学Hadoop你必须要知道的

文章目录:
一、理论知识
1.Hadoop的整体印象
2.Hadoop的优势
3.Hadoop可以做什么
4.Hadoop结构
4.1 Hadoop存储--HDFS
4.2 Hadoop计算--MapReduce
4.3 Hadoop资源管理--YARN
5.Hadoop生态
二、Hadoop实际操作
本文内容诸多借鉴,在借鉴处会表示出处,可在出处查看详情。
一、理论知识
- 参考Hadoop是什么,能干什么,怎么使用
1.Hadoop的整体印象
一句话概括:Hadoop就是存储海量数据和分析海量数据的工具。
Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce。
HDFS是一个分布式文件系统:引入存放文件元数据信息的服务器Namenode和实际存放数据的服务器Datanode,对数据进行分布式储存和读取。
MapReduce是一个计算框架:MapReduce的核心思想是把计算任务分配给集群内的服务器里执行。通过对计算任务的拆分(Map计算/Reduce计算)再根据任务调度器(JobTracker)对任务进行分布式计算。
2.Hadoop的优势
- 高可靠性 : Hadoop 按位存储和处理数据的能力值得人们信赖。
- 高扩展性 : Hadoop 是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以干计的节点中。
- 高效性 : Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
- 高容错性 : Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分。
- 低成本 : 与一体机、商用数据仓库以及 QlikView、 Yonghong Z- Suites 等数据集市相比,Hadoop 是开源的,项目的软件成本因此会大大降低。Hadoop 带有用 Java 语言编写的框架,因此运行在 linux 生产平台上是非常理想的, Hadoop 上的应用程序也可以使用其他语言编写,比如 C++。
3.Hadoop可以做什么
- 可以大数据存储:分布式存储
- 日志处理:擅长日志分析
- ETL:数据抽取到oracle、mysql、DB2、mongdb及主流数据库
- 机器学习: 比如Apache Mahout项目
- 搜索引擎:Hadoop + lucene实现
- 数据挖掘:目前比较流行的广告推荐,个性化广告推荐
Hadoop是专为离线和大规模数据分析而设计的,并不适合那种对几个记录随机读写的在线事务处理模式。
实际应用:
Flume+Logstash+Kafka+Spark Streaming进行实时日志处理分析
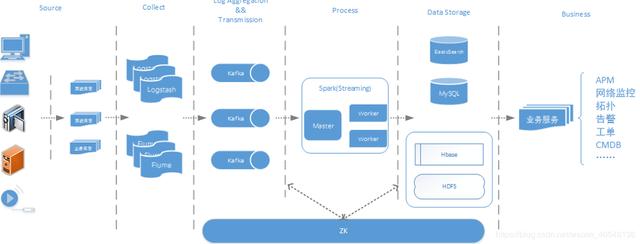
酷狗音乐的大数据平台
4.Hadoop结构
- 参考Hadoop 系列(一)基本概念
4.1 Hadoop存储–HDFS
Hadoop 的存储系统是 HDFS(Hadoop Distributed File System)分布式文件系统,对外部客户端而言,HDFS 就像一个传统的分级文件系统,可以进行创建、删除、移动或重命名文件或文件夹等操作,与 Linux 文件系统类似。
Hadoop HDFS 的架构是基于一组特定的节点构建的(见图s),这些节名称节点(NameNode,仅一个),它在 HDFS 内部提供元数据服务;第二名称节点(Secondary NameNode),名称节点的帮助节点,主要是为了整合元数据操作(注意不是名称节点的备份);数据节点(DataNode),它为 HDFS 提供存储块。由于仅有一个 NameNode,因此这是 HDFS 的一个缺点(单点失败,在 Hadoop2.x 后有较大改善)。存储在 HDFS 中的文件被分成块,然后这些块被复制到多个数据节点中(DataNode),这与传统的 RAID 架构大不相同。块的大小(通常为 128M)和复制的块数量在创建文件时由客户机决定。名称节点可以控制所有文件操作。HDFS 内部的所有通信都基于标准的 TCP/IP 协议。
(1)名称节点(NameNode)
它是一个通常在HDFS架构中单独机器上运行的组件,负责管理文件系统名称空间和控制外部客户机的访问。NameNode决定是否将文件映射到DataNode上的复制块上。对于最常见的3个复制块,第一个复制块存储在同一机架的不同节点上,最后一个复制块存储在不同机架的某个节点上。
(2)数据节点(DataNode)
数据节点也是一个通常在HDFS架构中的单独机器上运行的组件。Hadoop集群包含一个NameNode和大量DataNode。数据节点通常以机架的形式组织,机架通过一个交换机将所有系统连接起来。
数据节点响应来自HDFS客户机的读写请求。它们还响应来自NameNode的创建、删除和复制块的命令。名称节点依赖来自每个数据节点的定期心跳(heartbeat)消息。每条消息都包含一个块报告,名称节点可以根据这个报告验证块映射和其他文件系统元数据。如果数据节点不能发送心跳消息,名称节点将采取修复措施,重新复制在该节点上丢失的块。
(3)第二名称节点(Secondary NameNode)
第二名称节点的作用在于为HDFS中的名称节点提供一个Checkpoint,它只是名称节点的一个助手节点,这也是它在社区内被认为是Checkpoint Node的原因。
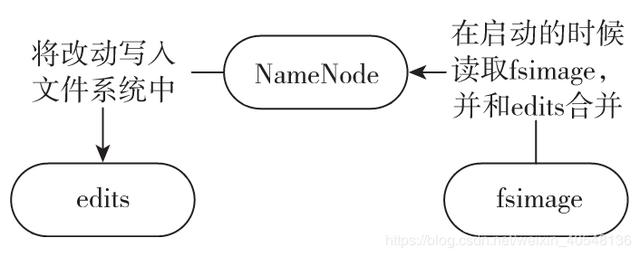
如下图所示,fsimage 是 NameNode 启动时对整个文件系统的快照;edits 是在 NameNode 启动后对文件系统的改动序列。
只有在NameNode重启时,edits才会合并到fsimage文件中,从而得到一个文件系统的最新快照。但是在生产环境集群中的NameNode是很少重启的,这意味着当NameNode运行很长时间后,edits文件会变得很大。而当NameNode宕机时,edits就会丢失很多改动。
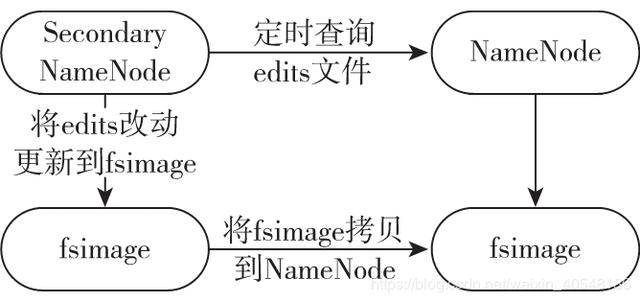
如图 1-4 所示,Secondary NameNode 会定时到 NameNode 去获取名称节点的 edits,并及时更新到自己 fsimage 上。这样,如果 NameNode 宕机,我们也可以使用 Secondary-NameNode 的信息来恢复 NameNode。并且,如果 Secondary NameNode 新的 fsimage 文件达到一定阈值,它就会将其拷贝回名称节点上,这样 NameNode 在下次重启时会使用这个新的 fsimage 文件,从而减少重启的时间。
举个数据上传的例子来深入理解下HDFS内部是怎么做的。
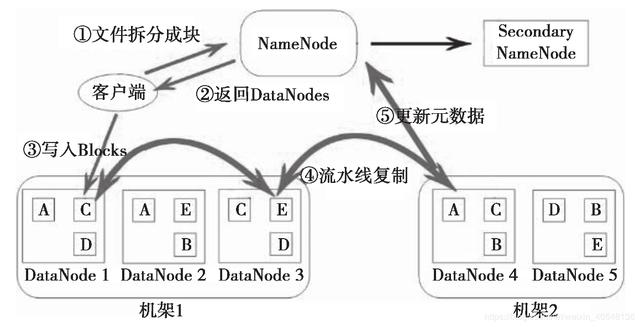
文件在客户端时会被分块,这里可以看到文件被分为 5 个块,分别是:A、B、C、D、E。同时为了负载均衡,所以每个节点有 3 个块。下面来看看具体步骤:
- 客户端将要上传的文件按 128M 的大小分块。
- 客户端向名称节点发送写数据请求。
- 名称节点记录各个 DataNode 信息,并返回可用的 DataNode 列表。
- 客户端直接向 DataNode 发送分割后的文件块,发送过程以流式写入。
- 写入完成后,DataNode 向 NameNode 发送消息,更新元数据。
这里需要注意:
- 写 1T 文件,需要 3T 的存储,3T 的网络流量。
- 在执行读或写的过程中,NameNode 和 DataNode 通过 HeartBeat 进行保存通信,确定 DataNode 活着。如果发现 DataNode 死掉了,就将死掉的 DataNode 上的数据,放到其他节点去,读取时,读其他节点。
- 宕掉一个节点没关系,还有其他节点可以备份;甚至,宕掉某一个机架也没关系;其他机架上也有备份。
4.2 Hadoop计算–MapReduce
MapReduce用于大规模数据集(大于1TB)的并行运算。概念**“Map(映射)”和“Reduce(归纳)”**以及它们的主要思想,都是从函数式编程语言借来的,还有从矢量编程语言借来的特性。
当前的软件实现是指定一个 Map(映射)函数:用来把一组键值对映射成一组新的键值对。指定并发的 Reduce(归纳)函数,用来保证所有映射的键值对中的每一个共享相同的键组,如下图所示。

下面将以 Hadoop 的“Hello World”例程—单词计数来分析MapReduce的逻辑,如下图 所示。一般的 MapReduce 程序会经过以下几个过程:输入(Input)、输入分片(Splitting)、Map阶段、Shuffle阶段、Reduce阶段、输出(Final result)。
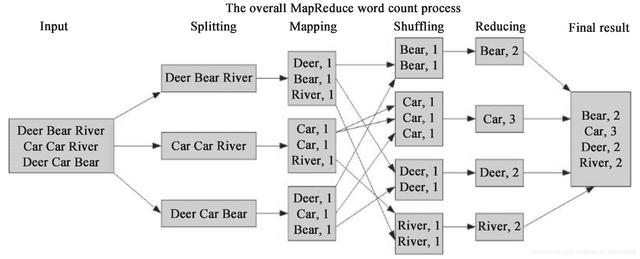
1.输入就不用说了,数据一般放在 HDFS 上面就可以了,而且文件是被分块的。关于文件块和文件分片的关系,在输入分片中说明。
2.输入分片:在进行 Map 阶段之前,MapReduce 框架会根据输入文件计算输入分片(split),每个输入分片会对应一个 Map 任务,输入分片往往和 HDFS 的块关系很密切。例如,HDFS 的块的大小是 128M,如果我们输入两个文件,大小分别是 27M、129M,那么 27M 的文件会作为一个输入分片(不足 128M 会被当作一个分片),而 129MB 则是两个输入分片(129-128=1,不足 128M,所以 1M 也会被当作一个输入分片),所以,一般来说,一个文件块会对应一个分片。如图 1-7 所示,Splitting 对应下面的三个数据应该理解为三个分片。
3.Map 阶段:这个阶段的处理逻辑就是编写好的 Map 函数,因为一个分片对应一个 Map 任务,并且是对应一个文件块,所以这里其实是数据本地化的操作,也就是所谓的移动计算而不是移动数据。如图 1-7 所示,这里的操作其实就是把每句话进行分割,然后得到每个单词,再对每个单词进行映射,得到单词和1的键值对。
4.Shuffle 阶段:这是“奇迹”发生的地方,MapReduce 的核心其实就是 Shuffle。那么 Shuffle 的原理呢?Shuffle 就是将 Map 的输出进行整合,然后作为 Reduce 的输入发送给 Reduce。简单理解就是把所有 Map 的输出按照键进行排序,并且把相对键的键值对整合到同一个组中。如上图所示,Bear、Car、Deer、River 是排序的,并且 Bear 这个键有两个键值对。
5.Reduce 阶段:与 Map 类似,这里也是用户编写程序的地方,可以针对分组后的键值对进行处理。如上图所示,针对同一个键 Bear 的所有值进行了一个加法操作,得到 这样的键值对。
6.输出:Reduce 的输出直接写入 HDFS 上,同样这个输出文件也是分块的。
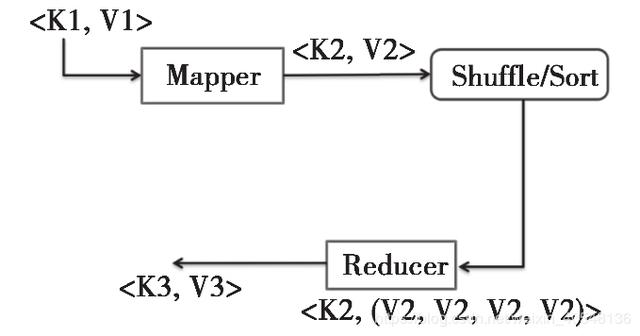
用一张图表示上述的运行流程:MapReduce 的本质就是把一组键值对 经过 Map 阶段映射成新的键值对 ;接着经过 Shuffle/Sort 阶段进行排序和“洗牌”,把键值对排序,同时把相同的键的值整合;最后经过 Reduce 阶段,把整合后的键值对组进行逻辑处理,输出到新的键值对 。这样的一个过程,其实就是 MapReduce 的本质。
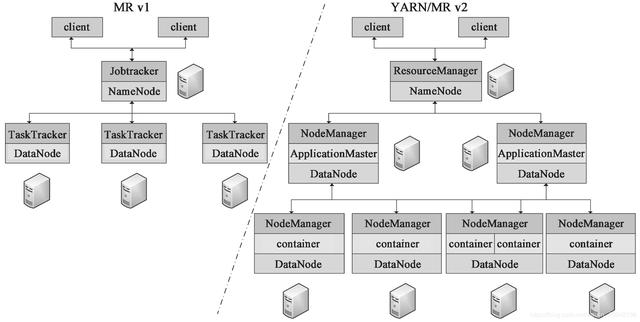
Hadoop MapReduce 可以根据其使用的资源管理框架不同,而分为 MR v1 和 YARN/MR v2 版本。
在 MR v1 版本中,资源管理主要是 Jobtracker 和 TaskTracker。Jobtracker 主要负责:作业控制(作业分解和状态监控),主要是 MR 任务以及资源管理;而 TaskTracker 主要是调度 Job 的每一个子任务 task;并且接收 JobTracker 的命令。
在 YARN/MR v2 版本中,YARN 把 JobTracker 的工作分为两个部分:
ResourceManager 资源管理器全局管理所有应用程序计算资源的分配。
ApplicationMaster 负责相应的调度和协调。
NodeManager 是每一台机器框架的代理,是执行应用程序的容器,监控应用程序的资源(CPU、内存、硬盘、网络)使用情况,并且向调度器汇报。
4.3 Hadoop资源管理–YARN
当 MapReduce 发展到 2.x 时就不使用 JobTracker 来作为自己的资源管理框架,而选择使用 YARN。这里需要说明的是,如果使用 JobTracker 来作为 Hadoop 集群的资源管理框架的话,那么除了 MapReduce 任务以外,不能够运行其他任务。也就是说,如果我们集群的 MapReduce 任务并没有那么饱满的话,集群资源等于是白白浪费的。所以提出了另外的一个资源管理架构 YARN(Yet Another Resource Manager)。这里需要注意,YARN 不是 JobTracker 的简单升级,而是“大换血”。同时 Hadoop 2.X 也包含了此架构。Apache Hadoop 2.X 项目包含以下模块。
- Hadoop Common:为 Hadoop 其他模块提供支持的基础模块。
- HDFS:Hadoop:分布式文件系统。
- YARN:任务分配和集群资源管理框架。
- MapReduce:并行和可扩展的用于处理大数据的模式。
YARN 资源管理框架包括 ResourceManager(资源管理器)、ApplicationMaster、NodeManager(节点管理器)。各个组件描述如下。
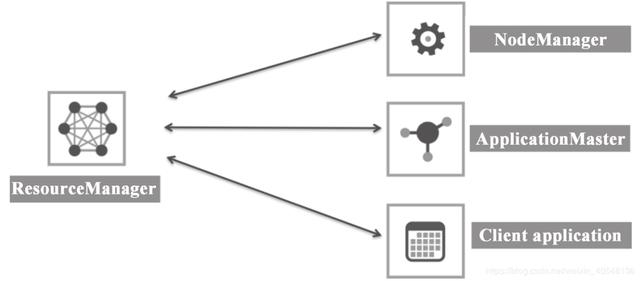
ResourceManager 是一个全局的资源管理器,负责整个系统的资源管理和分配。它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(ApplicationManager,AM)。
Scheduler 负责分配最少但满足 Application 运行所需的资源量给 Application。Scheduler 只是基于资源的使用情况进行调度,并不负责监视/跟踪 Application 的状态,当然也不会处理失败的 Task。
ApplicationManager 负责处理客户端提交的 Job 以及协商第一个 Container 以供 ApplicationMaster 运行,并且在 ApplicationMaster 失败的时候会重新启动 ApplicationMaster(YARN 中使用 Resource Container 概念来管理集群的资源,Resource Container 是资源的抽象,每个 Container 包括一定的内存、IO、网络等资源)。
ApplicatonMaster 是一个框架特殊的库,每个 Application 有一个 ApplicationMaster,主要管理和监控部署在 YARN 集群上的各种应用。
NodeManager主要负责启动 ResourceManager 分配给 ApplicationMaster 的 Container,并且会监视 Container 的运行情况。在启动 Container 的时候,NodeManager 会设置一些必要的环境变量以及相关文件;当所有准备工作做好后,才会启动该 Container。启动后,NodeManager 会周期性地监视该 Container 运行占用的资源情况,若是超过了该 Container 所声明的资源量,则会 kill 掉该 Container 所代表的进程。
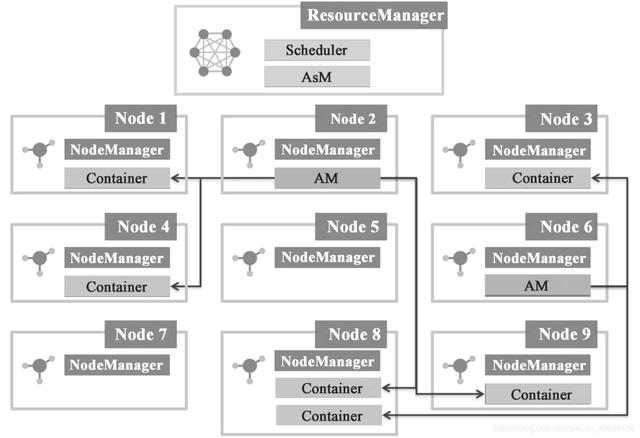
如图 1-11 所示,该集群上有两个任务(对应 Node2、Node6 上面的 AM),并且 Node2 上面的任务运行有 4 个 Container 来执行任务;而 Node6 上面的任务则有 2 个 Container 来执行任务。
5.Hadoop生态
Hadoop 的生态圈其实就是一群动物在狂欢。我们来看看一些主要的框架。
Hbase
HBase(Hadoop Database)是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用 HBase 技术可在廉价 PC Server 上搭建起大规模结构化存储集群。
Hive
Hive 是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。
Pig
Pig 是一个基于 Hadoop 的大规模数据分析平台,它提供的 SQL-LIKE 语言叫作 Pig Latin。该语言的编译器会把类 SQL 的数据分析请求转换为一系列经过优化处理的 Map-Reduce 运算。
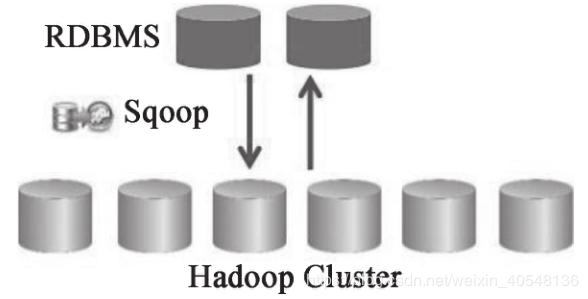
Sqoop
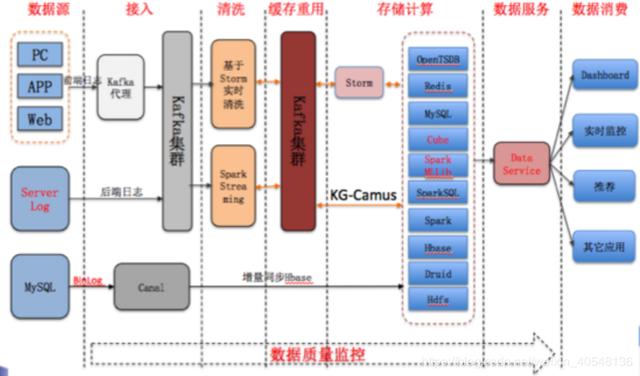
Sqoop 是一款开源的工具,主要用于在 Hadoop(Hive)与传统的数据库(MySQL、post-gresql等)间进行数据的传递,可以将一个关系型数据库中的数据导入 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导入关系型数据库中,如下图所示。
Flume
Flume 是 Cloudera 提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统,Flume 支持在日志系统中定制各类数据发送方,用于收集数据。同时,Flume 提供对数据进行简单处理并写到各种数据接受方(可定制)的能力,如下图。

Oozie
Oozie 是基于 Hadoop 的调度器,以 XML 的形式写调度流程,可以调度 Mr、Pig、Hive、shell、jar 任务等。
主要的功能如下。
- Workflow:顺序执行流程节点,支持 fork(分支多个节点)、join(将多个节点合并为一个)。
- Coordinator:定时触发 Workflow。
- Bundle Job:绑定多个 Coordinator。
Chukwa
Chukwa 是一个开源的、用于监控大型分布式系统的数据收集系统。它构建在 Hadoop 的 HDFS 和 MapReduce 框架上,继承了 Hadoop 的可伸缩性和鲁棒性。Chukwa 还包含了一个强大和灵活的工具集,可用于展示、监控和分析已收集的数据。
ZooKeeper
ZooKeeper 是一个开放源码的分布式应用程序协调服务,是 Google 的 Chubby 一个开源的实现,是 Hadoop 和 Hbase 的重要组件,如图 1-15 所示。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。

时间:2019-08-07 23:08 来源:可思数据 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















