网易大数据体系之时序数据技术

本次分享内容:
时序数据平台主要业务场景
时序数据平台体系架构
时序数据平台核心技术
PART01 时序数据平台主要业务场景
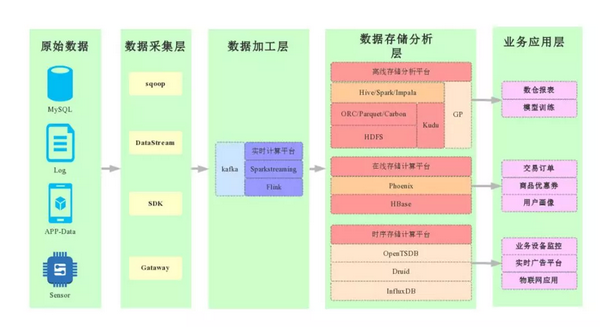
上图为数据的整体架构,大部分公司都是差不多的:
原始数据:MySQL、服务端的 Log、APP-Data、Sensor,大家知道现在穿戴设备很多,比如手表等,这样都会产生很多数据,这些数据都称为时序数据,随着时间的变化不断产生数据。
数据采集层:sqoop、DataStream、SDK、Gataway
数据加工层:数据存在 kafka 里,再经过一些流计算处理(Flink、Sparkstreaming)
数据存储分析层:
离线存储分析平台:技术栈包括最底层的 HDFS、Kudu、GP 等数据存储,在这之上要做很多的计算,包括 Hive、Spark、Impala 等,他的应用场景包括数仓报表、机器学习、模型训练等;
在线存储计算平台:应用的业务场景包括,交易订单,优惠券,用户画像等,这里主要应用的是 HBase;
时间序列存储计算平台:应用场景包括,业务设备监控,实时广告平台,物联网应用,相关的技术包括 OpenTSDB、Druid、InfluxDB 等。
所以会根据不同的业务使用不同的平台来处理相关的数据,对于我们来说最大的工作是在数据存储端。
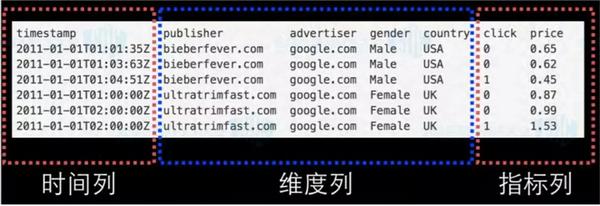
时序数据主要包括时间列、维度列和指标列,这 3 列缺一不可(特别是时间列)。
工业互联网时代,会源源不断产生各种各样的时序数据,时序数据平台有以下几种典型场景:
系统监控:
物理机、云主机、容器:CPU、内存、IO 等
组件服务:数据库集群、Kafka 集群、HBase 集群
任务监控:
查看指定 hadoop 任务耗用内存、CPU、IO 利用率等
查看集群消耗资源 TopN 任务、节点等
统计集群任务执行耗时
应用性能监控:
应用调用次数,错误占比,页面加载延迟统计、地域统计分析
慢加载追踪,慢 SQL
异常会话追踪
链路监控:
调用链全息排查
全局调用拓扑
链路依赖项分析梳理
业务监控统计:
a. 电商
业务大盘:查看单量,金额,发货等业务指标
异常大盘:查看超卖,库存校准耗时,商品回调耗时,各种类型下单错误等异常指标
b. 广告
广告曝光点击消耗实时统计
流量地域分配
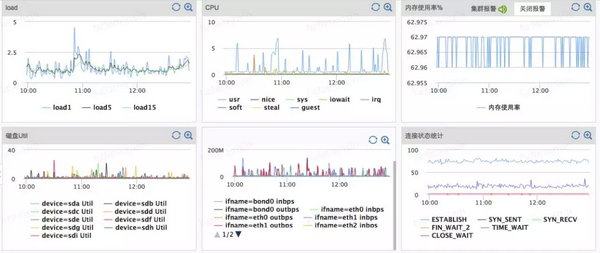
以基础系统监控服务为例,举例描述两个应用场景:
物理机基础硬件指标监控
HBase-RegionServe 指标监控
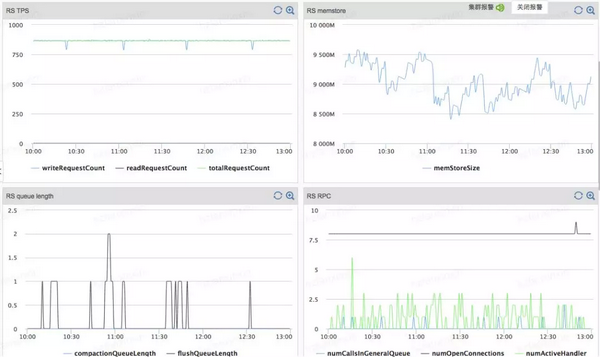
直观地看,以上数据的横坐标都是时间戳,即设备随着时间不断吐数据。
时序数据应用场景的核心特征:
时间区间查询,最近时间区的数据的查询频率远大于历史数据;
多维条件查询,即多维字段随机组合查询;
支持 TTL 机制,数据可以自动过期;
支持高压缩率,数据压缩比要达到 10 以上;
支持高效聚合;
支持集群可扩展,服务高可用,数据高可靠。
PART02 时序数据平台架构体系
时序序列平台以监控类系统体系架构为例,如下图所示:
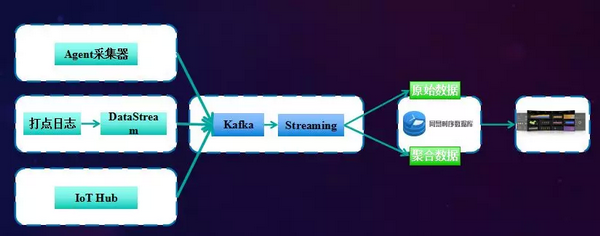
将多数据来源的数据(如 Agent 采集器,打点日志、流式数据,IoT Hub 等),通过 Kalfa 工具(分布式消息队列系统)进行流式处理,汇集到网易时序数据平台上。
PART03 时序数据平台核心技术
在上述架构体系中,数据库作为其核心环节。考虑到 DDB(分布式 MySQL)实时写入性能不足,HBase/ES 等开源 NoSQL 平台多维查询以及聚合计算等功能不够;针对海量时序数据这类应用场景,因此需要专门的时序数据库。
现有市场上较成熟的时序数据库主要包括 Druid、OpenTSDB、InfluxDB 等。网易结合以上各类时序数据库的优缺点,自主研发分布式时序数据库平台,支持高性能写入和读取,支持多维条件查询,支持聚合计算,且运行开销较小,可私有化、分布式部署。
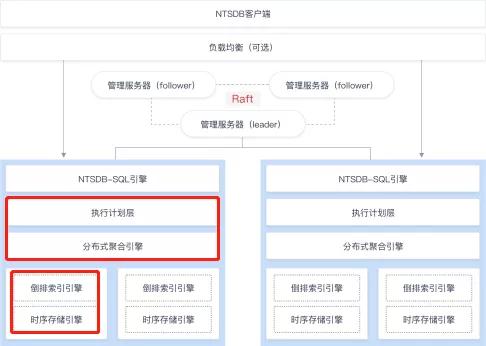
该时序数据库的分布式集群结构与 hadoop,Hbase,Kudu 等架构非常相似:多台服务器用来存储数据,并通过 Raft 保证数据的一致性。数据的分布式计算是在分布式节点(node)上完成的,每个 node 上的数据存储计算系统称之为 shard server。在 Shard Server 的底层数据存储中,原始数据存一份,再按照索引的方式再存一份。
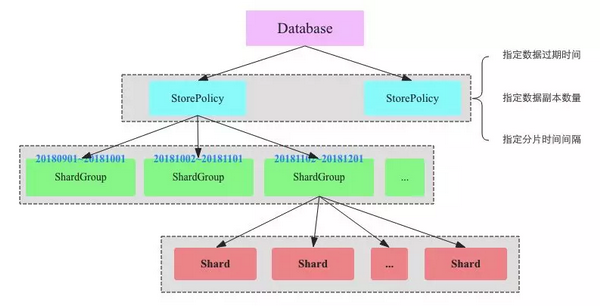
网易时序数据平台的数据存储方式是这样的:
1、DataBase 中建立若干 StorePolicy(类似 MySQL 数据库中的表结构),其作用为:
(1) 指定数据过期时间;
(2) 指定数据副本数量;
(3) 指定分片时间间隔。
2、每个 StorePolicy 中,按照指定的时间间隔建立若干 ShardGroup。将最新写入的数据(称之为热数据)存到对应的 ShardGroup 中,再通过哈希分片的方式将该 ShardGroup 分片成若干个 Shard,这些 Shard 会分布至整个集群。

以上图为例,同一时间段不同 shard 分布到不同的节点上。例如:左侧大方框中包含的 6 条记录,代表该时间段的记录分布在 6 个 shard 里;右侧小方框中的 5 和 6,代表该 shard 共有 2 个副本,分别分布在集群中的 5 号节点和 6 号节点。
由此可以看出,同一时间段的多个 shard 是分布在多个节点上。这样做的好处是:查找指定时间段的数据时,只需要在相应节点中查到对应的 shard 里的数据即可,避免了全局遍历的情况。
3、数据在 shard 中的存储方式:
(1) 时间线列式存储:
具体来说,SeriesKey 相当于原始数据(DataSource),具有不同维度;存储的时候,所有的时间存到一起,所有的 value 单独存在一起,这种存储方法叫做列式存储。列式存储有两大好处:
每一列数据类型相同,因此压缩率非常高;
方便对列做聚合计算。

什么是列式存储?
传统的关系型数据库如 Oracle、MySQL、SQL SERVER 等,都采用的是行式存储法 (Row-based),在基于行式存储的数据库中,数据是按照行数据为基础逻辑存储单元进行存储的,每行中的数据在存储介质中以连续存储形式存在。
不同于行式存储,列式存储以列为基础单元,每列的数据在存储介质中以连续存储的形式存在。
针对海量分布式数据背景的 OLAP(on-line analysis processing),列式存储可在内存中高效组装各列数据并形成关系集,可避免全表扫描,显著减少 IO 消耗。
(2) 倒排索引
支持 sql 语句进行条件筛选;在条件筛选的过程中,使用倒排索引方法,实现快速定位,可“直达用户需求”。
正排索引:key-value 中,通过 key 去寻找 value;
倒排索引:通过 value(或包含 value)去寻找对应的 key。
正排索引需要首先对全局进行扫描遍历,进而从中做筛选;而倒排索引可以仅抽取符合条件的 value 值,节省大量的资源。
(3) shard 自动扩容
数据库作为分布式系统,需要考虑系统的扩容(即增加节点)。
增加节点后,为保证数据存储的均衡,将不再更新的数据(即历史数据)作为 cold shard,平均分布到集群的所有节点(包括新增加的节点)中,而实时更新的数据(即 hot shard,随时间不断写入)不做任何处理。
(4) 多级存储优化
考虑到时序数据的一个特点:热数据查询概率远大于冷数据。针对这一特性,做了如下两个优化:
A. 考虑到数据文件可能存在多级索引,针对冷数据,只加载一级索引即 root 索引;针对热数据,会加载所有索引。
B. 因此针对集群服务器配置方面,每个集群 12 块盘,只需要 1 块 ssd 用来存储 hot shard 即可,其余均使用普通 hhd 即可,最大程度降低硬件成本。
cluster 是整个集群,包含 n 个 node;
node 通常掌控独立的资源,包括 cpu 等;一台机器可以多个 node。
shard 一般是从数据角度来说。例如,1000 条数据按 id 分,存 10 份,就是 10 个 shard。
shards 分散在多个 node 上。
最后通过以上手段,来实现刚刚所说的时序数据应用场景的核心特征:时间区间查询,多维条件查询,支持 TTL 机制,支持高压缩率,支持高效聚合,支持集群可扩展,服务高可用,数据高可靠。

时间:2019-05-14 00:14 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















