LinkedIn使用Kafka日均处理消息超4.5万亿条

LinkedIn 总部位于美国加利福尼亚州山景城,是一家全球最大的职业社交网站,成立于 2002 年 12 月,于 2011 年 5 月 20 日在美上市。截至目前,LinkedIn 一共有超过 6.45 亿会员,超过 2000 万个工作岗位。LinkedIn 目前使用 Kafka 日均处理消息超 4.5 万亿条,并已决定将所有工作负载迁移到 Azure 公有云上。
2009 年,LinkedIn 注册用户超过 5000 万人。2014 年,其注册用户规模已经超过 3 亿。而今天,LinkedIn 已经拥有超过 6.45 亿注册用户,超过 2000 万个工作岗位,每八秒钟就有一个人通过 LinkedIn 被雇佣。
伴随业务规模的不断扩大,LinkedIn 的技术团队需要成长得更加健壮,才能满足业务需求。LinkedIn 的技术团队创造了一个世界级的基础设施和一套工具和产品,使用 Project Inversion 重建了整个软件开发基础设施,并且选择将技术团队造的轮子开源,回馈社区与其他公司。在 LinkedIn 的数据基础设施中, Kafka 是核心支柱之一。
LinkedIn 在 2011 年 7 月开始大规模使用 Kafka,当时 Kafka 每天大约处理 10 亿条消息,这一数据在 2012 年达到了每天 200 亿条,而到了 2013 年 7 月,每天处理的消息达到了 2000 亿条。2015 年,他们的最新记录是每天利用 Kafka 处理的消息超过 1 万亿条,在峰值时每秒钟会发布超过 450 万条消息,每周处理的信息是 1.34 PB。每条消息平均会被 4 个应用处理。在使用 Kafka 的最初四年中,实现了 1200 倍的增长。2019 年,这个数字已经变成了 4.5 万亿条。
LinkedIn 在将 Kafka 捐献给 Apache 基金会后,也在持续打磨、优化着 Kafka 的使用与生态。随着规模的不断扩大,LinkedIn 更加关注于 Kafka 的可靠性、成本、安全性、可用性以及其他的基础指标。
LinkedIn 在 Kafka 上的主要关注领域包括:
配额(Quotas)
开发新的 Consumer
可靠性和可用性的提升
安全性
……
除了关注打磨 Kafka 技术本身以外,LinkedIn 还针对 Kafka 构建了一套完整的生态系统,以解决日益增长的业务规模所带来的新挑战。
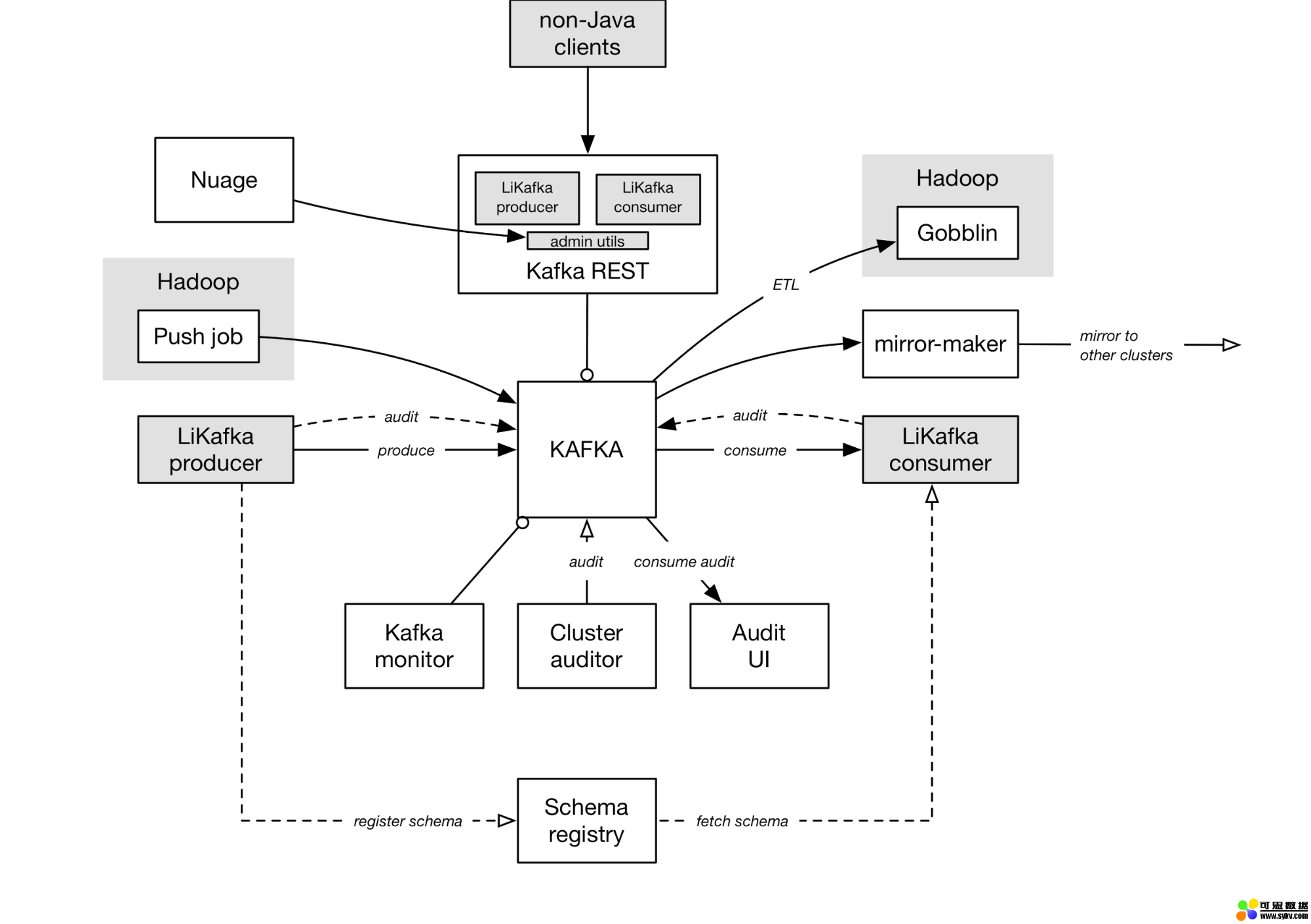
上图并不能完全反映 LinkedIn 的各种数据管道和拓扑结构,但足以说明 LinkedIn 的 Kafka 部署的关键部分,以及它们是怎样相互作用。
另据了解,LinkedIn 目前正在更换其数据中心,计划在未来几年向 Azure 迁移,并将关键业务数据委托给云平台。LinkedIn 高级副总裁 Mohak Shroff 表示,这将是该公司史上最大的技术转型之一,预计至少需要三年时间才能完成 6.45 亿用户数据迁移,以避免损害网站的可访问性、可靠性和性能。

时间:2019-08-15 18:46 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]流数据并行处理性能比较:Kafka vs Pulsar vs Praveg
- [数据挖掘]实时数据仓库必备技术:Kafka 知识梳理
- [数据挖掘]Twitter 把 Kafka 当作存储系统使用
- [数据挖掘]HBase数据迁移到Kafka?这种逆向操作你懵逼了吗?
- [数据挖掘]因为一次 Kafka 宕机,我明白了 Kafka 高可用原理!
- [数据挖掘]Kafka面试知识点深度剖析
- [数据挖掘]图文了解 Kafka 的副本复制机制
- [数据挖掘]Kafka 集群在马蜂窝大数据平台的优化与应用扩展
- [数据挖掘]Kafka加Flink不是终点!下一代大数据平台Pravega
- [数据挖掘]一篇文章带你逆袭 Kafka
相关推荐:
网友评论:















