谈谈使用开源软件搭建数据分析平台
在过去的三年,开源社区和新技术的发展可谓日新月异,我希望试试利用最新的技术来帮助没有数据科学背景的人也能够轻松的进行数据分析和预测,于是就有了dataplay3 。
架构
老规矩,先上架构图:
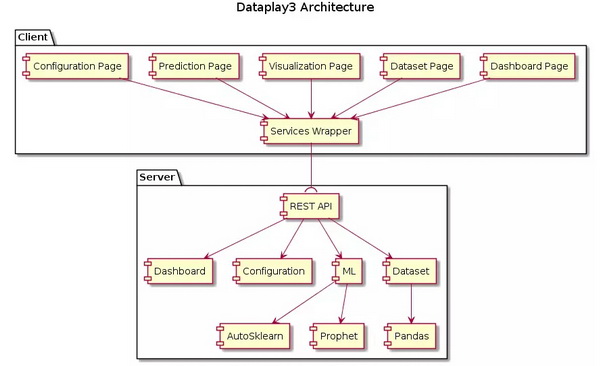
为了构建一个最简单的开箱即用的数据分析平台,我使用了如下的技术栈:
服务器端:
sanic 基于Python3的web服务器
pandas Python上最流行的数据分析库
auto-sklearn 基于sklearn的自动机器学习库
prophet 非死不可开源的时间序列分析库
pandassql 能够在Panda数据框上运行SQL的库
gunicorn 基于python的WSGI HTTP服务器
客户端:
React 前端框架
Ant Design Pro 蚂蚁开源的企业级应用框架套装
Ant Design
UmiJS
Dva
BizCharts 基于G2和React的可视化库
G2 The Grammar of Graphics in JavaScript
功能
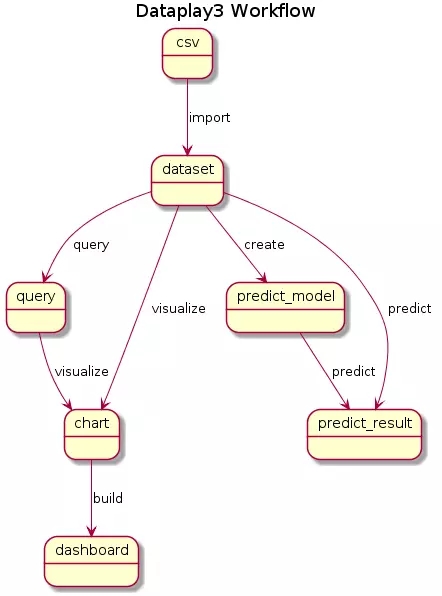
Dataplay3提供了数据分析的基本功能,希望尽可能的简化用户数据分析的复杂性。
基于Pandas的数据集管理
基于SQL和Pands的查询
基于Grammar of Graphics的可视化
简单的仪表盘
基于自动化机器学习, 提供数值和分类数据的建模和预测
时间序列分析
这里上几个功能截图,具体功能请参考 https://gangtao.github.io/dataplay3/features
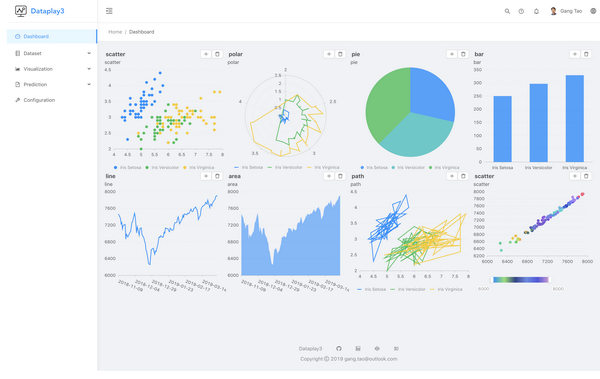
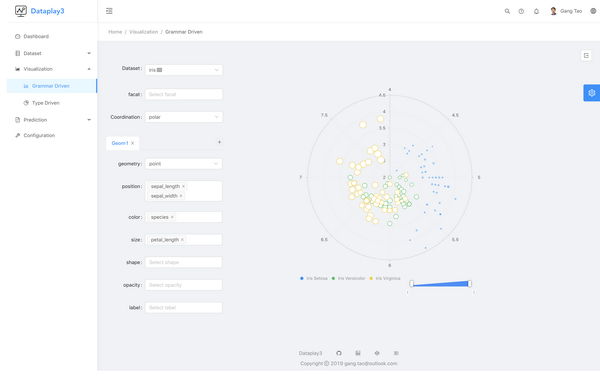
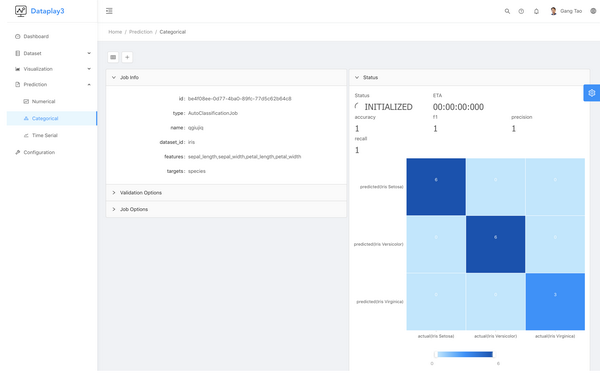
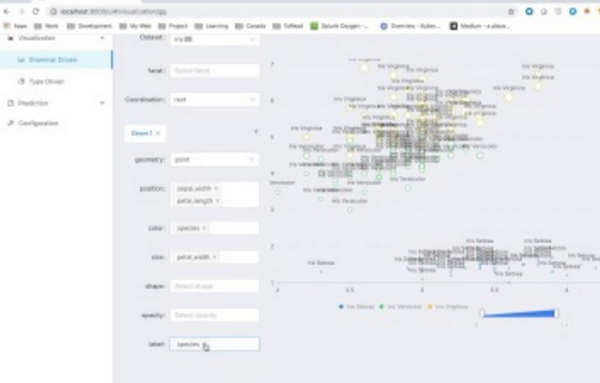
或者参考这个视频介绍
对架构和功能的思考
前端
React毫无疑问非常流行,Vue同样优秀。我这里不想讨论和比较。
对于React的前端栈而言,现在开发工具的过程都已经非常成熟。基于Redux的状态管理解决了前端状态管理的大难题。但是即便如此,开发一个产品,无论是代码量还是所花费的时间来说,前端的工作都占据了开发的大头。作为一个前端的开发人员,你需要了解:
最新的ES6的规范 推荐https://es6.ruanyifeng.com/
React和redux
使用webpack打包你的应用
使用Less扩充你的css
浏览器的知识
... ...
为了更容易上手,我选择使用了蚂蚁开源的 Ant Design Pro,用框架的好处是你不需要太多的设计,基本的模式照着用就好了,缺点呢,就是有些功能框架包装的太多,你想实现一些自己想要的功能呢就比计较困难。所以对于用不用框架,取决于你对于代码希望掌控的程度。
Ant Design Pro构建于:
UmiJS 中文可发音为乌米,是一个可插拔的企业级 react 应用框架。umi 以路由为基础的,支持类 next.js 的约定式路由,以及各种进阶的路由功能,并以此进行功能扩展,比如支持路由级的按需加载。然后配以完善的插件体系,覆盖从源码到构建产物的每个生命周期,支持各种功能扩展和业务需求,目前内外部加起来已有 50+ 的插件。
Dva 基于 redux、redux-saga 和 react-router 的轻量级前端框架。
我个人比较喜欢的Ant Design Pro的功能是测试这一块,通过mock服务器请求,前后端的开发可以分离,这个很方便。基于Rest API的前端开发的过程基本如下:
定义REST API
在前端实现REST API调用的异步请求,(利用Axios HTTP request)
实现前端的接口Mock
定义页面对应的模型Model,并实现状态的管理
绑定模型到页面,实现页面功能
可视化
Dataplay2使用echart作为可视化库,而Dataplay3使用了蚂蚁的G2,在我的前一篇博文中我就提到:
Baidu的echart是非常优秀的可视化库,可是用于数据探索时,还不够好。希望能有一套类似ggplot的前端可视化库来使用。
令人高兴的是,这个类似ggplot的前端可视化库已经有了,它就是蚂蚁的G2。这里我要称赞一下我的北邮校友林峰,他同时也是echart的作者。他领导的团队开发出了世界领先的可视化库,G2是其中之一。我认为G2已经超越了echart,希望他们能够越做越好!
作为语法驱动的图形,对于用户的使用是一个挑战,所以,在Dataplay3中同时提供了基于图标类型的可视化。
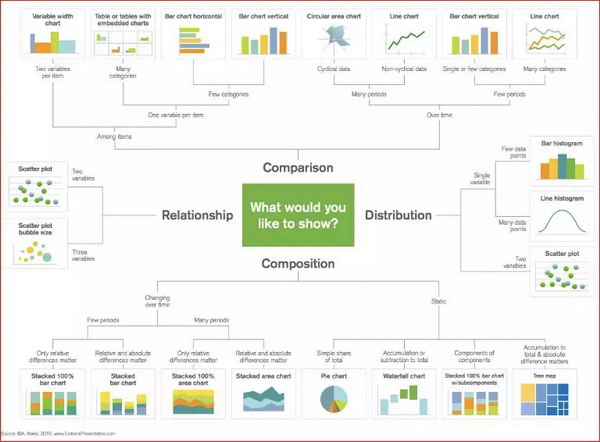
利用图形语法,新的图表类型可以用一个配置项来扩展,例如,对于Area chart的配置如下:

现在Dataplay3支持的图形种类还不多,后面,我可能会加入更多的类型。
后端
对于后端Python应用来说,全面拥抱Python3是必然选择。对于Web服务,Sanic是一个不错的选择,它基本继承了Flask的所有优点,但是提供了Async的支持,能够提供能好的服务性能,当然选择一个新的框架必然有风险。参考这篇文章,Sanic 的若干吐槽
Dataplay3仍然使用REST API而没有使用最新很流行的Graphql, 对于这个选择,大家也可以根据自己的应用来做决定。可以参考GraphQL vs. REST
机器学习
因为希望这是一款小白也能使用的数据分析工具,我希望提供的预测功能越简单越好,利用Auto-SKlearn,我们把机器学习的建模过程变得非常简单。用户只需要选择用于建模的数据,特征和目标就好了。用户不需要选择应用什么类型的算法,如果构建数据流水线,如何预处理数据,以及如果ensemb模型。唯一要考虑的是能够付出多少资源(时间,CPU,内存)来构建模型。

Auto-Sklearn的主要功能是:
利用元学习来选择算法的流水线
利用贝叶斯优化来选择参数
利用ensemble来构建复合的模型。
对于另一种常见的数据分析类型的时间序列,我选择了facebook开源的Prophet,(基于pystan构建)
Dataplay3还没有实现模型部署的功能,以后可能会考虑。
从全栈工程师到全生命周期工程师
因为更多的应用已经迁移到云或者在迁移到云的过程中,对于软件工程师而言,全栈已经不足以满足要求,现在需要的是全生命周期工程师,工程师不但要覆盖前后端的代码实现和测试,而且要参与软件生命周期的每一个部分,尤其是DevOps。
以Dataplay3为例,我需要做的事包括:
思考我想要解决什么问题,面向什么用户 -》 产品定义
设计软件架构 -》架构阶段
前后端的代码设计,选型 -》 设计阶段
前后端的实现和测试 -》 实现阶段
持续集成和部署 -》 CICD
部署后的运营和监控 , 产品的市场宣传 (例如我正在写的这篇文章)-》 运营阶段
这里,我主要讲一下CICD。DevOps和CICD在现在的软件生命周期中已经占据非常重要的地位。这篇文章提供了不少CICD的项目。
在Dataplay3中,我使用
CICD codeship
Automated code reviews & code analytics, codeacy
Automated code reviews & code analytics, ebert
CICD的服务不少,开源项目最为流行的可能是Travis CI。另外gitlab也即成了很好的CICD的功能。codeship因为拥有很好的容器的功能,也是一个很不错的选择。现在的dataplay3的CI之使用了codeship的基本功能。可以利用codeship的pro的功能,构建更为强大的CICD。codeship对于开源项目提供每月100次build的免费服务,对于一些开发密度不是很大的项目来说应该足够用了。
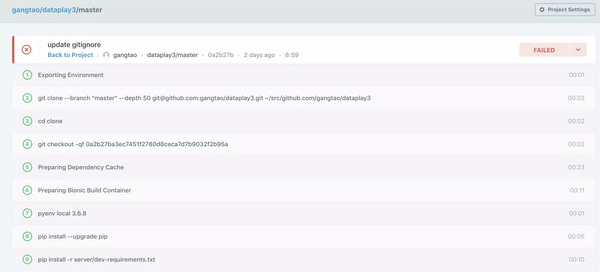
codacy和ebert都是自动化的代码分析工具,你只需要创建一个项目,连接到你的github项目,就可以在提交代码或者合并PR的时候进行自动的代码分析,这个一般是可以在CI中实现的,使用这些服务可以然你更容易的了解你的代码的质量变化。
总结
如果说dataplay只是一些很原始的想法,dataplay2最多算是一个原型,那么dataplay3应该是一个还算勉强可用的工具了,当然它现在还很简单,可能有很多的bug和问题,我也希望能慢慢地改进。
对于三年前的一些想法,Dataplay3也做出了回应
可视化库
Baidu的echart是非常优秀的可视化库,可是用于数据探索时,还不够好。希望能有一套类似ggplot的前端可视化库来使用。另外地图功能和层级化的图表也是数据分析常见的功能。
还需要加入图表的选项
仪表盘功能
这个版本的dataplay没有仪表盘功能,这个功能是数据分析软件的标配,必须有。pyxley似乎是个不错的选择,也和dataplay的架构一致(python,reactjs),有时间可以尝试一下
机器学习和预测
dataplay现在实现了最简单的一些机器学习的算法,我觉得方向应该是面向用户,变得更简单,用户只给出简单的选项,例如要预测的目标属性,和用于预测的属性,然后自动的选择算法。另外需要更方便的对算法进行扩展。
这要感谢开源作者们的无私奉献。另外的一些功能呢,因为本人精力有限,只能抽空慢慢的实现,如果有对数据科学,开源应用有兴趣的小伙伴,也欢迎给我提意见,提PR,报Bug。
最后重点发一下项目地址 https://github.com/gangtao/dataplay3

时间:2019-05-20 13:10 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















