案例详解:理解Python中的“解析式”
本篇文章将详细介绍解析式的基本要素及其各种形式。

Python中的解析式
解析式是允许在其他序列中构建序列的结构。Python 2.0介绍了列表解析式的概念,Python 3.0中进一步介绍了字典和集合解析式。

Pyhon中的解析式类型
为什么解析式如此强大?本文将通过一个例子试着理解这一点。大家都知道Python提供了各种表达列表的方法。例如:
可以明确地将整件事写成:
- squares = [0, 1, 4, 9, 25]
或者,编写for循环以创建列表:
- squares = []
- for num in range(6):
- squares.append(num*num)
创建列表的另一种方法是使用单行代码。
- squares = [num*num for num in range(6)]
上面的这个单行叫做列表解析式,是创建列表的便捷方式。它不再依赖循环并精简了代码。下一部分将深入探讨列表的概念以及Python 3中提供的其他类型的解析式。
列表解析式
列表解析式是一种以简洁的方式在Python中定义和创建列表的方法。大多数情况下,列表解析式可以仅在一行代码中创建列表,无需担心初始化列表或设置循环。
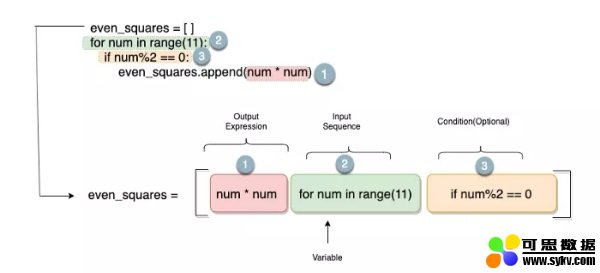
列表解析式包括以下几个部分:

列表解析式的各个部分
比如说,需要找到前五个偶数的平方。如上一节所示,有两种方法可以做到这一点:使用显式的for循环或使用列表解析式。两种方法都试试看吧。
使用循环:
- even_squares = []
- >>> for num in range(11):
- ... if num%2 == 0:
- ... even_squares.append(num * num)>>> even_squares
- [0, 4, 16, 36, 64, 100]
使用列表解析式:
- even_squares = [num * num for num in range(11) if num%2 == 0]
- even_squares
- [0, 4, 16, 36, 64, 100]
如果仔细观察,可以看出只需重新排列For循环就可以创建列表解析式。
列表解析式是Python中对集合应用的一种符号表示方法,就好像数学中用到的集合表示方法。

与数学中集合的相似性
一起实践尝试并看一些在列表解析式帮助下创建列表的例子吧。
创造毕达哥拉斯三元数组
毕达哥拉斯三元数组由三个正整数a,b和c组成,而且a²+b²=c²。通常这样的三元数组写成(a,b,c)的形式,例如(3,4,5)。
- [(a,b,c) for a in range(1,30) for b in range(1,30) for c in range(1,30)if a**2 + b**2 == c**2][(3, 4, 5), (4, 3, 5), (5, 12, 13), (6, 8, 10), (7, 24, 25), (8, 6, 10), (8, 15, 17), (9, 12, 15), (10, 24, 26), (12, 5, 13), (12, 9, 15), (12, 16, 20), (15, 8, 17), (15, 20, 25),(16, 12, 20), (20, 15, 25),(20, 21, 29), (21, 20, 29), (24, 7, 25), (24, 10, 26)]
带字符串的列表解析式
将字符串中的小写字母转换为大写字母。
- colors = ["pink", "white", "blue", "black", purple"]
- [color.upper() for color in colors]
- ['RED', 'GREEN', 'BLUE', 'PURPLE']
交换给定列表中的名和姓。
- presidents_usa = ["George Washington", "John Adams","Thomas Jefferson","James Madison","James Monroe","John Adams","Andrew Jackson"]split_names = [name.split(" ") for name in presidents_usa]
- swapped_list = [split_name[1] + " " + split_name[0] for split_name in split_names]swapped_list['Washington George', 'Adams John', 'Jefferson Thomas', 'Madison James', 'Monroe James', 'Adams John', 'Jackson Andrew']
含有元组的列表解析式
如果表达式包含元组(例如(x,y)),则必须用括号括起来。
- # Convert height from cms to feet using List Comprehension : 1 cm = 0.0328 feetheight_in_cms = [('Tom',183),('Daisy',171),('Margaret',179),('Michael',190),('Nick',165)]height_in_feet = [(height[0],round(height[1]*0.0328,1)) for height in height_in_cms]height_in_feet[('Tom', 6.0), ('Daisy', 5.6), ('Margaret', 5.9), ('Michael', 6.2), ('Nick', 5.4)]
嵌套列表解析式
列表解析式也可以嵌套以创建复杂的列表。例如,可以仅使用列表解析式来构建矩阵。
构建一个3x3的矩阵:
- matrix = [[j * j+i for j in range(3)] for i in range(3)]
- matrix[[0, 1, 4], [1, 2, 5], [2, 3, 6]]
集合解析式
集合解析式类似于列表解析式,但返回的是集合而不是列表。意义上来说语法略有不同,创建集合解析式用花括号而不是方括号。
思考包含以下人名的列表:
- names = [ 'Arnold', 'BILL', 'alice', 'arnold', 'MARY', 'J', 'BIll' ,'maRy']
该列表包含许多重复项,并且有的名字只有一个字母。目前想要的是一个由长于一个字母且仅首字母大写的名字组成的列表。为了完成这项任务,采用了集合解析式。
- {name.capitalize() for name in names if len(name) > 1}{'Alice', 'Arnold', 'Bill', 'Mary'}
字典解析式 { }
当输入采用字典或键:值对的形式时,使用字典解析式。例如,思考这样一个字典,其中键表示字符,值表示这些字符出现在语料库中的次数。
- char_dict = {'A' : 4,'z': 2, 'D' : 8, 'a': 5, 'Z' : 10 }
字典char_dict由大写和小写字母组成。在此想要计算字母的总出现次数,不管它们是大写还是小写。本文使用字典解析式来实现这个目标:
- { k.lower() : char_dict.get(k.lower(), 0) + char_dict.get(k.upper(), 0) for k in char_dict.keys()}{'a': 9, 'z': 12, 'd': 8}
生成器解析式 ( )
列表解析是列表,因为生成器表达式是生成器。生成器函数从给定序列一次一个地输出值,而不是一次性全部输出。这是一篇很好的文章,它解释了Python中Generators的细节。
生成器解析式的语法和工作方式就像列表解析式一样,只不过它们使用圆括号而不是方括号。假设想要计算前十个自然数的平方和。
- # Sum of first ten natural numbers using List Comprehensionssum([num**2 for num in range(11)])
- 385
如果我们使用任何其他可迭代而不一定是列表,结果将是相同的。
- sum({num**2 for num in range(11)})
- 385
现在,如果使用生成器解析式来计算前十个自然数的平方,那么它将是这样的:
- squares = (num**2 for num in range(11))
- squaressquares
- <generator object <genexpr> at 0x1159536d8>
与列表解析式不同,生成器解析式不返回列表而是返回生成器对象。为了得到结果,可以使用上面的表达式和sum函数。
- sum(n ** 2 for n in numbers)
- 385
看看如何摆脱上面表达式中的冗余括号,使代码更有效。
最后,不要过度使用解析式
列表解析式是减少代码长度的有效方法。它们还使代码更具可读性。但有些情况下不用它也能轻松地达成目的。
当程序的逻辑太长时,不建议使用解析式。使用解析式的主要目的是缩短代码。但是,当开始将过多的代码打包到单个语句中时,倾向于牺牲代码的可读性。在这种情况下,for循环是更优选择。
【编辑推荐】

时间:2019-08-31 18:05 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]精通哪些编程语言的程序员更“吃香”?
- [数据挖掘]底层I/O性能大PK:Python/Java被碾压,Rust有望取代
- [数据挖掘]TIOBE 3 月编程语言:Swift 一路低走,Java 份额大跌
- [数据挖掘]RedMonk语言排行:Python力压Java,Ruby持续下滑
- [数据挖掘]不得了!Python 又爆出重大 Bug~
- [数据挖掘]TIOBE 1 月榜单:Python年度语言四连冠,C 语言再次
- [数据挖掘]TIOBE12月榜单:Java重回第二,Python有望四连冠年度
- [数据挖掘]这个可能打败Python的编程语言,正在征服科学界
- [数据挖掘]2021年编程语言趋势预测:Python和JavaScript仍火热,
- [数据挖掘]十年后将要消失的五种编程语言
相关推荐:
网友评论:















