流式数据处理在百度数据工厂的应用与实践
本文整理自百度李俊卿在QCon上的演讲:《流式数据处理在百度数据工厂的应用与实践》。
百度数据工厂最原先用Hive引擎,进行离线批量数据分析和PB级别的查询,处理一些核心报表数据。但是在我们推广过程中发现,用户其实还是有复杂分析、实时处理、数据挖掘的请求,我们在Spark1.0推出的时候,就开始跟进Spark。在Spark1.6时候彻底在团队中推广起来,当时是SparkStreaming。当时Spark1.6的API基于RDD,它和Spark批式处理的API并不同步。后来在Spark2.2、2.3发布的时候,Spark推出了StructStreaming,它的API和批处理API已经完全一致,这时候我们迎来一次完整的架构升级,基于Spark做了一次更强大的封装;以Spark为基础,加上其他的CRM,PFS等各种模块来做统一元数据处理;统一的资源调度;以Spark为基础做了统一的一个计算引擎,以前Hive的一套也有完全融入到Spark里来;包括多种提交方式;安全管理等等。最后形成一套完整的成品。
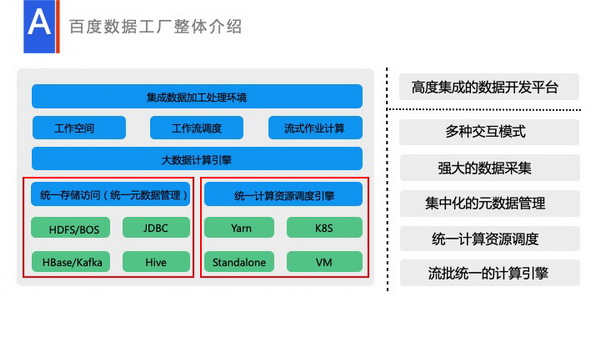
这就是我们目前的一个整体的技术架构。左下角是统一元数据处理,包括文件类的元数据处理和结构类数据,比如说Hive,或者MySQL的元数据处理,这都是作为统一的处理层的。还有就是统一调度引擎处理,我们会有统一的调度引擎,由用户注册队列,执行的时候只需要显示队列,去执行具体的资源。目前也支持K8S等。再往上一层是统一的Spark引擎。Spark引擎里面我们现在目前支持了SQL、DatasetAPI,可在上面跑各种复杂的处理。
再往上一层就是由Jupyter提供的工作空间,还有由我们自研提供的调度,自研的一套流式计算作业处理,整个一套就构成了现在完整的数据工厂。
流式数据处理在百度数据工厂的应用
接下来是比较最核心的部分,百度在Spark流批处理上做的哪些内容,主要是Spark流式SQL问题、实时转离线问题、实时转大屏展示问题。
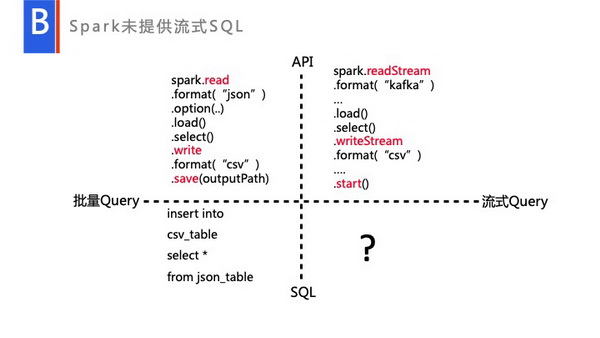
首先Spark本身有一套完整的API的,有专门的引擎用来分析,所有的流、Batch分析,信息都会经过这套API进行一系列的处理,包括语义分析、语法分析、一些优化等。大家可以注意到,右下角是空缺的,Spark目前是没有提供这部分内容的。而用户转型过程中很多用户都是由Hive过来的,是熟悉应用SQL的用户,他们要处理流式数据,就会迫切的需要有一个SQL的引擎,来帮他将Hive的SQL转型成一个流式的SQL。
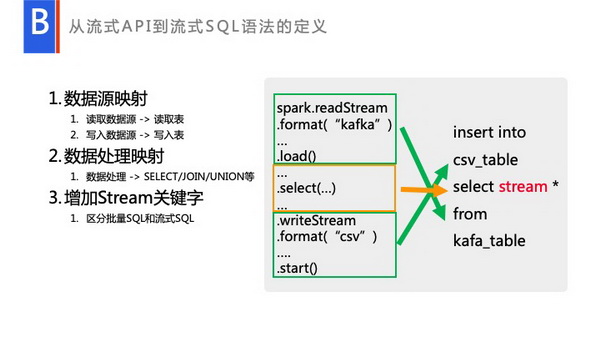
我们针对这个问题进行了一些开发。首先大家看一下,上面是SparkAPI层,Spark在流批处理上的API已经做得很完善了,是通过read和readStream来进行区分的。批到SQL处理,其实就是,可以完全看到它是首先是Sparkread一个Source,而它会映射成一个FromTable,具体的处理会映射成select、join、union等各种操作。然后WriteTable这种,在最后映射成了kafka_Table。我们流式SQL也可以映射这种类型的。
比如说这个例子,它从Kafka读取,输出到HDFS,映射的流式SQL的就是Kafka_Table。我们可以专门定义一个KafkaTable。用户的处理,我们会变成 。。大家注意,我中间加了一个stream关键字。Spark在处理的时候,做了统一引擎的处理。只有API层用户写readStream的时候,它才是一个流式的处理,如果它用户写一个Read,它就是一个批处理。相对来说,SQL层我们也做了相应的处理,跑的同样的SQL,用户如果没加Stream关键字,它就是批处理的一个SQL,如果加Stream关键字,它就变成一个流式处理。但里面处理的引擎是完全一致的,只不过最后转换Plan的时候,将最后原Plan的部分转换成了流的plan。
。。大家注意,我中间加了一个stream关键字。Spark在处理的时候,做了统一引擎的处理。只有API层用户写readStream的时候,它才是一个流式的处理,如果它用户写一个Read,它就是一个批处理。相对来说,SQL层我们也做了相应的处理,跑的同样的SQL,用户如果没加Stream关键字,它就是批处理的一个SQL,如果加Stream关键字,它就变成一个流式处理。但里面处理的引擎是完全一致的,只不过最后转换Plan的时候,将最后原Plan的部分转换成了流的plan。
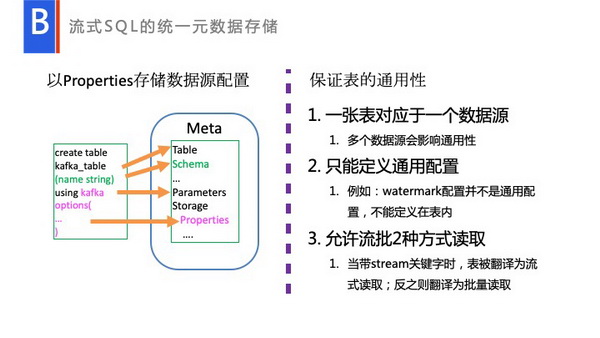
这里也涉及了Table是怎么存储的。Table存储,如图所示,一个批量的Table存储的时候,无非就是Tablename、Schema、Properties,还有一些定义,比如说location等一些配置的信息。同样可以把我们创建的KafkaTable也可以映射进去,比如说我创建的Table名称可以映射TableName等,和Meta这边进行一一对应,这样我们在Hive那一侧,已经有了完善的一套Table的存储信息。它会生成一个虚拟的路径,其实并不会真正去创建,并不会真正去对它执行的。在数据工厂中,我们是这样定义一个Table的。一个Table定义出来以后为要能被多个人使用,但临时Table除外,你能够授权给其他人去读,也能够去进行列裁减,能够对它进行一些如数脱敏的数据分析,这时候就需要考虑Table的通用性。
首先第一点,我们创建的Table不能存放多个数据源。比如说存放三个数据源,这时完全可以定义三个Table,不同的数据源做Join,做Unit分析等,这在Spark里面都是OK的。
第二点只能定义通用配置。给别人使用,授权,计算的时候,肯定会需要考虑他自己的应用场景,这里面不能去搀杂何与应用场景相关信息,比如说watermark配置,这就是属于与应用场景相关的信息,这部分信息都是不能存放于Table里面的。
另外就是Spark原生是支持Kafka,流式的Table。它要既能够去流式的去读,也能够批量的去读,既然定义了Table我们怎么去读呢?这就是我们在Spark里面的改进,主要改动的部分就是改动了语义分析层的一个逻辑。大家可以看一下右侧整个逻辑框架。
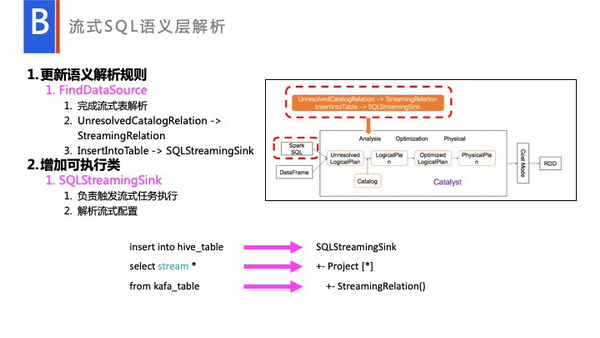
我们主要改动就改动在语义层分析上。在这个规则上增加一个语义分析FindDataSouce,完成流式表解析,和增加了一个专门的可执行类SQLStreamingSink,用来专门读取。比如说读取Watermark或各种的配置,最终产生一个流式的Plan去执行。最后经过语义层分析之后,就变成了一个SQLStreamingSink。到这一步,一旦执行起来,它和正常API调度是一样的,这样API和SQL在语义层之后已经达到完整一致了。整体只在语义层这个地方做了一些区别而已。

总结来说,首先我们提供了一个统一的Hive元数据存储,我们所有的Table都是基于Hive的,当然Hive只是一种方案,主要是用数据仓库的形式来对数据进行统一管理。我们升级了FindDataSource,用来处理Table到Source一个定义。比如说用户的groupby,filter,sum等操作都会通过语义解析的时候,会对它进行分析。现在这套方案,我们已经提供给社区。如果大家有兴趣的可以一块看看有什么更好的方案解决StreamingJoinBach的处理,在Spark的Patch中搜SQLStreaming可以看到目前正在讨论的链接,欢迎一起讨论相关方案。
实时转离线问题
很多人会说实时转离线用的场景多吗?其实在百度内的场景用的不少的,因为比如说用户的点击日志数据,大部分都是实时存放在日志中的,他会进行流式处理时候会全部打到Kafka消息队列里面,它还是有些需求,对数据进行一些比如说天级别,月级别,甚至年级别的数据分析。这时候应该怎么办呢?于是我们就提供了实时转离线的功能,其实Spark本身已经提供了一个实时转离线的,就是右侧的这个代码。

比如说定义了一个CSV,定义一下它的分区路径,定义partition、location等,去执行写的操作时是有问题的。首先它输出信息完全是由人为去记在如一个卡片里,记在一个统一的文档里,下游去用的时候,问上游询要。一旦上游改变了,里面信息肯定就完全不对称了。
另外一个就是迁移升级问题。在百度内部存在集群迁移的问题,一个机房一般用几年之后,都会下线,这时候就会存在机型迁移。在输出路径上,或者在输出格式上,需要做出改变。而现在,一般来说,就是很多数据开发的人员,更期望的是开发的代码,能长时间运行。如果我用当前的实时转离线方案的话,肯定需要拿到原生的代码进行修改,再搭架构,再执行,这也是现实场景中用户吐槽最多的。
另外就是一个拓展文件格式,比如说甲方要求输出sequenceFile,并指定了格式。但下游需要的sequenceFile格式是不同,怎么去拓展?这样开发代价很大,很多用户是比较抵制的,我们提供的方案是什么呢?就是实时转数仓的方案。

大家知道Hive保存了很多信息,里面这些元数据信息,比如说有统一的管理员进行管理之后,这些信息都可以很明晰,很明了的被其他人看到。但输出升级或迁移了,这时候修改location就可以了,代码比较好改。具体代码是什么样呢?就是右下角的这行代码。
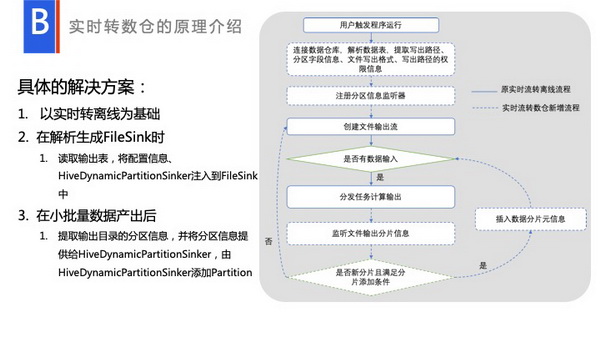
这个方案具体实现是这样的,原生有一个FileSink,读取CSV的数据,然后对数据进行处理之后,进行流式输出。只不过我们改动变成了Hive的FileFormat,以批量的形式进行写入,然后输出出去。我们在创建FileSink的时候,我们会读一下用户填入的Table,拿到它的信息,注入进去,进行一个写操作。大家可以注意到有一个分析监听器 ,在运行完每一个批量,都有一个信息反馈,如到底输出了哪些partition,能拿到相应的分区信息。拿到这个分区信息之后,可以对它进行一些处理,最后注入到Hive中,这样的话到底生产了哪些partition,完全可以在Hive里面可以去查到的。
,在运行完每一个批量,都有一个信息反馈,如到底输出了哪些partition,能拿到相应的分区信息。拿到这个分区信息之后,可以对它进行一些处理,最后注入到Hive中,这样的话到底生产了哪些partition,完全可以在Hive里面可以去查到的。
基本上这就是这完整的一套实时转数仓方案。我们基于这一套方案,在百度内部已经推广到了很多业务上。在百度内部还有很多细粒度的权限处理使用实时转数仓方案。一旦写入数仓,下游在订阅的时候会有一些数据脱敏,或者是读写权限控制,或者列权限控制,都能用这套方案进行控制,所以实时转数仓方案在百度内部还是比较受欢迎的。
实时转大屏展示
我们在推广过程中,用户是也些大屏展示的使用场景的。
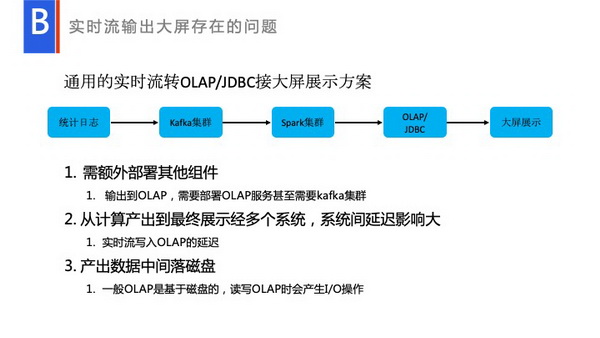
这页显示的这是一个通用的用户使用场景,比如说将Streaming实时的数据输出到一个OLAP里面,最终展示给大屏。但是这个场景有什么问题呢?这里需要额外使用其他的系统,比如Kafka系统、OLAP系统,最后再接入到大屏展示里面。每个系统,都需要找不同的负责人去处理,中间一旦出问题,需要反复去找负责人,与他们相互协调。中间会很复杂,一旦有一个网络出现故障,数据就会延时,负责人都需要处理自己的业务瓶颈。处理瓶颈是在用户使用场景中比较难办的问题。
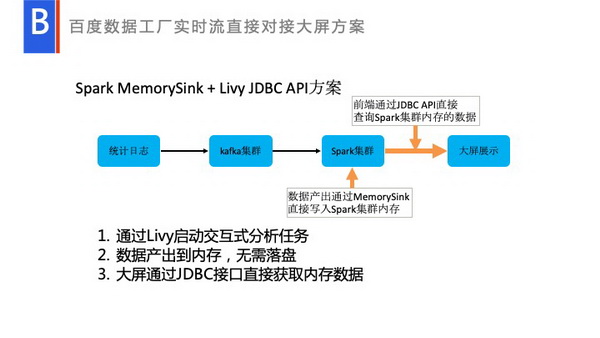
我们是如何处理呢?现有的一套解决方案提供了一套原生的基于SparkSQL,Sparkshell的系统。我们自研了一套就是交互式的分析,可以在本地,通过LivyJBDCAPI,当用户select*或者什么的时候,它完全可以交互式的提交到集群上处理,然后反馈给用户。这时候结合SparkMemorySink去处理,将数据进行一些复杂的分析,具体的业务逻辑处理之后,它会将数据写入到集群内存里面。前端通过LivyJDBCAPI去交互式的去查询Spark集群内存的数据。这样数据是直接落到集群内存的,没有任何产出,是保存在内存里面的。Livy去查的时候直接从里面去拿出来,相当于直接走内存,不会走经过落盘,网络等。这套方案就在实时处理和部署上,比较受欢迎。
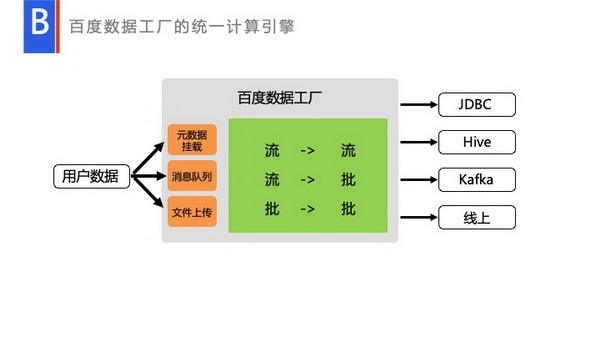
然后这就是,我们整个的流批的处理,用户通过各种方式传输数据,我们经过流到流,或者是流到批,或者是批到批的处理,当然中间我们可以完全映射成Table,就是流式的Table到批的Table,再到具体的业务输出方。或者流式的Table到流式的Table,或者是批的Table的到批的Table,这完全是OK的。
流式数据处理在百度数据工厂的实践
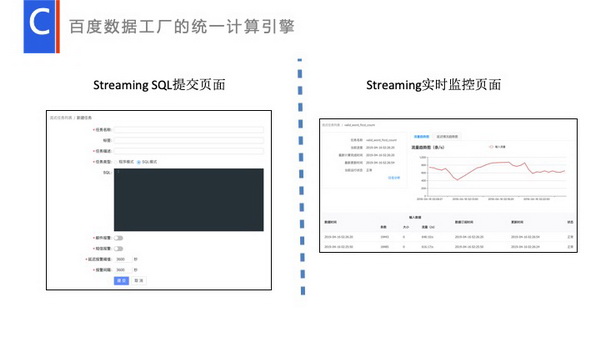
基于这套数据处理,我给大家简单介绍一下百度内部的一些实践。下图是流式的第一版本的产品化界面。我们已经在设计第三版了。左边是一个流式SQL的一个提交界面,用户可以在里面添加SQL,右边是流式监控。和现在Spark比较,和Spark监控页面比较类似的,监控当天有什么数据,显示实际处理量、数据时延等。
广告物料分析实践案例是我们一个比较典型的流批处理的使用场景。在实际的产品运维过程中,存在广告主投放广告的场景。广告主投放广告付钱是要看真实的点击率、曝光率和转化率的,而且很多广告主是根据曝光量、点击量、转化量来付钱的。
这种情况下,我们就需要专门针对广告物料进行分析,根据点击、曝光日志和转化数据生成广告的pv、uv、点击率和转化率,并根据计费数据生成广告收益。
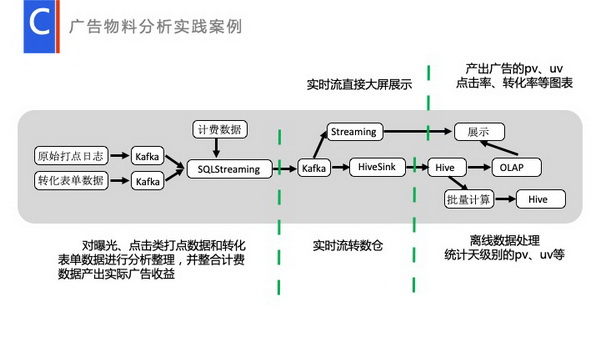
可以看到我们会通过Streaming直接输出到大屏展示。广告主会直接看到实时的用户量、当前的产出、收益。另外一部分数据产出到离线里面,通过实时转离线输出出来,进行一个日级别,天级别的分析,生成一些天级别,还有月级别的一些PV量,供后台做策略人员分析,以调整广告的投放策略。
讲师:李俊卿,百度高级研发工程师,数据工厂流式数据处理负责人。

时间:2019-06-20 23:55 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















