比Spark快100倍的GPU加速SQL引擎:BlazingSQL开源了
BlazingSQL 是基于英伟达 RAPIDS 生态系统构建的 GPU 加速 SQL 引擎,可以为各种 ETL 大数据集提供 SQL 接口,并且完全运行在 GPU 之上。近日,其研发团队宣布,BlazingSQL 基于 Apache 2.0 许可完全开源!
开源项目地址: https://github.com/blazingdb/pyBlazing/
关于 BlazingSQL
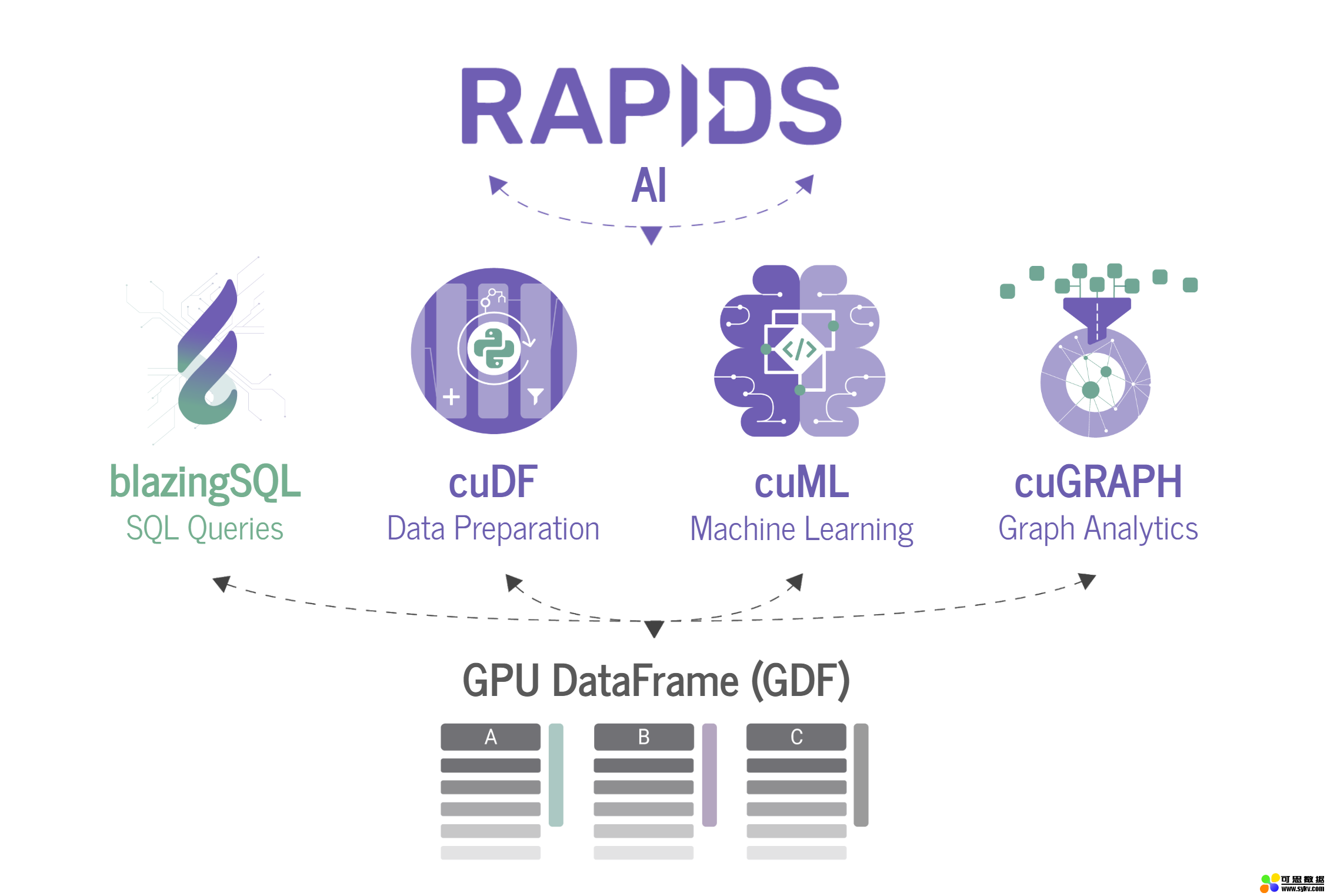
BlazingSQL 是一个基于英伟达 RAPIDS 生态系统构建的 GPU 加速 SQL 引擎。RAPIDS 包含一组软件库(BlazingSQL、cuDF、cuML、cuGraph),用来在 GPU 上执行端到端的数据科学计算和分析管道。RAPIDS 基于 Apache Arrow 列式存储格式,其中 cuDF 是一个 GPU DataFrame 库,用于加载、连接、聚合、过滤和操作数据。BlazingSQL 是面向 cuDF 的 SQL 接口,具备支持大规模数据科学工作流和企业数据集的各种功能。
官方称,BlazingSQL(几乎)可以处理任何你想要的数据。它的前身是 BlazingDB,但因为它并不是一个数据库,所以研发团队将 BlazingDB 改名为 BlazingSQL。
BlazingSQL 主要特性:
查询外部存储数据 :仅需一行代码就可以注册远程存储解决方案,例如 Amazon S3。
简单的 SQL:非常容易使用,运行 SQL 查询就能得到 GPU DataFrames(GDF)的查询结果。
互操作性:任意一个 RAPIDS 库都可以访问查询到的 GDF,并用于任意的数据科学工作负载。
BlazingSQL 解决的痛点
价格昂贵:进行大规模数据科学研究通常需要包含数千台服务器的集群,而 BlazingSQL + RAPIDS 运行相同规模的工作负载只需要其中一小部分基础设施。
速度慢:在大型数据集上运行工作负载和查询可能需要数小时或数天,而 BlazingSQL + RAPIDS 借助 GPU 加速可以在几秒内得到结果,帮助数据科学家快速迭代新模型。
复杂型:数据科学工作负载通常基于小数据集开发出原型,然后针对分布式系统进行重建。BlazingSQL + RAPIDS 让用户能够只编写一次代码,并且只需要一行代码就能动态地改变分布式集群规模。
在开发团队看来,迄今为止,SQL 是每一个主流分析生态系统的支柱之一,RAPIDS 是下一代分析生态系统,而 BlazingSQL 是 RAPIDS 的 SQL 标准。
BlazingSQL 完全基于 cuDF 和 cuIO 构建,这些项目的新功能会直接影响 BlazingSQL 的功能和性能。同时,由于 BlazingSQL 运行在 GDF 上,它与 RAPIDS 的所有库都是 100%可互操作的。
如果你正在使用 RAPIDS,或者正在考虑使用 RAPIDS,BlazingSQL 将为你提供更多便利,包括但不限于:
降低代码复杂性:SQL 语句非常简单,你可以用单个语句替换数十到数百个 cuDF 函数调用。
连接到数据湖:你不再需要同步其他数据库,BlazingSQL 可以查询云端或网络文件系统中的任意原始文件。
让 RAPIDS 变得更快:更先进的 SQL 优化器让 RAPIDS 技术栈更智能地运行。
BlazingSQL 性能表现
目前,BlazingSQL+RAPIDS 已经上线 Google Colab,研发团队在 GCP 上搭建了两个价格相当的集群,一个用于 Spark,另一个用于 BlazingSQL。他们在集群上运行端到端的数据分析工作负载:从数据湖到 ETL/ 特征工程,再到 XGBoost 训练,并对 Spark 和 BlazingSQL 的性能进行了对比测试。
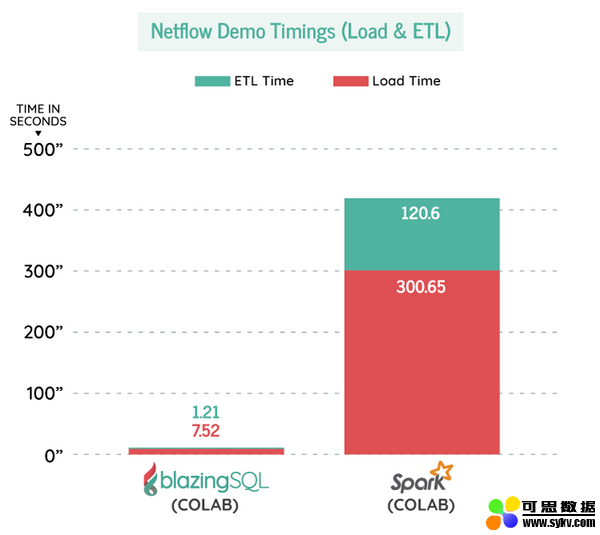
研发人员在超过两千万行 Netflow 数据上运行两次相同的特定工作负载(具体实验参见 Colab 链接)。首先运行 BlazingSQL + RAPIDS,然后使用 PySpark(Spark 2.4.1)再次运行,得到如下结果:
如果把从 Google Drive 中加载 CSV 到各自 DataFrame 所需的时间考虑在内,BlazingSQL 比 Spark 快 71 倍。
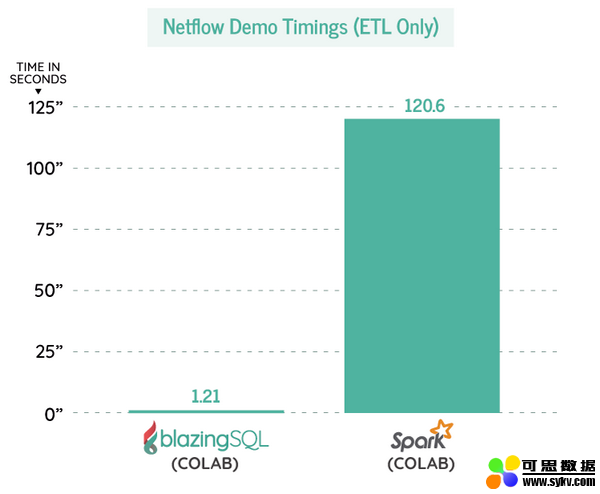
如果只看 ETL 时间,则BlazingSQL 和 RAPIDS 的速度比 Spark 快 100 倍!
运行以下 Colab 演示,用户可以使用免费英伟达 T4 GPU 资源进行同样的测试,对 BlazingSQL 的实际效果进行验证。
https://colab.research.google.com/drive/1EbPE9FwFur7fE2054BH9s23Kd0FiUgGo
据介绍,BlazingSQL 大部分性能提升来自团队的内部引擎项目,BlazingSQL 团队的工程师们希望开发一种专为 GPU DataFrames(GDF)构建的 GPU 执行内核,称之为“SIMD 表达式解释器”(SIMD Expression Interpreter)。研发团队分享了一些关于 SIMD 表达式解释器的细节,SIMD 表达式解释器通过几个关键步骤带来提升性能:
接收多个输入,包括 GDF 列、字面量,在不久的将来也会支持函数。
在加载这些输入时,SIMD 表达式解释器将对 GPU 寄存器的分配进行优化,这可以优化 GPU 线程占用率,并提高性能。
然后,虚拟机处理这些输入,并生成多个输出。假设有以下 SQL 查询:
SELECT colA + colB * 10,sin(colA) - cos(colD)FROM tableA
在以前,BlazingSQL 会将这条查询语句转换为 5 个操作(+,*,sin,cos, - ),每个操作都需要单独执行。在使用 SIMD 表达式解释器后,它会同时接收(colA、colB、colD)作为输入,并在单次内核执行中执行所有 5 个操作,最终生成两个输出。这意味着 colA 只需要加载一次,而不是两次。
目前,SIMD 表达式解释器支持 BlazingSQL 的过滤和投影,因此它对许多主流的 SQL 查询都有影响。
如何使用 BlazingSQL
使用 BlazingSQL 在 Amazon S3 中查询 CSV 文件的示例代码:
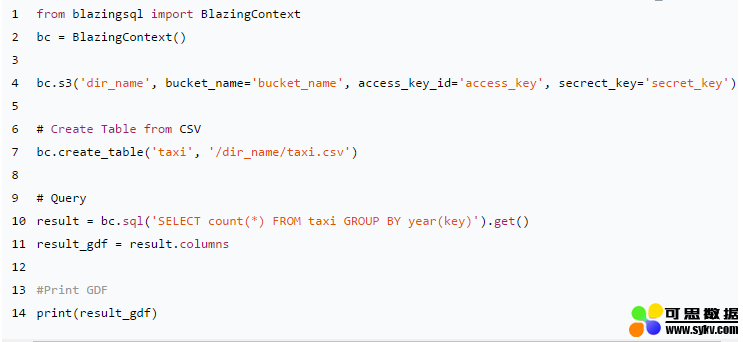
更多 BlazingSQL 的操作方法参见 GitHub 项目和官方网站。

时间:2019-08-07 16:08 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]Spark 迁移到 K8S 在有赞的实践与经验
- [数据挖掘]盘点大数据处理引擎
- [数据挖掘]Spark Operator 初体验
- [数据挖掘]如何实现Spark on Kubernetes?
- [数据挖掘]Spark SQL 物化视图技术原理与实践
- [数据挖掘]Spark on K8S 的最佳实践和需要注意的坑
- [数据挖掘]Spark 3.0重磅发布!开发近两年,流、Python、SQL重
- [数据挖掘]Spark 3.0开发近两年终于发布,流、Python、SQL重大
- [数据挖掘]Apache Spark 3.0.0 正式版终于发布了,重要特性全面
- [数据挖掘]Spark 3.0 自适应查询优化介绍,在运行时加速 Sp
相关推荐:
网友评论:















