深入理解 Spark SQL 的 Catalyst 优化器
Spark SQL是Spark最新且技术最复杂的组件之一。它同时支持SQL查询和新的DataFrame API。Spark SQL的核心是Catalyst优化器,它以一种全新的方式利用高级语言的特性(例如:Scala的模式匹配和Quasiquotes ①)构建一个可扩展的查询优化器。
最近我们在SIGMOD 2015 发表了一篇论文(合作者:Davies Liu,Joseph K. Bradley,Xiangrui Meng,Tomer Kaftan,Michael J. Franklin 和 Ali Ghodsi)。在本篇博客,我们将重新发表论文中的部分内容,为广大读者解释Catalyst 优化器的内部原理。
为了实现Spark SQL,我们基于Scala函数式编程结构,设计了一个新的可扩展的优化器Catalyst。其可扩展设计有两个目的:首先,我们希望能够非常容易地为Spark SQL添加新的优化技术和特性,尤其是为了应对我们遇到的大数据中的各种问题(例如:半结构化数据和高级分析);其次,我们希望外部的开发者可以扩展优化器。例如,为数据源添加特定的规则从而使过滤或聚合操作下推到外部的存储系统,或者支持新的数据类型。Catalyst 同时支持基于规则和基于成本的优化(CBO)。
Catalyst核心是树和操作树的规则的一个通用库。在框架的顶层,我们构建了专门用于关系型查询处理的库(例如,表达式,逻辑查询计划),以及处理查询执行的不同阶段的几组规则:分析,逻辑优化,物理计划和将部分查询编译为Java字节码的代码生成。对于后者,我们使用了另一个Scala特性Quasiquotes,它使得在运行时从组合表达式生成代码机器变得非常简单。最后,Catalyst 提供了若干公共的扩展点,包括扩展数据源和用户自定义类型。
树(Trees)
Catalyst 主要的数据类型是由节点对象构成的树。每个节点由一个节点类型和零到多个子节点组成。节点类型在Scala 中被定义为TreeNode 类的子类。这些对象是不可变的,可以使用函数式的转换对其进行操作,我们将在下一小节继续讨论。
举个简单的例子,假设我们有以下三个节点类型,可以用更简化的表达式表示为:

这些类构建成树;例如,表达式x+(1+2),可以在Scala代码中表示为:

规则(Rules)
规则用于对树进行操作,其实际上是一个将一棵树转换为另外一棵树的方法。虽然规则可以在其输入树上运行任意的代码(假定该树只是一个Scala 对象),但最常见的方式是使用一组模式匹配函数,找到并替换特定结构的子树。
模式匹配是许多函数式编程语言的特性,允许从代数数据类型的嵌套结构中进行值提取。在Catalyst,树提供的转换方法可以递归地应用模式匹配函数到树的所有节点。例如,我们可以实现一个常量之间叠加操作的规则:

应用这条规则到树x+(1+2) 就会产生一棵新树x+3。这里case 关键字是Scala 标准模式匹配的语法,可被用于匹配对象的类型以及命名值提取(这里是c1和c2)。
被传递给转换操作的模式匹配表达式是一个偏函数②,其只需要匹配所有可能的输入树的子集即可。Catalyst 将测试规则会应用到树的哪个部分,并自动跳过并下降到还没有匹配的子树。这样的能力意味着规则只需要对优化适用的树进行推理。因此,即使添加新的操作类型到系统中,也不需要修改规则。
规则(通常是 Scala 的模式匹配)可以在相同的转换调用中匹配多个模式,这使得一次实现多个转换操作非常的简单:

实践中,规则可能需要执行多次才能完全转换一棵树。Catalyst 将规则分成批次,执行各个批次直到达到一个固定的点,即应用规则之后树不再更新为止。执行规则达到一个固定的点,意味着每条规则可以非常简单且是自包含的,但是,最终仍会在树上产生比较大的全局效果。在上面的例子中,重复地应用规则将不断折叠一棵大树,如(x+0)+(3+3)。另一个例子,第一个批次也许分析一个表达式并将类型赋给所有属性,而第二个批次可能使用这些类型进行不断折叠。每个批次之后,开发者还可以在生成的新树上运行健全性检查(例如,查看所有的属性都指定了类型),通常这也同样通过递归匹配来编写。
最后,规则条件及其实现可以包含具体的Scala 代码。这使得Catalyst 比优化器 DSL 更加强大,同时保持了规则的简洁性。
根据我们的经验,对不可变树执行函数式转换操作使得整个优化器非常易于推理和调试。同时也使得优化器的转换操作可以并行化,尽管我们还没有把它利用起来。
在Spark SQL 中使用Catalyst
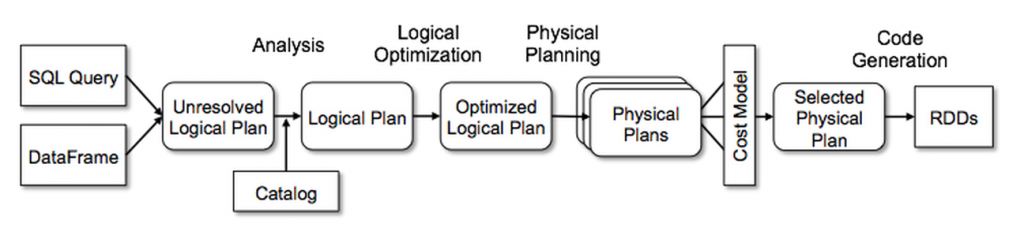
我们在四个阶段使用了Catalyst 通用树转换操作框架,如下所示:
分析逻辑计划解析引用
逻辑计划优化
物理计划
代码生成,编译部分查询为Java 字节码
分析(Analysis)
Spark SQL 以一个需要计算的关系开始,其要么来自SQL 解析器返回的抽象语法树(AST),要么来自使用API 构造的DataFrame 对象。在两种情况下,关系可能包含未解析的属性引用或关系:例如,在SQL 查询
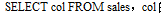 的类型,甚至是否是一个合法的列名,在我们查询表sales 之前都是未知的。如果我们不知道其类型或者没有匹配到输入表(或别名),那么这个属性就未被解析。Spark SQL 使用Catalyst 规则和一个Catalyst 对象去追踪所有数据源的表来解析这些属性。从未绑定的属性和数据类型构建一个“未解析的逻辑计划”,然后应用规则执行下面的步骤:
的类型,甚至是否是一个合法的列名,在我们查询表sales 之前都是未知的。如果我们不知道其类型或者没有匹配到输入表(或别名),那么这个属性就未被解析。Spark SQL 使用Catalyst 规则和一个Catalyst 对象去追踪所有数据源的表来解析这些属性。从未绑定的属性和数据类型构建一个“未解析的逻辑计划”,然后应用规则执行下面的步骤:
通过名字从Catalog 中查找关系。
映射命名属性,如col,到输入的给定操作符子项。
检查哪些属性引用了相同的值给它们一个相同的ID(之后允许针对col = col 这样的表达式进行优化)。
通过表达式传递和强制类型:举个例子,我们无法知道1+col 的返回类型,直到解析col 并可能将其子表达式转换为兼容类型。
总共,分析器相关的规则大概1000行代码。
逻辑优化( Logical Optimizations)
逻辑优化阶段对逻辑优化应用了标准的基于规则的优化方式。(执行基于成本的优化,通过使用规则生成多个计划并计算他们的成本。)包括:常量折叠(Constant Folding)、谓词下推(Predicate Pushdown)、投影裁剪(Projection Pruning)、空传递(Null Propagation)、布尔表达式简化(Boolean Expression Simplification)和其它规则。总的来说,我们发现为各种情形添加新的规则都极为简单。例如,当我们添加固定精度的DECIMAL 类型到Spark SQL时,以低精度的方式优化对DECIMAL的如SUM和AVG的聚合操作;只要12行代码编写一条规则在SUM和AVG表达式中找到这样的DECIMAL,然后将他们转换为64 位的LONG 类型进行聚合操作,最后将结果转换回来。下面是一个仅优化了SUM表达式的简化版本:

另外一个例子,一条12行的规则通过简单的正则表达式将LIKE表达式优化为 调用。在规则中使用任意Scala代码的自由,使得这些优化超越了模式匹配子树结构,更易于表达。
调用。在规则中使用任意Scala代码的自由,使得这些优化超越了模式匹配子树结构,更易于表达。
总共,逻辑优化规则大概800行代码。
物理计划(Physical Planning)
物理计划阶段,Spark SQL将一个逻辑计划使用匹配的Spark执行引擎的物理操作符生成一个或更多的物理计划。然后选择一个计划应用成本模型。此时,基于成本的优化器只用于选择连接算法:对于已知的很小的关系,Spark SQL使用broadcast join,使用Spark里可用的点对点的广播工具。框架支持更广泛的使用基于成本的优化,这是因为成本可以通过对整棵树使用规则来递归估计。所以,未来我们打算实现更丰富的基于成本的优化。
物理计划同样执行基于规则的物理优化,如在一个Spark的map操作执行流水线投影(Piplining Projection)或过滤。除此之外,还可以从逻辑计划将操作推到支持谓词或投影下推的数据源。我们将在之后的章节描述这些数据源的 API。
总共,物理计划规则大概500行代码。
代码生成(Code Generation)
查询优化的最后阶段涉及生成运行在各台机器上的Java字节码。由于Spark SQL通常是运行在内存数据集上,其处理受限于CPU,因此我们希望支持代码生成来加快执行速度。然而,构建代码生成引擎非常的复杂,尤其是编译器。Catalyst依赖于Scala语言特定的属性Quasiquotes使得代码生成更加简单。Quasiquotes 允许在Scala语言中使用编程的方式构建抽象语法树(ASTs),然后可以在运行时提供给Scala编译器生成字节码。我们使用Calalyst将SQL表达式的树转换为Scala代码的AST评估表达式,然后编译并运行生成的代码。
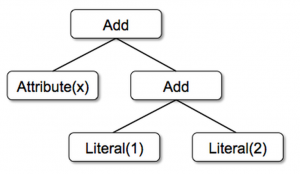
举一个简单的例子,回忆4.2节介绍的属性和字面量树节点Add,这使得我们能够写出表达式(x+y)+1。如果没有代码生成,这样的表达书不得不解析每一行数据,一直走到Add树,属性和字面量节点。
大量的分支和虚函数调用将减慢执行速度。通过代码生成,我们可以向下面,写一个函数将特定的表达式树转换为Scala AST:

以q开头的字符串就是Quasiquotes,虽然长得像字符串,但是Scala编译器会在编译时解析它们,并表示代码中的ASTs。Quasiquotes支持变量或其它ASTs 片段拼接,使用$进行表示。举个例子,Literal(1) 变成了Scala AST中的1,而Attribute("x") 变成了row.get("x")。最后,像是Add(Literal(1), Attribute("x")) 的树变成了Scala 表达式AST 1+row.get("x")。
Quasiquotes会在编译时进行类型检查以确保只有合适的ASTs或者字面量能够被替换,这比字符串连接更有用,而且是直接生成Scala AST 树而不是在运行时运行Scala解析器。此外,由于每个节点代码的生成规则不需要知晓其子节点是如何构建的,因此它们是高度可组合的。最后,如果Catalyst缺少表达式级别的优化,Scala编译器会对代码进行进一步的优化。下图展示了Quasiquotes生成的代码性能近似于手动优化的程序性能。
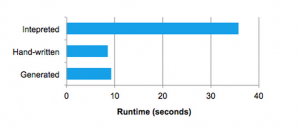
我们发现了Quasiquotes可以直接用于代码生成,而且我们观察到即使是Spark SQL新的提交者也可以快速增加新的表达式类型规则。Quasiquotes也与我们运行在原生Java对象的目标相契合:当需要访问对象中的字段时,我们通过代码生成直接访问需要的字段,而不必拷贝对象到一个Spark SQL的Row中然后使用Row的访问方法。最后,将代码生成评估与没有生成代码的表达式解析评估结合起来也非常便捷,因为我们编译的Scala代码可直接在表达式解析器中调用。
总共, Catalyst代码生成大概700行代码。
本篇博客覆盖了Spark SQL的Catalyst优化器的内部实现。全新的简单的设计使得Spark社区可以快速建立原型,实现和扩展引擎。可以通过论文中剩余的部分。如果你参加今年的 SIGMOD,请来参加我们的分享吧!
本文原文:Deep Dive into Spark SQL’s Catalyst Optimizer
来源:过往记忆https://www.iteblog.com/

时间:2019-07-26 18:08 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]Spark 迁移到 K8S 在有赞的实践与经验
- [数据挖掘]Spark Operator 初体验
- [数据挖掘]如何实现Spark on Kubernetes?
- [数据挖掘]Spark SQL 物化视图技术原理与实践
- [数据挖掘]Spark on K8S 的最佳实践和需要注意的坑
- [数据挖掘]Spark 3.0重磅发布!开发近两年,流、Python、SQL重
- [数据挖掘]Spark 3.0开发近两年终于发布,流、Python、SQL重大
- [数据挖掘]Apache Spark 3.0.0 正式版终于发布了,重要特性全面
- [数据挖掘]Spark 3.0 自适应查询优化介绍,在运行时加速 Sp
- [数据挖掘]Flink SQL vs Spark SQL
相关推荐:
网友评论:















