Uber如何为大规模Apache Hadoop表实现一致性数据分区
导读:为了可靠且一致地找到数据的位置,本文作者及其同事开发了一个名为全局索引(Global Index)的组件。这个组件负责在 Hadoop 表中簿记(bookkeeping)并查找数据位置。它提供了高吞吐量、强一致性和水平可扩展能力,并帮助用户更好地更新 Hadoop 表中数以 PB 计的数据。
本文作为对之前大数据博客系列文章(https://eng.uber.com/tag/big-data/)的扩展,将会阐述解决如此大规模问题所涉及的挑战,并分享如何利用开源软件解决这些问题的经验。

找不到的数据是没有价值的。优步积累的数据量超过 100PB,从这些数据中挖掘到的信息能够帮助我们不断进步,获得有价值的见解以改善我们的服务——例如为骑手提供更精确的到达时间预测,或向食客展示他们最爱的食品类别等等。查询如此大规模的数据库并及时提供结果并非易事,但只有达成这一目标,才能让优步的团队获得足够的洞察力,从而为客户提供出色的无缝体验。
为了实现上述目标,我们通过分离存储和查询层来构建优步的大数据平台(https://eng.uber.com/uber-big-data-platform/),以使存储和查询层都可以独立扩展。我们在 HDFS 上存储分析数据集,将它们注册为外部数据表,并使用 Apache Hive、Presto 和 Apache Spark 等查询引擎为它们服务。这个大数据平台为团队提供了可靠且可扩展的分析能力,以保证我们的服务准确无误,并得到持续的改进。
在优步出行服务的整个生命周期中,在诸如行程创建、出行时间更新和车手审查更新等事件期间就会有新的信息更新到行程数据中。为实现这类更新,需要在修改和保存数据之前查找数据的位置。当这类查找行为增加到每秒数百万次操作的规模时,我们发现开源键值存储已经无法满足我们的可扩展需求了——它们要么无法满足吞吐量要求,要么会损失精确度。
为了可靠且一致地找到数据的位置,我们开发了一个名为全局索引(Global Index)的组件。这个组件负责在 Hadoop 表中簿记(bookkeeping)并查找数据位置。它提供了高吞吐量、强一致性和水平可扩展能力,并帮助我们更好地更新 Hadoop 表中数以 PB 计的数据。本文作为对之前大数据博客系列文章(https://eng.uber.com/tag/big-data/)的扩展,将会阐述解决如此大规模问题所涉及的挑战,并分享我们利用开源软件解决这些问题的经验。
数据引入的负载类型
优步的 Hadoop 数据大致可分为两种类型:仅附加(append-only)和附加并更新(append-plus-update)。仅附加数据代表不可变事件。在优步术语中,不可变事件可能包含行程的付款历史记录。附加并更新数据显示任意给定时间点的实体最新状态。例如,在行程结束时间的实例中,其中行程是实体,结束时间是对实体的更新;结束时间是估测的,直到行程结束之前都可以变动。
由于每个事件是独立的,因此引入仅附加数据不需要任何前值的上下文。但将附加并更新数据引入到数据集就不一样了。虽然我们收到的数据更新只涉及数据的部分内容,但我们仍需要提供最新且完整的行程快照。
附加并更新数据的负载
数据集构建通常有两个阶段:bootstrap(引导)和 incremental(增量)。在引导阶段,来自上游的大量历史数据会在短时间内引入完毕。一般来说这一阶段出现在数据集首次上线或重启维护期间。增量阶段会接收来自上游的最新增量改动并将其应用于数据集。数据集生命周期的大部分时间都处于这一阶段,以确保数据同上游来源同步更新。
数据引入的本质就是对数据做组织优化,从而取得读取性能和新数据写入性能的平衡。为了提升读取性能,一种优化措施是对数据分区后再做查询,从而尽量减少每次查询需要读取的数据量。由于分析数据集往往会读取很多次,所以分区后就不需要扫描整个数据集了。为了提升写入性能,数据布局会分布在不同分区内的多个文件中,以实现并行写入操作;而且将来更新数据时,只需要向包含更新内容的文件写入新数据就行了。
提升数据更新时写入性能的另一个办法是开发一个组件,用来快速查找我们的大数据生态系统中现有数据的位置。这个引入组件名为全局索引,负责维护数据布局的簿记信息。该组件需要强一致性才能正确判断接收的数据属于插入还是更新类型。在分类时,插入数据(例如我们的新行程)会被分组并写入新文件,而更新数据(例如行程的结束时间)将写入由全局索引标识的对应预设文件,如下图 1 所示:
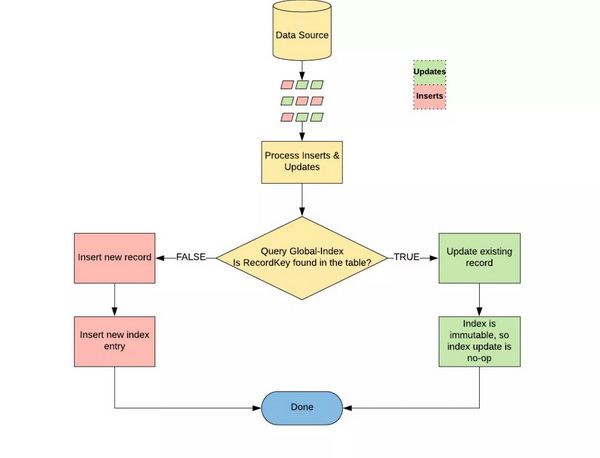
图 1:在我们的引入流程中,全局索引对数据集的插入和更新数据做分类,还要查找需要写入的对应文件以实现更新。
下图是全局索引在数据引入体系中的功能示意。
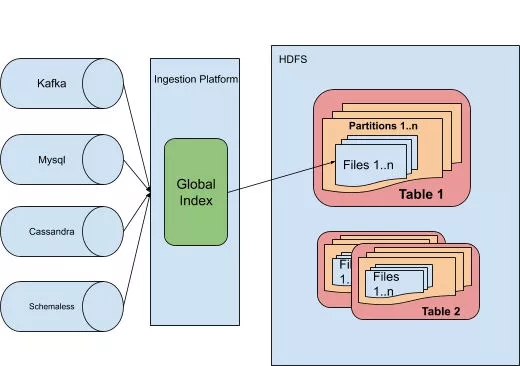
图 2:优步的数据架构示意图,展示全局索引如何集成到数据引入平台。
要实现全局索引,常见的解决方案是使用主流的键值存储技术,诸如 HBase(https://hbase.apache.org/)或 Cassandra(http://cassandra.apache.org/)等。这类键值存储可以支持每秒数十万,具备强一致性的读 / 写请求(https://academy.datastax.com/planet-cassandra/nosql-performance-benchmarks)。
对于大型数据集而言,引导阶段的吞吐量需求(每个数据集每秒数百万个请求的数量级)非常高,因为需要在相对较短的时间内引入大量数据。在优步的大型数据集的引导阶段,吞吐量需求约为每秒数百万个请求。但在增量阶段,吞吐量需求要低得多(每个数据集每秒数千个请求),偶尔出现的高峰期也可以通过请求速率限制来控制。
全局索引的其它需求包括大规模索引读 / 写、强一致性和合理的索引读 / 写放大等。如果我们将面临的挑战划分为引导阶段索引和增量阶段索引,就可以使用一个扩展的键值存储解决增量阶段的索引问题,但引导阶段的索引可能会另寻出路。要深入理解这种策略的背景,我们要先搞明白两个阶段面临的负载差异。
引导阶段数据引入的索引
在引导阶段,如果源数据是处理优化过的,保证所有的输入数据都是插入类型(如图 1 所示),那就不需要全局索引了。但在增量阶段,我们无法确保输入的数据都是插入类型的,因为我们必须定期引入数据,随时都可能引入对某行数据的更新。因此在增量阶段开始之前需要使用索引来更新键值存储。
我们用这个属性来设计引导阶段的数据引入架构。由于键值存储的请求吞吐量有限,我们从数据集生成索引,并将它们批量上载到键值存储,避免碎片化的写入请求,这样就消除了典型的写入性能瓶颈。
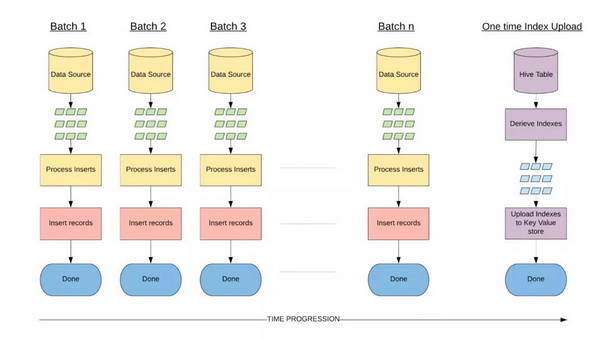
图 3:在引导数据引入期间对源数据分组以使其不包含更新内容,此时可以跳过全局索引步骤。引导数据引入完成后,对应的索引会批量上传到 HBase,使数据集做好准备进入下一阶段,即增量数据引入。
选择合适的键值存储方案
基于上述优化策略,在增量阶段用于索引的键值存储需要强一致性的读 / 写能力,且能够扩展到每个数据集每秒数千个请求的规模,还要有可靠的索引批量上传策略(例如设法避免写入性能瓶颈)。
HBase 和 Cassandra 是优步常用的两个键值存储方案。我们选择使用 HBase 来做全局索引,原因如下:
与 Cassandra 不同,HBase 只允许一致的读写,因此不需要调整一致性参数。
HBase 提供群集中 HBase 表的自动重平衡能力。其主从架构允许获取跨集群传播的数据集的全局视图,这个视图能帮助我们定制每个 HBase 集群的数据集吞吐量。
使用 HFiles 生成和上传索引
我们以 HBase 的内部存储文件格式 HFile(https://blog.cloudera.com/blog/2012/06/hbase-io-hfile-input-output/)生成索引,并将它们上传到我们的 HBase 集群。HBase 基于区域服务器(https://mapr.com/blog/in-depth-look-hbase-architecture/)上的有序、非重叠键范围,使用 HFile 文件格式分区数据。数据在每个 HFile 中根据键值和列名排序。为了以 HBase 期望的格式生成 HFile,我们使用 Apache Spark 在一组机器上执行大规模分布式操作。
首先从引导数据集中将索引信息提取为弹性分布式数据集(RDD),如下面的图 4 所示,然后基于键值使用 RDD.sort() 做全局排序。

图 4:我们的大数据生态系统中,存储在 HBase 中的索引模型包含的实体是绿色部分,这些实体有助于识别需要更新的文件,这些文件对应附加并更新数据集中的指定记录。
我们布局 RDD 的方式是让每个 Apache Spark 分区负责独立写出一个 HFile。在每个 HFile 中,HBase 期望内容按照下面的图 5 所示布置,以便根据键值和列名对它们进行排序。
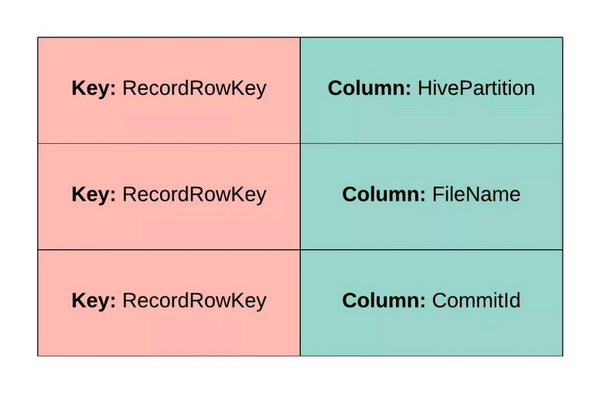
图 5:HFile 中索引条目的布局允许我们根据键值和列进行排序。
然后对 RDD 应用 RDD.flatMapToPair() 转换,以组织图 5 所示布局中的数据。但此转换不保留 RDD 中条目的顺序,因此我们使用 RDD.repartitionAndSortWithinPartitions() 执行分区隔离排序,但不对分区做任何更改。不更改分区是很重要的,因为每个分区都已经被选定来表示 HFile 中的内容了。然后使用 HFileOutputFormat2 保存生成的 RDD。使用这种方法后,我们的一些索引高达数十 TB 的超大规模数据集只需不到两个小时就能生成 HFile。
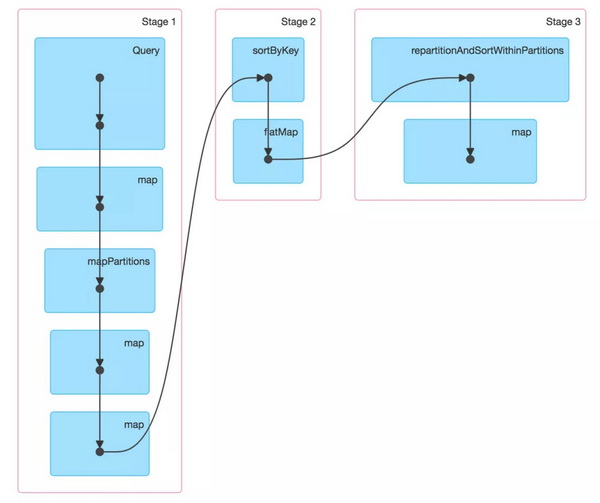
图 6:Apache Spark 中的 FlatMapToMair 转换不保留条目的顺序,因此要执行分区隔离排序。分区不做更改以确保每个分区仍然对应于非重叠的键范围。
现在使用名为 LoadIncrementalHFiles 的功能将 HFile 上载到 HBase。如果没有完全包含 HFile 中键范围的预设区域,或者 HFile 尺寸大于设定阈值,则在 HBase 上传期间会触发称为 HFile-splitting(HFile 分裂)的过程。
分裂会严重影响 HFile 的上传速度,因为此过程需要重写整个 HFile。我们通过读取 HFile 键范围并将 HBase 表预分割成与 HFile 一样多的区域来避免 HFile 分裂,这样每个 HFile 都能适配一个区域。只读取 HFile 键范围比重写整个文件消耗的资源少几个数量级,因为 HFile 键范围是存储在标头块中的。对于我们的一些索引高达数十 TB 的大规模数据而言集,上传 HFile 只需不到一个小时。
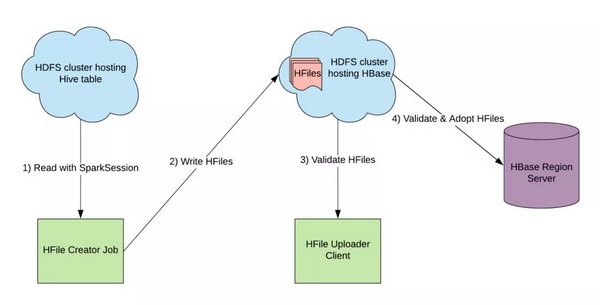
图 7:HFile 被写入托管 HBase 的集群,以确保 HBase 区域服务器在上传过程中可以访问它们。
增量引入期间的索引
生成索引后,每个行键和文件 ID 之间的映射就不会更改了。我们不会索引批量引入的所有记录,而是仅索引插入数据。这样我们就能把 HBase 的写入请求控制在性能限制范围内,并满足我们的吞吐量需求。
限制 HBase 访问
如前所述,HBase 的扩展能力是有极限的。在增量阶段偶尔会出现峰值负载,因此我们需要限制对 HBase 的访问。下面的图 8 显示了多个独立的引入作业如何同时访问 HBase:
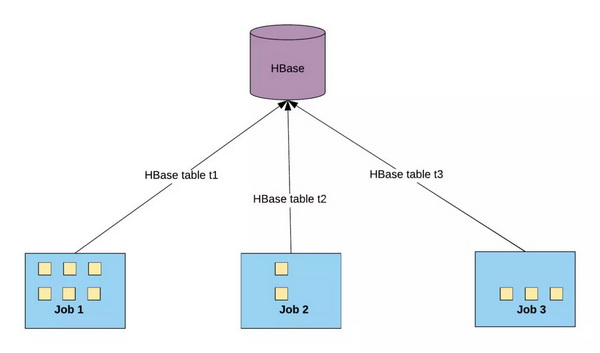
图 8:对应于三个不同数据集的三个 Apache Spark 作业访问其各自的 HBase 索引表,在托管这些表的 HBase 区域服务器上创建负载。
我们根据影响 Hbase 请求数量的几个因素,控制独立 Apache Spark 作业对区域服务器的每秒累积写入速度:
1、作业并行度:作业中 HBase 的并行请求数。
2、区域服务器数量:托管特定 HBase 索引表的服务器数量。
3、输入 QPS 积分:跨数据集的累积 QPS 的积分。一般来说,这个积分是数据集中行数的加权平均值,以确保跨数据集的 QPS 的公平份额。
4、内部测得的 QPS:区域服务器可以处理的 QPS。
下面的图 9 显示了当 HBase 区域服务器添加到 HBase 集群时,调整限制算法以处理更多查询的一次实验。
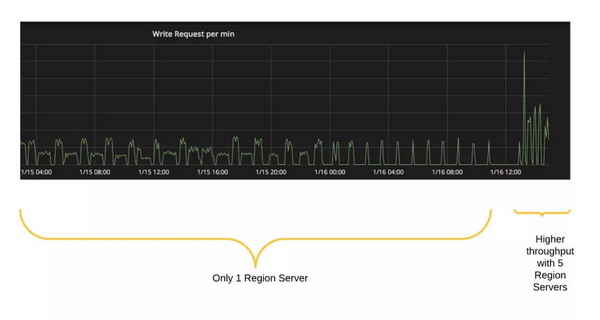
图 9:尽管数据集的 QPS 积分保持不变,但随着一个 HBase 集群中的服务器数量增加,使用全局索引的单个数据集也能获得线性的 QPS 增长。
系统限制
虽然我们的全局索引系统有助于提高数据的可靠性和一致性,但它也存在一些局限性,如下所述:
根据 CAP 定理(https://en.wikipedia.org/wiki/CAP_theorem),HBase 提供了一致性和分区容错能力,但无法提供 100%的可用性。由于引入作业对时间不是非常敏感,因此我们可以在少见的 HBase 停机期间以较宽松的条件处理作业。
限制流程假定索引表均匀分布在所有区域服务器上。但对于只包含少量索引的数据集,情况可能并非如此。这种情况下它们得到的 QPS 份额就不够,所以我们要提高其 QPS 积分来做补偿。
如果 HBase 中的索引已损坏或表因灾难事件而变得不可用,则需要灾难恢复机制。我们当前的策略是重用前述过程,从数据集生成索引并上传到新的 HBase 集群。
未来展望
我们的全局索引方案使数以 PB 计的数据能够运行在优步的大数据平台上,满足我们的 SLA 和需求。但我们也在考虑一些改进措施:
例如,我们通过确保引入仅附加类型的数据简化了引导引入阶段的全局索引问题,但这可能不适用于所有的数据集。因此,我们需要一个解决此问题的可扩展解决方案。
我们希望探索出一种索引解决方案,可以不再需要 HBase 等键值存储一类的外部依赖。
作者:Nishith Agarwal,Kaushik Devarajaiah
译者:王强编辑 Vincent
查看英文原文:https://eng.uber.com/data-partitioning-global-indexing/

时间:2019-05-30 00:16 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















