数据科学家易犯的十大编码错误,你中招了吗?
数据科学家比软件工程师擅长统计,又比统计学家擅长软件工程。听起来牛逼轰轰,事实却是,许多数据科学家有统计学背景,却没有什么软件工程方面的经验,因此在编码时容易犯一些简单的错误。作为一名高级数据科学家,本文作者总结了他在工作中常见数据科学家犯的十大错误。

我是一名高级数据科学家,在 Stackoverflow 的 python 编码中排前 1%,而且还与众多(初级)数据科学家一起工作。下文列出了我常见到的 10 个错误。
没有共享代码中引用的数据
数据科学需要代码和数据。所以为了让其他人能够复现自己做出来的结果,你需要提供代码中涉及的数据。这看起来很简单,但许多人会忘记共享代码中需要的数据。

解决方案:用 d6tpipe 共享代码中的数据文件,或者将数据文件上传到 S3/网页/Google 云等,还可以将数据文件保存到数据库中,以便收件人检索文件(但不要将数据添加到 git 中,这一点后面的内容会讲到)。
硬编码其他人无法访问的路径
和错误 1 类似,如果硬编码其他人无法访问的路径,他们就没法运行你的代码,而且在很多地方都必须要手动修改路径。Booo!

解决方案:使用相对路径、全局路径配置变量或 d6tpipe,这样其他人就可以轻易访问你的数据了。
将数据和代码混在一起
既然数据科学代码需要数据,为什么不将代码和数据存储在同一个目录中呢?但你运行代码时,这个目录中还会存储图像、报告以及其他垃圾文件。乱成一团!

解决方案:对目录进行分类,比如数据、报告、代码等。参阅 Cookiecutter Data Science 或 d6tflow 项目模板,并用问题 1 中提到的工具存储以及共享数据。
Cookiecutter Data Science:https://drivendata.github.io/cookiecutter-data-science/#directory-structure
d6tflow 项目模板:https://github.com/d6t/d6tflow-template
用 Git 提交数据
大多数人现在都会版本控制他们的代码(如果你没有这么做那就是另一个问题了!)。在共享数据时,可能很容易将数据文件添加到版本控制中。对一些小文件来说这没什么问题。但 git 无法优化数据,尤其是对大型文件而言。
git add data.csv
解决方案:使用问题 1 中提到的工具来存储和共享数据。如果你真的需要对数据进行版本控制,请参阅 d6tpipe、DVC 和 Git Large File Storage。
DVC:https://dvc.org/
Git Large File Storage:https://git-lfs.github.com/
写函数而不是 DAG
数据已经讨论得够多了,接下来我们谈谈实际的代码。你在学编程时,首先学的就是函数,数据科学代码主要由一系列线性运行的函数组成。这会引发一些问题,详情请参阅「4 Reasons Why Your Machine Learning Code is Probably Bad。」
地址:https://towardsdatascience.com/4-reasons-why-your-machine-learning-code-is-probably-bad-c291752e4953

解决方案:与其用线性链接函数,不如写一组有依赖关系的任务。可以用 d6tflow 或者 airflow。
写 for 循环
和函数一样,for 循环也是你在学代码时最先学的。这种语句易于理解,但运行很慢且过于冗长,这种情况通常表示你不知道用什么替代向量化。

解决方案:NumPy、SciPy 和 pandas 都有向量化函数,它们可以处理大部分你觉得需要用 for 循环解决的问题。
没有写单元测试
随着数据、参数或者用户输入的改变,你的代码可能会中断,而你有时候可能没注意到这一点。这就会导致错误的输出,如果有人根据你的输出做决策的话,那么错误的数据就会导致错误的决策!
解决方案:用 assert 语句检查数据质量。Pandas 也有相同的测试,d6tstack 可以检查数据的获取,d6tjoin 可以检查数据的连接。检查数据的示例代码如下:
d6tstack:https://github.com/d6t/d6tstack
d6tjoin:https://github.com/d6t/d6tjoin/blob/master/examples-prejoin.ipynb
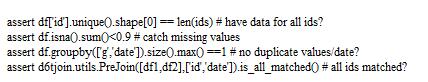
没有注释代码
我明白你急着做分析。于是你把代码拼凑起来得到结果,把结果交给你的客户或者老板。一周之后他们找到你,问你「你能改掉 xyz 吗?」或「你能更新一下结果吗?」。然后你和自己的代码大眼瞪小眼,既不记得你为什么要这么做,也不记得你做过什么。现在想象一下其他人运行这段代码时的心情。

解决方案:即便你已经完成了分析,也要花时间注释一下你做过什么。你会感谢自己的,当然其他人会更加感谢你!这样你看起来会更专业!
把数据存成 csv 或 pickle
说回数据,毕竟我们讨论的是数据科学。就像函数和 for 循环一样,CSV 和 pickle 文件也很常用,但它们其实并没有那么好。CSV 不包含模式(schema),所以每个人都必须重新解析数字和日期。Pickle 可以解决这一点,但只能用在 Python 中,而且不能压缩。这两种格式都不适合存储大型数据集。

解决方案:用 parquet 或者其他带有数据模式的二进制数据格式,最好还能压缩数据。d6tflow 可以自动将数据输出存储为 parquet,这样你就不用解决这个问题了。
parquet:https://github.com/dask/fastparquet
使用 Jupyter notebook
这个结论还有一些争议——Jupyter notebook 就像 CSV 一样常用。很多人都会用到它们。但这并不能让它们变得更好。Jupyter notebook 助长了上面提到的许多不好的软件工程习惯,特别是:
♦ 你会把所有文件存在一个目录中;
♦ 你写的代码是自上而下运行的,而不是 DAG;
♦ 你不会模块化你的代码;
♦ 代码难以调试;
♦ 代码和输出会混合在一个文件中;
♦ 不能很好地进行版本控制。
♦ Jupyter notebook 很容易上手,但规模太小。
解决方案:用 pycharm 和/或 spyder。
参考原文:https://medium.com/m/global-identity?redirectUrl=https%3A%2F%2Ftowardsdatascience.com%2Ftop-10-coding-mistakes-made-by-data-scientists-bb5bc82faaee

时间:2019-05-05 22:40 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















