10个数据科学家常犯的编程错误(附解决方案)
数据科学家是“比软件工程师更擅长统计学,比统计学家更擅长软件工程的人”。许多数据科学家都具有统计学背景,但是在软件工程方面的经验甚少。我是一名资深数据科学家,在Stackoverflow的python编程方面排名前1%,并与许多(初级)数据科学家共事。以下是我经常看到的10大常见错误,本文将为你相关解决方案:
♦ 不共享代码中引用的数据
♦ 对无法访问的路径进行硬编码
♦ 将代码与数据混合
♦ 在Git中和源码一起提交数据
♦ 编写函数而不是DAG
♦ 写for循环
♦ 不编写单元测试
♦ 不写代码说明文档
♦ 将数据保存为csv或pickle文件
♦ 使用jupyter notebook
1. 不共享代码中引用的数据
数据科学需要代码和数据。因此,为了让别人可以复现你的结果,他们需要能够访问到数据。道理很简单,但是很多人忘记分享他们代码中的数据。

解决方案:使用d6tpipe(https://github.com/d6t/ d6tpipe)来共享你的代码中的数据文件、将其上传到S3/web/google驱动等,或者保存到数据库,以便于别人可以检索到文件(但是不要将其添加到git,原因见下文)。
2. 对无法访问的路径进行硬编码
与错误1相似,如果你对别人无法访问的路径进行硬编码,他们将无法运行你的代码,并且必须仔细查看代码来手动更改路径。令人崩溃!
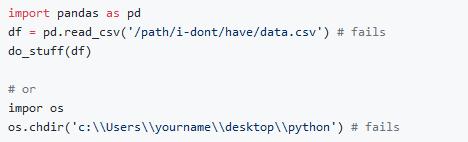
解决方案:使用相对路径、全局路径配置变量或d6tpipe,使你的数据易于访问。
d6tpipe:
https://github.com/d6t/d6tpip
3. 将代码与数据混合
既然数据科学的代码中包含数据,为什么不把它们放到同一目录中?那样你还可以在其中保存图像、报告和其他垃圾。哎呀,真是一团糟!
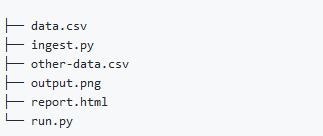
解决方案:将你的目录进行分类,比如数据、报告、代码等。请参阅Cookiecutter Data Science或d6tflow项目模板[见#5],并使用#1中提到的工具来存储和共享数据。
Cookiecutter Data Science:
https://drivendata.github.io/cookiecutter-data-science/
d6tflow项目模板:
https://github.com/d6t/d6tflow-templat
4. 在Git中和源码一起提交数据
现在,大多数人对他们的代码使用版本控制(如果你不使用,那就是另外一个错误,请参阅git:https://git-scm.com/)。在尝试共享数据时,很容易将数据文件添加到版本控制中。当文件很小时是可以的,但是git并没有针对数据进行优化,尤其是大文件。

解决方案:使用第1点中提到的工具来存储和共享数据。如果你真的希望对数据进行版本控制,请参阅 d6tpipe,DVC和Git大文件存储。
d6tpipe:
https://github.com/d6t/d6tpipe
DVC:
https://dvc.org/
Git大文件存储:
https://git-lfs.github.com
5. 编写函数而不是DAG
关于数据部分已经够多了,现在来谈一谈实际的代码!在学习编程时最先学习的内容之一就是函数,数据科学代码通常由一系列线性运行的函数组成。
这会导致一些问题,请参阅“为什么你的机器学习代码可能不好的4个原因”:
https://github.com/d6t/d6t-python/blob/master/blogs/reasons-why-bad-ml-code.rst

解决方案:数据科学代码不是一系列线性连接的函数,而是一组具有依赖关系的任务集合。请使用d6tflow或airflow。
d6tflow:
https://github.com/d6t/d6tflow-template
airflow:
https://airflow.apache.org
6. 写for循环
与函数类似,for循环也是你学习编程时最初学习的内容。它们易于理解,但是运行缓慢且过于冗长,通常意味着你不了解矢量化的替代方案。
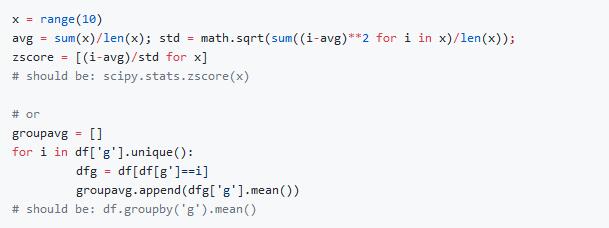
解决方案:Numpy,scipy和pandas为你需要for循环的情况提供了矢量化函数。
Numpy:
http://www.numpy.org/
scipy:
https://www.scipy.org/
pandas:
https://pandas.pydata.org
7. 不编写单元测试
随着数据、参数或用户输入的改变,你的代码可能会出现问题,有时你并没有注意到。这可能会导致糟糕的输出结果,而如果有人基于你的输出做出决策,那么糟糕的数据将会导致糟糕的决策。
解决方案:使用assert语句来检查数据质量。pandas有相等测试,d6tstack有数据提取检查以及用于数据连接的d6tjoin。
pandas相等测试:
https://pandas.pydata.org/pandas-docs/stable/reference/general_utility_functions.html
d6tstack:
https://github.com/d6t/d6tstack
d6tjoin:
https://github.com/d6t/d6tjoin/blob/master/examples-prejoin.ipyn
以下是数据检查的示例代码:

8. 不写代码说明文档
我明白,你急着做出一些分析结果。你把事情汇总到一起分析,将结果交给你的客户或老板。一个星期之后,他们回来说,“可以把XXX改一下吗”或者“可以更新一下这里吗”。你看着你的代码,但是并不记得你当初为什么这么写。现在就像是在运行别人的代码。

解决方案:即使在你已经提交分析报告后,也要花费额外的时间,来对你做的事情编写说明文档。以后你会感谢自己,别人更会感谢你。那样显得你很专业!
9. 将数据保存为csv或pickle文件
回到数据,毕竟是在讲数据科学。就像函数和for循环一样,CSV和pickle文件很常用,但是并不好用。CSV文件不包含纲要(schema),因此每个人都必须再次解析数字和日期。Pickle文件解决了这个问题,但是它只能在python中使用,并且不能压缩。两者都不是存储大型数据集的最优格式。

解决方案:使用parquet或其他带有数据纲要的二进制数据格式,在理想情况下可以压缩数据。d6tflow将任务的数据输出保存为parquet,无需额外处理。
parquet:
https://github.com/dask/fastparquet
d6tflow:
https://github.com/d6t/d6tflow-template
10. 使用jupyter notebook
最后一个是颇有争议的错误:jupyter notebook和csv文件一样普遍。许多人使用它们,但是这并不意味着它们很好。jupyter notebook助长了上述提到的许多不良编程习惯,尤其是:
♦ 把所有文件保存在一个目录中
♦ 编写从上至下运行的代码,而不是DAG
♦ 没有对代码进行模块化
♦ 很难调试
♦ 代码和输出混在一个文件中
♦ 没有很好的版本控制
♦ 它容易上手,但是扩展性很差。
解决方案:使用pycharm和/或spyder。
pycharm:
https://www.jetbrains.com/pycharm/
spyder:
https://www.spyder-ide.org
作者简介:Norman Niemer是一家大规模资产管理公司的首席数据科学家,他在其中发布数据驱动的投资见解。他有哥伦比亚大学的金融工程专业理学硕士学位,和卡斯商学院(伦敦)的银行与金融专业理学学士学位。
原文标题:Top 10 Coding Mistakes Made by Data Scientists
原文链接:https://github.com/d6t/d6t-python/blob/master/blogs/top10-mistakes-coding.md

时间:2019-05-26 00:45 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















