流式数据处理在百度数据工厂应用与实践
李俊卿关于《流式数据处理在百度数据工厂应用与实践》主题演讲,主要内容如下。
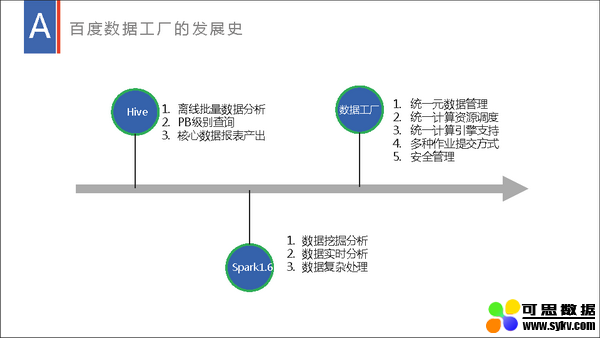
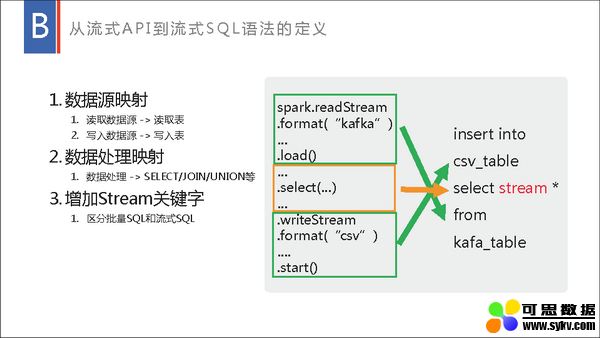
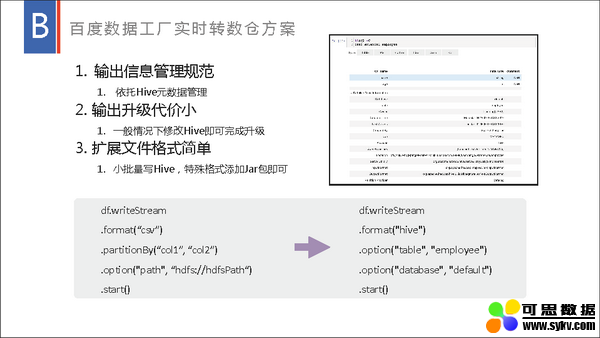
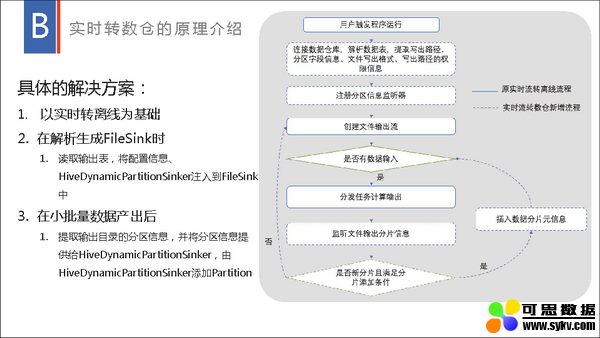
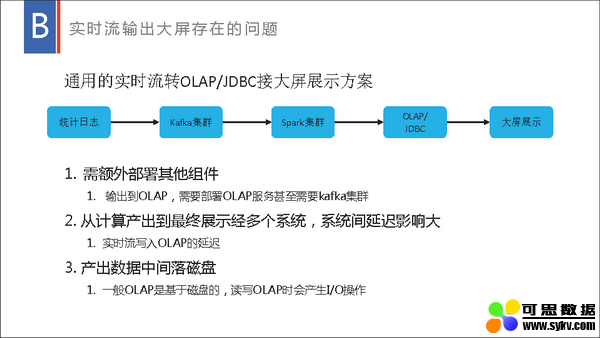
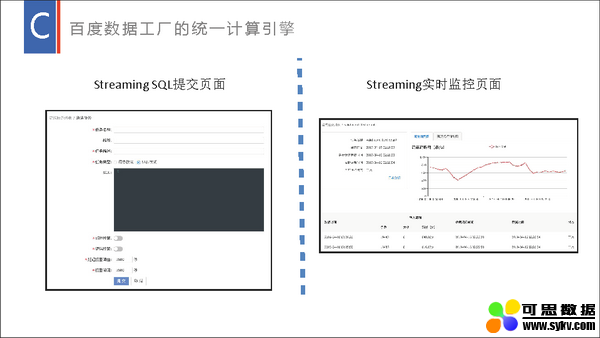
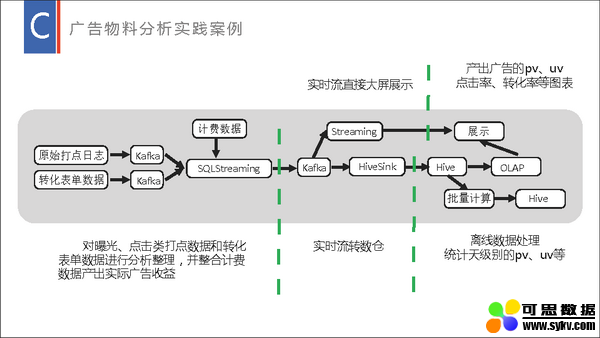
百度数据工厂以 Spark 为基础提供了流批一体的大数据分析解决方案,流式数据处理在里面承担了其中的实时计算和实时与离线转换功能。流式数据处理不仅提供了流批统一 SQL 引擎、流批统一 META 管理和实时落数仓等技术支持,还提供了流式数据处理的一体化平台,提供流式数据处理的提交、运维、监控等能力。以百度数据工厂为基础,流式数据处理在大型日志分析、广告物料分析、实时推荐、大屏展示等方面提供了强力支撑,获得了较好的效果。本演讲将分享我们就 Spark 流式数据处理在数据工厂内做了哪些技术支持、改造及相应的实践。
主要内容:
理解数据工厂在流批统一上的优势;
了解数据工厂流式数据处理的技术改进;
理解流式数据处理的一体化平台;
数据工厂流式数据处理在百度内的实践。
李俊卿,百度高级研发工程师,数据工厂流式数据处理负责人。加入百度后,一直从事大数据相关工作,参与了百度大数据离线批处理从 Hive 到 Spark1.x 到 Spark2.x 技术方案的架构升级,主导了数据工厂的流式数据处理的整体设计及核心的研发工作,提出基于 Spark 的流 / 批 SQL 引擎统一方案,对分布式系统流批一致处理有独到见解。


完整演讲 PPT 下载链接:
https://qcon.infoq.cn/2019/beijing/schedule

时间:2019-08-15 18:11 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















