盲目崇拜数据,是因为还不曾真正了解数据
尽管人脑中存储的数据还有待进一步开发和探索,但不可否认,我们的感官感觉到的一切都是数据!好记性不如烂笔头,将这些数据写下来貌似会更可靠一些,特别是将它们写入电脑。如果我们将这些笔记组织地很好,我们就可以将它们称为「数据」(尽管我也看到有人把一些写得乱七八糟的近乎于涂鸦的文件也命名为「数据」)。说实话,我不知道为什么有些人会把数据看做很高大上的东西,对其敬畏有加。
为什么要盲目崇拜数据呢?
我们需要学会面对数据采取一种平常心的实用主义态度,所以本文旨在帮助初学者了解数据背后的秘密,并帮助从业人员向那些有「数据崇拜症」的新人解释数据的基本知识。

感知和感官
在开启数据之旅时,如果你直接使用从网上购买的数据(http://bit.ly/gcp-publicdata),你很有可能会忘记这些数据是从何而来。在本文中,我将从头开始向大家展示数据产生的过程,读者可以在任何时间、任何地点创建自己的数据。
如下图所示,地板上摆放着我的食物储藏柜中常年储备的「弹药」。

实际上,这张图片本身就是数据——我们将其作为信息存储下来,而你的设备则使用它向你展示丰富的色彩。(如果你想知道,当你可以看到图像的数字矩阵时,图像的存储形式是怎样的,请参阅本文作者关于监督学习的简介:http://bit.ly/quaesita_slkid)
让我们来梳理一下我们看到的信息吧!至于你想要关注什么、记住什么信息,我们有无数种选择。下图是我在观察这张图片时,所看到的东西。

以克为单位的重量并不一定是最值得注意的信息。我们可以选择容量、价格、原产国或者其它任何我们关注的信息作为数据的内容。
如果闭上你的眼睛,你还能记得刚才你看到的每一个细节吗?是不是记不太清了?这正是我们需要收集数据的重要原因。如果我们能在脑海中完美地记住并且处理它,那就没有必要收集数据了。互联网就像是隐居在山洞里的世外高人,以上帝视角记录着人类所有产生的数据,并且可以将这些数据完美地呈现出来。
好记性不如烂笔头
由于人类的记忆就像是一个漏斗,如果我们就像在学校里修统计学的「原始年代」中一样将信息都记录下来,将会是很有帮助的。是的,朋友们,我们可以把信息直接记录在纸上。

记录在纸上的数据(相较于存储在我的海马体重的记忆,或者放在地板上的食物)要好得多,它更加耐用、更可靠。
人类的记忆是一个漏斗。
我们认为进行「记忆革命」是理所应当的,这种革命早在几千年前就开始了,那时商人需要一种可靠的方式记录下「谁向谁卖了多少蒲式耳的东西」。不妨体会一下,拥有一个能够比我们的大脑更好地存储数字的通用书写系统是一件多么棒的事情。当我们记录数据时,我们可能会对我们已经形成的对于现实世界的充分感知的一种破坏。但是在那之后,我们可以通过完全无损的方式将数据的副本传递出来。将数据记录下来的力量是惊人的!只有很少的思想和记忆会被遗漏。
当我们分析数据时,我们正在访问别人的记忆。
你会担心机器智能超越人脑吗?现在看来,仅凭纸张也可以做到这一点。要让你的大脑记住这 27 个小数字并非易事,而如果你将它们记录在纸上,那就可以长期保存该信息。
尽管数据的持久性得到了保证,但使用纸张处理数据会让人产生很多烦恼。例如,如果我突发奇想,想要把这些数字从大到小重新排列一遍,那该怎么办呢?难道我们要祈求魔法的帮助,念出「纸啊!请给我一个更好的排序吧!」这样的咒语吗?这太荒谬了。
计算机和魔法咒语
你知道计算机软件最神奇的地方是什么吗?它能让上面的咒语成为现实!所以,现在让我们从使用纸张工作进化到使用电脑处理数据。
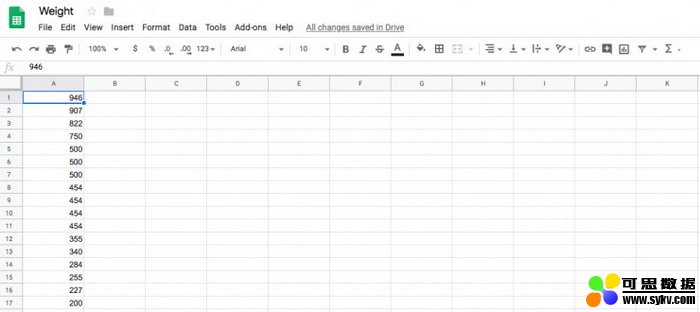
电子表格是计算机初学者们接触到的第一个数据处理软件。如果你很早就接触过电子表格,会因为熟悉而对它们倍感亲切。不过,电子表格的功能相当有限,这也是数据分析师更喜欢用 Python 或 R 语言来处理数据的原因。
我觉得电子表格还是弱了一点。与当前流行的数据科学工具相比,它们的功能相当有限。我更喜欢使用 R 和 Python 语言的组合,那么这次让我们重点了解一下 R 语言。你可以在你的浏览器中使用 Jupyter 开发环境执行下面的步骤(http://bit.ly/jupyter_try):
(1)点击「with R」(http://bit.ly/jupyter_try);
(2)点几下剪刀图标,直到所有的内容都被删除掉;
(3)恭喜你,你只需要花 5 秒钟复制粘贴下面的代码片段,然后按下「Shift+Enter」来运行它们。
weight <- c(50, 946, 454, 454, 110, 100, 340, 454, 200, 148, 355, 907, 454, 822, 127, 750, 255, 500, 500, 500, 8, 125, 284, 118, 227, 148, 125)
weight <- weight[order(weight, decreasing = TRUE)]
print(weight)
如果你是初学者,你会认为 R 语言中的排序「咒语」并没有那么明显。
然而,「咒语」本身就是这样,电子表格软件中的菜单也是这样。你只知道这些是因为你接触过它们,而不是因为它们本身就是普遍概率。要使用计算机进行工作,你需要向资深「占卜师」们请教这些「魔法咒语/手势」,然后勤加练习。而「互联网」则是我最崇敬的「圣人」,它的洞晓世间的一切。
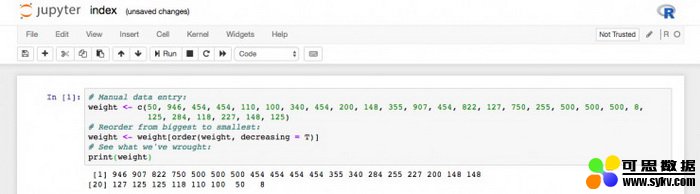
在浏览器的 Jupyter 开发环境下运行代码片段的结果。我在代码中加入了一些注释,用来解释每一行的作用。
为了加速的你学习「魔法」的进程,不要仅仅复制粘贴这些「咒语」,不妨试着对它们进行修改,看看会发生什么。例如,如果将上面代码片段中的「TURE」改成「FALSE」,会发生什么变化?
你很快就可以得到答案,是不是很神奇!?我非常热爱编程,其中一个原因就是,它是「魔法咒语」和「乐高积木」的混合体。
如果你希望自己能够成为神奇的「魔术师」,那就学着去写代码吧。
简单地说,这种编程模式就是:在互联网上查询如何做某件事,利用你刚刚学到的「魔术咒语」,看看如果你对其进行调整会发生什么,然后把它们像乐高积木一样堆在一起,执行你的命令。
数据分析和总结
实际上,就算这 27 个数字被排好了序,对我们也没有多大的意义!当我们阅读这一串数字时,我们会忘记刚刚读过的内容。人类的大脑就是这样,给定排好序的一百万个数字的列表,我们最多只能记住最后几个数。我们需要一种快速的方法对数据进行排序和总结,这样我们就会对我们在看的数据有很好的掌握。
这就是数据分析(http://bit.ly/quaesita_datasci)的作用!
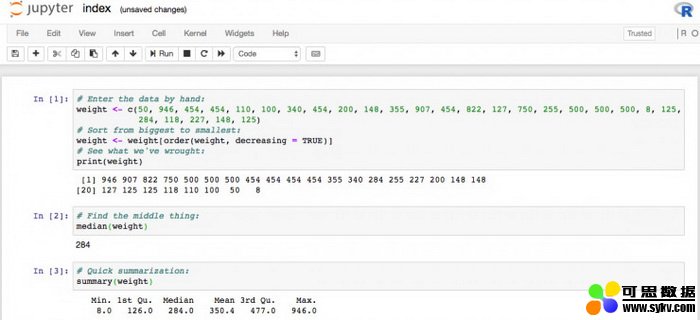
median(weight)
使用了正确的「咒语」后,我们就可以马上知道重量的中位数是多少。

对电影的品味和我一样的人就能看懂这张图(http://bit.ly/fish_called_wanda)
这个问题的答案是 248g。谁不喜欢这种马上就能得到结果的函数呢?!有很多可以用来进行总结的函数可供选择:min(),max(),mean(),median(),mode(),variance()...不妨把这些函数都试试。你也可以试着使用下面这个神奇的函数,看看会发生什么:
summary(weight)
顺便说一下,这里得到的东西被称为统计量。计算统计量会破坏你的原始数据。这不是统计学领域的内容,有兴趣的读者可以观看下面这个 8 分钟的学科介绍视频:http://bit.ly/quaesita_statistics。
绘图和数据可视化
本节关注的是通过图片对数据进行总结。事实证明,一图胜千言,每个数据点都可以通过一张图代表,也可以用图片代表很多的数据点。(在本例中,我们会制作一张只包含 27 个重量数据的图)。

小费罐可以看作自然形成的条形图,它的高度越高意味着服务越受欢迎。除了类别是安排好的,直方图与它几乎是相同的东西。
如果我们想知道我们数据中的重量是是如何分布的,例如,是否有更多的项介于 0 到 200g 之间,还是有更多的项介于 600g 到 800g 之间?那么直方图是我们的首选。

自然界中的「直方图」
直方图是总结和显示我们的示例数据的方法之一。直方图中的数据块更高代表这种数据出现的更频繁。
将条形图和直方图看做是人气比赛。
要想在电子图表软件中制作直方图,「魔法咒语」是点击一长串的不同的菜单。而在 R 语言中,这个过程要快得多:
hist(weight)
下面是我们通过这行代码得到的结果:
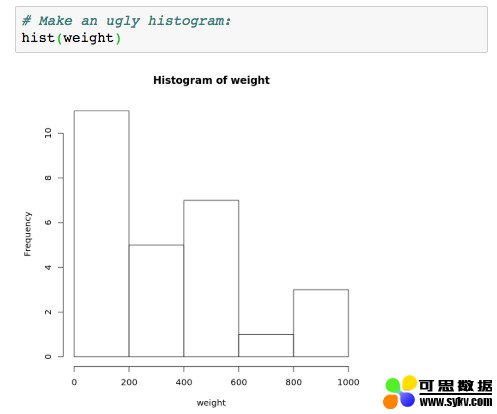
这是一个看起来很「丑」的直方图,但是我已经习惯了生活中美好的事务,而且知道你可以通过几行 R 语言代码让它变得更漂亮(http://bit.ly/histogram_tutorial)。抛开美观性不谈,这张图可以很好地说明基本的知识。
我们需要关注什么?
在横轴上,我们有几个「桶」。我们默认以 200g 为一个「桶」的宽度,但是我们很快就可以改变这个宽度。在纵轴上的刻度是计数:在数据中,我们有多少次看到重量是在 0g 到 200g 之间?直方图中显示的是 11 次。那么 600g 到 800g 之间有多少次呢?只有 1 次。(食盐的重量)。
我们可以自己选择「桶」的宽度,在不对代码进行修改的默认情况下,我们得到的是宽度为 200g 的「桶」,但是也许我们也应该改用宽度为 100g 的「桶」。没问题!训练中的「魔术师」可以改进我们的「咒语」来发现它是如何起作用的。
hist(weight, col = "salmon2", breaks = seq(0, 1000, 100))
运行结果如下:
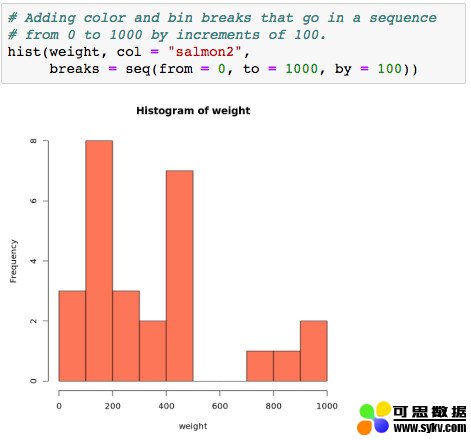
现在我们可以清楚地看到,最常见的类别是 100-200 和 400-500。真的有人在乎这个结果吗?也许并有。但我们只是想告诉大家我们可以这么做。另一方面,一个真正的数据分析师,应该擅长快速查看数据,并且掌握寻找有趣的信息的艺术。如果他们业务精湛(http://bit.ly/quaesita_analysts),那就价值连城了。
什么是数据分布?
如果我们继续使用这 27 条数据(http://bit.ly/quaesita_popwrong),我们也可以使用刚才的直方图来表示人口分布。
这差不多就是一个数据分布的样子:如果你针对整体的人口(所有你关注的信息,http://bit.ly/quaesita_statistics)数据,而不是针对某个示例(你现在恰好拥有的数据)应用「hist()」函数,你得到的直方图就可以表示数据的分布。
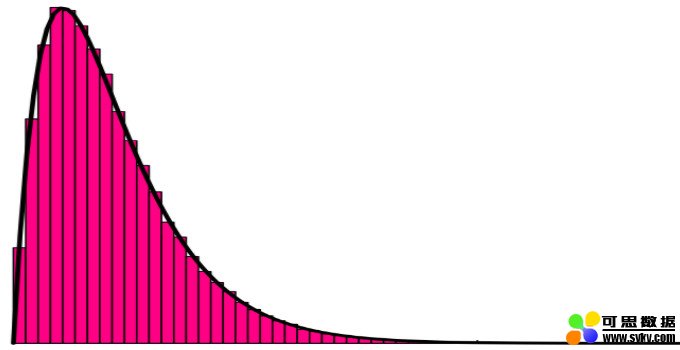
数据分布可以为你提供关于整体人口统计数据的「人气比赛」结果。它基本上就是人口直方图。横轴:人口数据值。纵轴:相对频率。
如果我们将人口都看做包装食品,那么分布就会像所有食品重量的直方图一样。这种分布只是我们脑海中的一种理论上的概念——一些包装食品已经消失在时间的迷雾中了。即使我们想要,我们也不能生成这个数据集,所以我们能做的最好的事情就是使用一个好的样本来估计它。
何为数据科学?
这个问题的答案众说纷纭,但我赞成的定义是:「数据科学(http://bit.ly/quaesita_datasci)是使数据变得有用的学科」。它的三个子领域包括:
(1)挖掘大量信息,从而获得启发(数据分析,http://bit.ly/quaesita_analysts)
(2)根据有限的信息明智地做出决策(数据统计,http://bit.ly/quaesita_statistics)
(3)使用数据中的模式自动化任务(机器学习/人工智能,http://bit.ly/quaesita_emperor)
所有的数据科学都可以归结为:知识就是力量。
宇宙间充斥着各种各样的信息,它们有待于人们发掘并好好利用。虽然我们的大脑在引导我们完成现实任务的方面具有惊人的能力,但它们并不擅长存储和处理某些非常有用的信息。
这也就是为什么我们人类一开始采用泥版文书的方式记录数据,之后用纸张,再之后用硅芯片来记录数据。我们开发了迅速查看信息的软件,现在知道如何使用它的人将自己称作数据科学家或数据分析师。而那些开发出这些工具,并且让从业者更好、更快地掌握信息的人,才是真正的幕后英雄。顺便说一下,即使是互联网也是一种分析工具(我们很少这么想,因为即使是小朋友也能做这种「数据分析」)。

升级你的记忆
我们所感知到的一切都会被存储在某个地方(至少是暂时存储)。数据并没有什么神奇的(除了将它写下来比用大脑来管理更加可靠)。有些信息是有用的,有些信息是误导性的,其它信息都没有太大意义。数据也是如此。
我们都是数据分析师,一直都是。
我们认为我们具有的惊人的生物能力是理所应当的,并且夸大了我们信息处理能力和机器辅助的各种系统之间的差距。这种不同之处在于持久性、处理速度和规模...但相同的常识规则同时适用于二者。为什么这些规则在方程的第一个符号出现时就被忽视了呢?

你还在盲目崇拜数据吗?
我很高兴能够将数据作为人类科学进步的燃料,但盲目崇拜数据,把它奉为神秘的东西是没有意义的。我们最好能够简单地讨论数据,因为从某种意义上说,人人都是数据分析师,一直如此! 雷锋

时间:2019-09-07 16:48 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















