用Numpy搭建神经网络第二期:梯度下降法的实现
这一期,为大家带来梯度下降相关的知识点,和上一期一样,依然用Numpy实现梯度下降。在代码开始之前,先来普及一下梯度下降的知识点吧。
梯度下降:迭代求解模型参数值
第一期文章中提到过,最简单的神经网络包含三个要素,输入层,隐藏层以及输出层。关于其工作机理其完全可以类比成一个元函数:Y=W*X+b。即输入数据X,得到输出Y。
如何评估一个函数的好坏,专业一点就是拟合度怎么样?最简单的方法是衡量真实值和输出值之间的差距,两者的差距约小代表函数的表达能力越强。
这个差距的衡量也叫损失函数。显然,损失函数取值越小,原函数表达能力越强。
那么参数取何值时函数有最小值?一般求导能够得到局部最小值(在极值点处取)。而梯度下降就是求函数有最小值的参数的一种方法。
梯度下降数学表达式
比如对于线性回归,假设函数表示为hθ(x1,x2…xn)=θ0+θ1x1+..+θnxn,其中wi(i=0,1,2...n)为模型参数,xi(i=0,1,2...n)为每个样本的n个特征值。这个表示可以简化,我们增加一个特征x0=1,这样h(xo,x1,.…xn)=θ0x0+θ1x1+..+θnxn。同样是线性回归,对应于上面的假设函数,损失函数为(此处在损失函数之前加上1/2m,主要是为了修正SSE让计算公式结果更加美观,实际上损失函数取MSE或SSE均可,二者对于一个给定样本而言只相差一个固定数值):
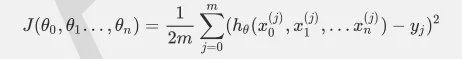
算法相关参数初始化:主要是初始化θ0,θ1..,θn,我们比较倾向于将所有的初始化为0,将步长初始化为1。在调优的时候再进行优化。
对θi的梯度表达公式如下:
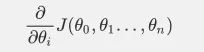
用步长(学习率)乘以损失函数的梯度,得到当前位置下降的距离,即:
梯度下降法的矩阵方式描述
对应上面的线性函数,其矩阵表达式为:
损失函数表达式为:
其中Y为样本的输出向量。
梯度表达公式为:
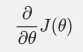
还是用线性回归的例子来描述具体的算法过程。损失函数对于向量的偏导数计算如下:
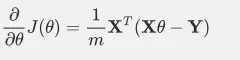
迭代:
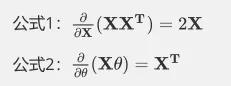
两个矩阵求导公式为:
用Python实现梯度下降

导入两个必要的包。

定义标准化函数,不让过大或者过小的数值影响求解。
定义梯度下降函数:
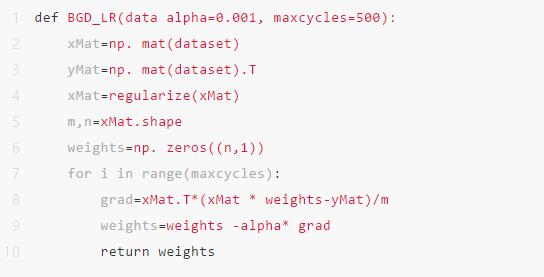
其中,dataset代表输入的数据,alpha是学习率,maxcycles是最大的迭代次数。
即返回的权重就是说求值。np.zeros 是初始化函数。grad的求取是根据梯度下降的矩阵求解公式。
本文参考B站博主菊安酱的机器学习。感兴趣的同学可以打开链接观看视频哟~
https://www.bilibili.com/video/av35390140
好了,梯度下降这个小知识点就讲解完了,下一期,我们将第一期与第二期的知识点结合,用手写数字的数据完成一次神经网络的训练。
作者:蒋宝尚

时间:2019-06-05 23:35 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]Python,Numpy,Pandas…数据科学家必备排序技巧
- [数据挖掘]如何可视化BERT?你需要先理解神经网络的语言、
- [数据挖掘]手工计算神经网络第三期:数据读取与完成训练
- [数据挖掘]TensorFlow什么的都弱爆了,强者只用Numpy搭建神经
- [数据挖掘]【深度学习】训练深度神经网络的方法 从数据预
- [数据挖掘]Python数据分析笔记——Numpy、Pandas库
- [数据挖掘]如何用PyTorch实现递归神经网络?
- [数据挖掘]DeepMind解密黑箱第一步:原来神经网络的认知原理
- [数据挖掘]GNMT-谷歌的神经网络翻译系统
- [数据挖掘]如何用进化方法优化大规模图像分类神经网络?
相关推荐:
网友评论:















