示例数量较少,因此噪音风险较高。
在这种情况下,你可能会意外地得到一个幸运的分割:一个特定的数据集分割,在这个分割中,你的模型将很好地执行并在测试集中效果很好。然而,在现实中,这可能仅仅是因为测试集中没有困难的例子(巧合)。
在这种情况下,k-fold 交叉验证是一个更好的选择。本质上,你将数据集拆分为 k 个「folds」,并为每个 k 训练一个新的模型,其中一个 fold 用于测试集,其余的用于训练。这可以控制你看到的测试结果,而不仅仅是由于幸运(或不幸运)的拆分。

6 .使用迁移学习
如果你使用的是某种标准化的数据格式,如文本、图像、视频或声音,那么你可以使用其他人在这些域中用迁移学习所做的所有先前工作。这就像站在巨人的肩膀上。
当你进行迁移学习时,你会采用其他人建立的模型(通常,「其他人」是 google、Facebook 或一些主要的大学),并根据你的特殊需求对它们进行微调。
迁移学习之所以有效,是因为大多数与语言、图像或声音有关的任务都具有许多共同的特征。例如,对于计算机视觉来说,它可能是检测某些类型的形状、颜色或图案。
最近,我为客户开发了一个目标检测原型,这个客户对精度的要求非常高。我可以通过微调一个 MobileNet 单镜头探测器来大大加快开发速度,该探测器已经在 google 的开放式图像 v4 数据集(约 900 万张标签图像)上接受过训练。. 经过一天的训练,我能够使用大约 1500 张标记图像生成一个相当健壮的目标检测模型。

7. 试一试「weak learners」
有时候,你只需要面对这样一个事实:你没有足够的数据去做任何想做的事情。幸运的是,有许多传统的机器学习算法,你可以考虑使用这些算法,它们对数据集的大小不太敏感。
当数据集较小,数据点维数较高时,支持向量机等算法是一种很好的选择。
不幸的是,这些算法并不总是像最先进的方法那样精确。这就是他们之所以被称为「weak learners」的原因,至少与高度参数化的神经网络相比是如此。
提高性能的一种方法是将这些「weak learners」(这可能是一组支持向量机或决策树)组合在一起,以便它们「协同工作」生成预测。这就是组合学习的全部意义。
来源:雷锋网
via: https://www.kdnuggets.com/2019/07/7-tips-dealing-small-data.html

时间:2019-09-10 23:26 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















