Kylin 实时流处理技术探秘
本月在上海举行 Apache Kylin Innovation Meetup 活动中,eBay 大数据平台团队的马刚老师,为大家分享了 Kylin 的实时流式 OLAP 分析的新功能;特别提醒,该功能目前已经开源,会在未来的版本中发布给社区试用!
为什么需要实时流数据分析?
在以往的交流中,我们发现许多企业的大数据分析场景对数据的实时性要求很高,例如网站流量监测、安全告警、用户推荐等等,传统的批处理模式往往有数小时甚至数天的延迟,不能满足业务需要。eBay 内部也有一些实时 OLAP 的需求,社区其实在 v1.6 版本之后已经有提供近实时(Near real-time,简称 NRT) 解决方案,通过微批次去消费 Kafka 的数据,然后利用 Hadoop 任务加工数据。为什么我们还要继续开发 Real-time Streaming 呢, 主要有三点考量:
第一,分钟级的数据准备时间比较长,因为它需要定时触发,比如说每 5 分钟构建一个 Cube segment,构建 Cube 的过程,比如说需要 5 分钟的话,最长就有 10 分钟准备延迟了。即使通过进一步的改进,准备时间也不大可能低于 5 分钟。
第二,需要一个 Lambda 的架构, 实时的数据不断流过来,上面的程序写数据出错了,历史的数据需要修改怎么办?所以我们希望实时 Cube 可以去更新。所谓的更新,因为实时流是不可能随时更新的,必须要从另外的数据源去刷 Cube,把原来的错误数据更改回来,这是一个 Lambda 的 Cube 概念。
第三, 更少的 Hadoop 任务,以及创建更少的 HBase 表位批次的方式。比如说每 5 分钟去提交一个请求,去构建一个 Segment,Kylin 里面每一个 Segment 都是一个 HBase Table,这样操作的结果会造成 MR job 比较多,HBase Table 的数量也会增加,对于 Hadoop 集群和 HBase 集群会造成比较大的压力,需要不断的去做 merge, 但 merge job 也是需要消耗相当大的资源,这些都是当时使用下来发现的一些问题。
整体架构
eBay 在整体架构中增加了一个 Real-time Streaming 的组件。下图中间这一段就是增加的实时集群,它包括一个 Streaming Coordinator,和若干个 Streaming Receiver。它的主要任务是去消费实时数据源的数据,并且存在我们实时集群里面去;Receiver 会定期的去调用 Build Engine,把这些实时的数据构建到历史数据里。
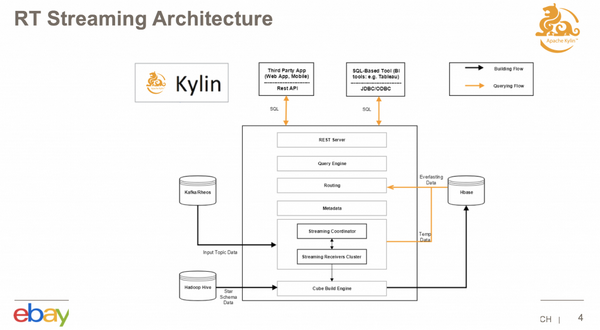
当查询进来之后,如果击中了一个实时的 Cube 的话,不仅会去查 HBase,还会去查实时集群里面的数据,这样结合两者的结果,可以保证最终数据的实时性,实时数据都能查到。
下图是整个数据流的过程,消息从数据源出来之后,会到我们的内存里面做聚合,内存的数据到达阈值或者是等到一定时间之后,会 flush 到我们实时集群里面磁盘上;再过一段时间之后,我们可以上传磁盘的数据,通过 MapReduce,将 Cuboid 数据构建到 HBase。整体而言,数据存在在以上三个部分。
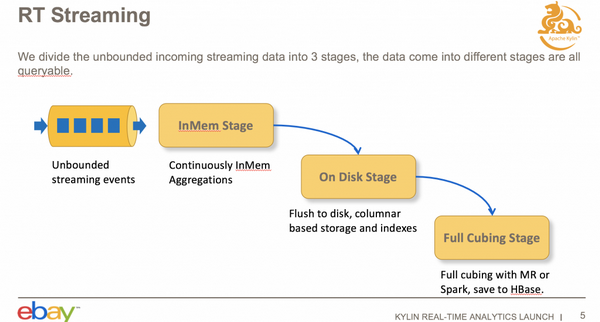
需要注意的是,这三个部分的数据都是可以查询的,这样就保证了查询的实时性,数据一旦消费进来就可以被查到,就可以做到毫秒级的延迟。
实时集群,包括 Query Engine,Coordinator, Receiver,Metadata Store。
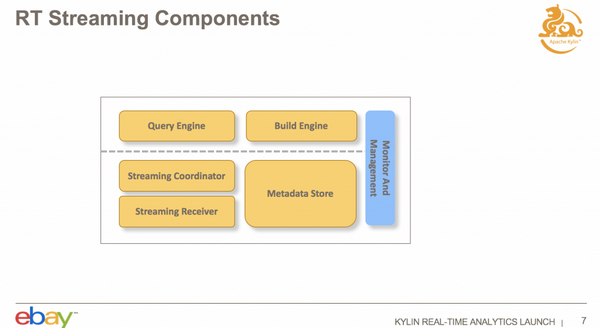
Query Engine 会先找负责消费数据源的数据 Receiver,根据查询去拉取数据。Receiver Cluster 是一个集群,所以需要有一个协调者,Streaming Coordinator 去协调哪些 Receiver 来负责消费 Kafka 里面的 Partition,待查询需求指令下达时,知道需要通过 Coordinator 来获取 Cube 的数据是在哪些 Receiver 里面的。另外,Metadata Store,主要是用来存分配方面的信息,哪个 Topic 的 Partition 被哪些 Receiver 承担摄入和查询任务;Metadata Store 还保存有一些高可用(HighAvailability,简称 HA)的信息。
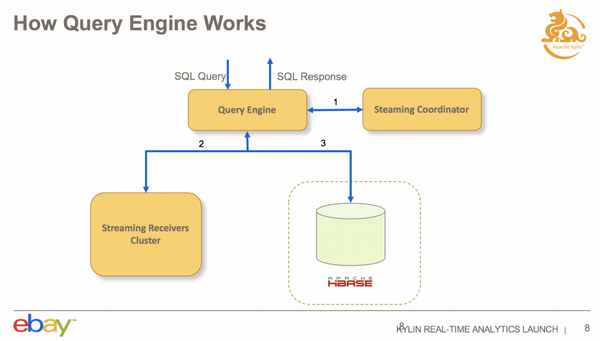
我们也修改了查询引擎和构建引擎。如果查询的时候需要查实时数据部分和历史数据部分,构建引擎可以把实时数据构建到 HBase 里面。后面我将详细得介绍整个查询跟构建的过程。
Streaming Cube 请求进来之后,我们通过 Kafka API 获取 Cube 涉及的 Topic,这个 Topic 有多少个 Partition。Steaming Coordinator 会做一些分配工作,根据现有的一些集群的情况做分配,下面哪几个 Receiver 负责消费 Topic、哪几个 partition 的数据。把这个分配好之后,Steaming Receiver 就可以消费这些 Kafka 的数据了,我这里面标的是 Replica Set,Replica Set 是一个 HA 的概念,其实 Replica Set 里面是一个或者多个的 Steaming Receiver。
消费数据之后,实时数据会消费到 Steaming Receiver 那边 ,Receiver 会做一些 Cuboid 的构建,另外也可以增加查询常用的 Cuboid,这样利于提高查询性能。过一段时间之后,它会把本地的磁盘上的数据写到 HDFS 上,并通知 Coordinator,等到全部 Replica Set 把 Cube Segment 的所有实时节点数据都被传到 HDFS 后,Coordinator 触发 MapReduce Job 进行一个批量的构建。之后就是 MapReduce 从 HDFS 去拉这些实时数据做构建,做一些合并工作并将 Cuboid 构建到 HBase。MapReduce Job 结束时实时数据就被构建到 HBase 的 Segment 里面去之后,Coordinator 会通知实时集群去把实时数据删掉,以上是完整的实时 Cube 的构建过程。
查询的过程比较简单,当 QueryServer 接受新查询后,会请求 Coordinator 查询的 Cube 是不是实时 Cube。如果是的话,会看这个查询包括实时数据和历史数据都要,就发 RPC 请求到 HBase,并且同时发查询请求到我们的实时集群,将结果汇总到查询引擎做一个聚合,再返回给用户。
设计细节
1) Segment & storage
实时集群里面,Segment 的时间窗口长度是可以配置的, 在 Cube 设计的时候去配置,默认是一个小时。数据过来的时候,实时流数据都会有时间戳的字段,Receiver 会根据时间戳字段来判断它落在哪个 Segment 里,然后就会把数据落到 Segment 的 Memory Store 里面。进入 Memory Store 的时候,需要做 Cuboid 的聚合。过一段时间之后,如果 Memory Store 达到某个阈值了,会把它放在磁盘上,增加一个 Fragment File。Memory Store 和 Fragment File 的概念其实跟 HBase 其实是蛮像的,HBase 写数据也是开始写的 Memory Store,Memory Store 满足一定条件下会写到 Fragment File 。
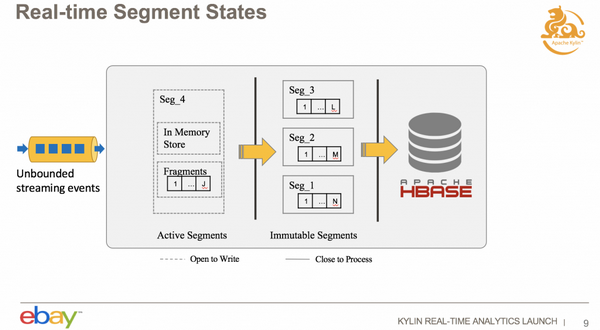
开始状态的 Segment 是不断往里面写数据的,但是这个 Segment 什么时候变成 Immutable 呢?一个 Immutable Segment,我们现在定义的策略是, 这个 Segment 持续一段时间都没有新的数据进入,就将它标志为 Immutable,然后它就可以传到 HDFS 上面去了,以上就是一个 Segment 状态转化的过程。

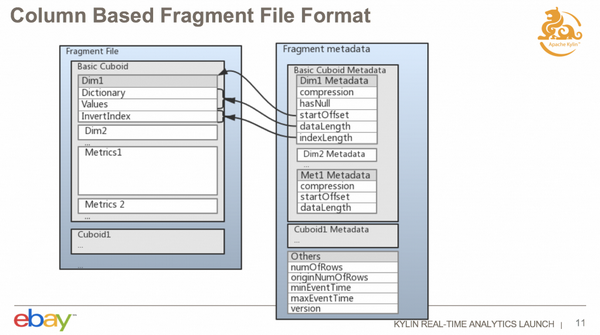
在实时节点上 Segment 的 Fragment 文件结构是这样的,最上面是一个 Cube 的名字,接下来是一个 Segment 的名字,是起始时间和结束时间。接下来是一个 Fragment 的名称,每一次增加 Fragment 文件都会生成一个 Fragment ID,这是一个递增的值。
刚才提及的 Fragment 文件结构是一个列式结构,包括两个文件,Fragment 的数据文件,和 Metadata 文件。数据文件可以包含多个 Cuboid 的数据,默认只会构建一个 Base cuboid,如果有配置其它 mandatory cuboid 的话,会根据配置生成多个 Cuboid;这里的数据是一个 Cuboid 一个 Cuboid 依次来保存的,每一个 Cuboid 内是以列式存储,相同列的数据存在一起。基本上现在的 OLAP 存储为了性能通常都是列式存储。每一个维度的数据包括这三部分:
第一部分是 Dictionary,是对维度值做字典的。
第二部分是值,经过编码的。
第三部分是倒排索引。
Metadata 文件里面存有重要的元数据,例如一些 Offset,包含这个维度的数据是从哪个位置开始是这个数据,数据长度是多少,Index,也就是反向索引的长度是多少等等,方便以后查询的时候比较快的定位到。元数据还包含一些压缩信息,指定了数据文件是用什么样的方法进行压缩的。
反向索引使用 Roaring Bitmap 来保存索引,出于性能方面的考量分两种方式存储。
一个是顺序存储的反向索引,对应是左面的文件接口,如果所谓的顺序存储的格式,是跟我们的 Dictionary 类似;
如果是 fix-len 的话,适用于基数比较高的情况,用右面的这种反向索引的方式。

实时存储方面也做了一些压缩,现在是支持两种压缩方式。
像时间相关的维度,它们的数据基本上都是类似的,或者是递增的。还有设计 Cube 的时候也有设计 Row Key,在 Row Key 的顺序排在第一位的,使用 run length 压缩效率会比较高,读取的时候效率也会比较高。
对其他的数据默认都会用 LZ4 的压缩方式,虽然其它压缩算法的压缩率可能比 LZ4 高,但是 LZ4 解压性能更好,我们选择 LZ4 是主要从查询方面去考虑的,所以从其他角度考虑可能会有一些其它结论。
2)高可用(HA)
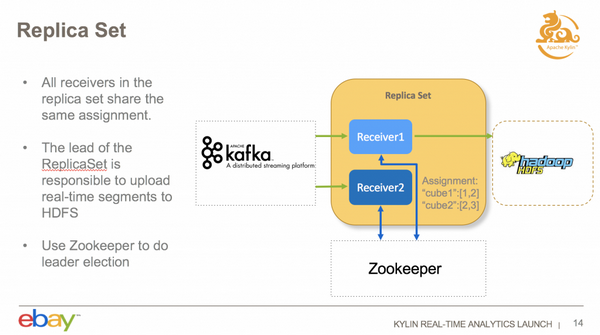
现在 eBay 的 HA 方式比较简单,通过引入 Replica Set 概念来实现。一个 Replica Set 可以包含多个 Receiver,一个 Replica Set 的所有的 Receiver 是共享 Assignment 数据的,Replica Set 下面的 Receiver 消费相同的数据。一个 Replica Set 中存在一个 Leader 做额外的工作,这个工作,是指把这些实时的数据存到 HDFS,Leader 选举是用 Zookeeper 来做的。以上是实时集群如何实现 HA 的,可以防止宕掉了对查询和构建造成影响。
3) Check point
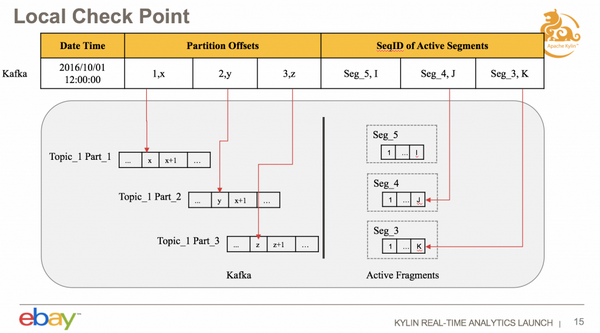
接下来介绍一下是如何处理错误恢复的,Receiver 重启怎么保证数据不丢呢?我们是通过 Check Point 的方式去实现。现在是每 5 分钟在本地做一个 Check Point,把消费的信息存在一个文件里,包含哪些信息呢?一个是 kafka topic 消费的 offset 信息,还有一个是本地磁盘信息,例如最大的 Fragments ID 是多少;重新启动的时候根据这个去恢复。首先会从这里消费,看一下磁盘状态,ID 最大的 Fragments 存在的话,会把这个删掉,因为是没有做出方案的,就继续消费,可以保证它的数据是不丢的。
这个是 Local Check Point,有一个问题是本地的,数据都存在本地的磁盘,就跟本地磁盘数据是一样的,是跟本地的 Segment 数据是存在一起的,一个问题是,当整个机器宕掉之后,如果从另外一个起来,只能够从 Kafka 最开始的地方去消费,这样的话,如果数据量非常多,可能要等到很久才能追上最新的,所以说我们引入了一个 Remote Check Point。
Remote Check Point 把一些消费状态信息存在 HBase 的 Segment 里面,保存历史的 Segment 信息的时候,会把这些消费信息存在 Segment 的元数据里面,构建这个 Segment 的时候,最早是消费到哪个数据的,信息存在那里。

性能
Real-time 的存储性能,之前测下来 36 Million 行数据的话,做一个 Count 查询,大概是耗时 800ms 左右,每秒钟每个 Receiver 可以消费大约 44,000 条 Event,每个 Event 包括 11 个维度和 1 个 Metric。
在 eBay 的使用情况
eBay 的生产环境部署是 20 个 Streaming Receiver 的集群,每一台机器是 86G 内存和 16 个 vCore 。前面的性能测试数据也是在这个规格的 Receiver 上测试的。现在主要的 Use case 为 Site Speed,即分析 eBay APP 上访问 eBay 站点的性能,现在大概是 16 个维度,50 个 Metrics。
下面介绍我们下一步的计划。
第一点是支持星型模型,因为现在它还只支持一个事实表;
第二点是支持多租户,这是为了做一些访问权限隔离;
第三,我们会进一步的加强实时集群的监控。
此外,我们还会进一步的提升实时节点、实时存储的查询性能。最后我们会把实时集群放在 Kubernetes 上,一些资源的分配、管理工作都让 Kubernetes 完成,因为增加了 Receiver 集群的 Kylin 维护的成本还是比较高的。
Q&A
Q:有三个问题想问一下,求一个精确的 UV,Count Distinct 这样的途径会不会出问题?因为我一部分要查 HBase,一部分要查实时内存,怎么处理的?
A:这是个好问题,现在实时分析的精确去重只能支持到 int 类型的,这样不需要全局做字典转换。
Q:想问一下,replica set 中的这两个 receiver 是怎么获取数据的?消费同一份还是再复制一份?
A:各管各的。每一个都是有自己 Consumer 就可以了
Q:这个架构感觉跟 Druid 架构非常相似,你们做的这个结构是不是借鉴他们的?
A:蛮像的,因为大部分这种实时的架构都是类似的。

时间:2019-04-12 00:00 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















