饿了么研发总监:外卖大数据推荐算法中有哪些
提到市场机制和调控手段,大家可能会想起某些中央机构,而在流量的分发方面,我们的角色是类似的,搜索推荐是饿了么的核心流量入口,我们通过市场机制来实现流量效率的最大化,而调控手段更多的是兼顾效率和平台长期目标以及流量生态的健康。
今天分享的内容分以下几个方面,首先是饿了么外卖推荐业务形态,然后是搜索推荐平台的目标与定位;接下来会聊聊在外卖推荐领域的特殊挑战,以及外卖推荐算法中的一些市场机制和调控手段。

1. 饿了么外卖推荐业务形态

前面提到过,搜索推荐是饿了么核心的流量分发入口,平台 90% 以上的用户在下单前的决策是通过各种各样的搜索推荐产品实现的。我们每天负责千万级订单的精准匹配,涉及首页推荐、搜索、金刚入口、活动会场、发现页、订单页等不同业务场景。平台方面除了饿了么 APP 外卖,还有支付宝里面的外卖、手机淘宝里面的外卖等很多阿里系流量。类目方面也更加丰富,除了美食餐饮外卖,还有水果、买生鲜、医药、鲜花等可以通过外卖实现。
外卖业务的简要流程:首先用户进入 app 会有一个浏览行为,访问某个模块后点击某一个商家或者美食到达店内,然后会有一个选择和加购物车的过程,再之后达成订单。前面的步骤看起来和传统电商是类似的,但是有一个核心区别点在于用户下单完成后还有一个商家的出餐和即时配送的过程,这个下单后的环节也是会影响用户的整个体验的,需要在推荐场景中考虑。
2. 饿了么搜索推荐平台的⽬标与定位
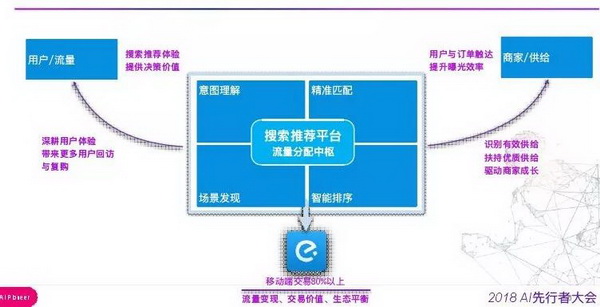
饿了么推荐平台作为流量分发的中枢连接着几个不同的角色,包括用户 (流量)、商家(供给)还有平台本身, 需要明确好定位。对于用户 / 流量侧主要是为用户提供良好的决策体验,帮助用户选择满意的餐厅和美食,并优化好用户的整个链路的体验。对于商家侧需要带来精准的流量,带来订单提升,并不断提升商家曝光效率,帮助商家在平台上成长。最后对于平台而言,核心是提供流量的变现、交易的价值以及建设好健康的流量生态,为平台的长期目标服务。
3. 外卖推荐的特殊挑战
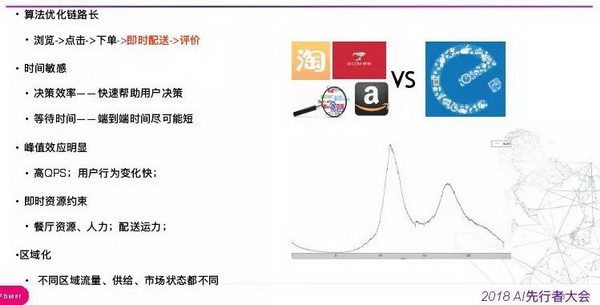
这里聊一下外卖推荐的一些特殊挑战,第一点,区别于传统搜索和电商,在用户下单后有一个即时配送的过程,而配送满意与否也是关于用户体验的重要因素,因为外卖用户通常是时间敏感的,尤其是午餐和晚餐高峰期。通常而言,用户对商家的喜好以及是否转化是衡量推荐质量的一个重要因素,但在外卖存在一个情况就是虽然偏好商家,但是下单后很久才送到,用户对商家很喜爱但是整个链路的时间体验比较差,这是我们在流量分发阶段需要考虑的问题,转化率、决策效率、配送时长等需要综合考虑。第二点就是峰值效应比较明显,高峰是平时几十倍,峰值又比较尖,类似于秒杀,这在工程上会带来很大的挑战,同时,高峰期用户行为分布变化比较快,对如何快速捕捉用户行为提出了比较高的要求。第三点是即时性资源约束和限制,餐厅资源、物流骑手运营资源都是在固定时间比较有限的,如何在多重约束情况下综合优化用户体验也是一个挑战。最后一点,区域化会和流量宏观调控有关系,外卖的流量成点状区域分布,网格效应弱,并且每个区域的城市发展、外卖阶段、流量分布是不同的,不同的地区有不同的目标,也对应着不同的流量策略,因此流量的调控手段显得格外重要。
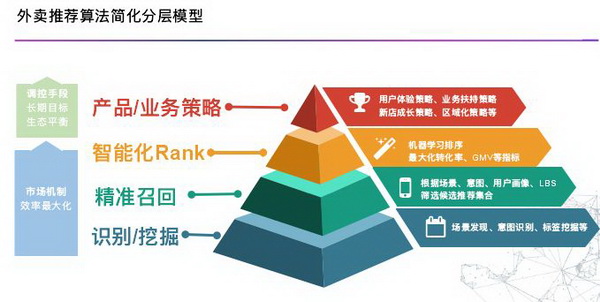
为了解决这些问题,我们简单地分为两个层次解决,市场机制是下面三块,主要是解决效率最大化问题,包括识别挖掘类、精准召回算法、智能化排序算法。而调控手段更多的是偏产品和业务规则,同时对规则中也会融入一些算法实现流量扶持、长期目标、生态目标的均衡。包括兼顾用户体验的策略,扶持特殊业务的策略,新店店长成长策略等。
4. 外卖推荐算法中的市场机制
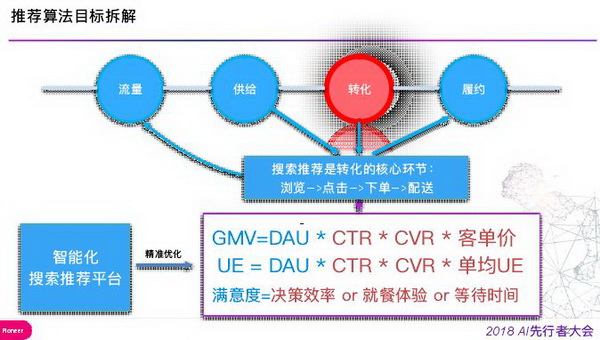
外卖推荐算法中的市场机制方面主要是把效率最大化的目标与算法目标做了一些关联。基于现有流量及供给,通过深入挖掘、精准匹配及智能化排序机制去实现用户体验和平台效率最大化。
对推荐算法目标拆解如上图所示,在外卖领域有四个重要角色,流量、供给、转化和履约。搜索推荐对用户下单转化起到关键作用,会将目标拆解为不同子模型。如 GMV 会分解为点击模型、转化模型、客单价模型,如果考虑每单收益时会建立单笔收益模型,还有偏向于用户体验的指标,如决策效率 、就餐体验、等待时间,也会建模去优化。
优化目标大的节奏上经历了从转化率—> 访购率 —> 毛 GMV —> 净 GMV—> 净 GMV+UE,早期以优化转化率为主,但外卖平台具有很高的消费频次,很多用户一天之内下单超过 2 单以上,因此优化目标又调整为访购率(订单量 /UV),除转化率外还要优化用户的下单频次。后续为了平衡用户体验和平台目标,同时加强品质感,并兼顾高客单价商家的诉求,优化目标调整为 GMV(交易额),为此也引入了客单价预估模型。再后来,为了打击虚假自营销和虚抬物价等行为,优化目标又调整为实付 GMV。目前,随着平台目标新一轮的变化,我们正在尝试对新的目标进行优化。
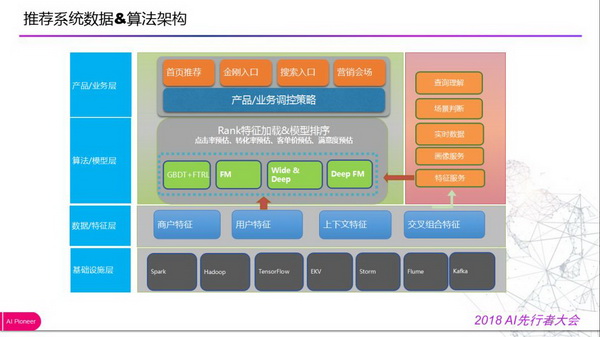
外卖推荐系统架构与大部分推荐系统架构类似,底层是基础设施层,包括大数据处理的 Spark、Hadoop,深度学习工具 TensorFlow,分布式 EKV,还有做实时计算的平台及工具。目前融入阿里经济体后,在服务和数据上会进行一个打通,以便更好地融入阿里技术体系。
数据 / 特征层包括数据的埋点、收集、清洗、加工、建模、应用等多个环节,特征部分非常关键,包括通过人工的特征工程以及通过模型做很多特征,包括用户维度、商家维度、上下文维度的特征。
算法模型层核心是召回和排序,外卖场景是一个强 LBS 属性的场景,召回主要是基于 LBS 搜索;后面也加入了标签化、向量化的召回。去年我们在这块做了一些不错的尝试。比如说标签召回,前面提到过本地化的一个挑战在于信息的非结构化,商家上传的菜品各式各样,直接通过文本匹配效果是不够好的。为此我们先通过离线挖掘的方案,挖掘菜品的口味、食材、菜系、做法等标签化表示,在搜索阶段,再通过标签进行召回,有效的解决了意图匹配的问题。向量化主要是对商品、美食、搜索词等通过 word2vec、Item2vec 等方法生成其向量化的表示,是一种更加泛化的表达,生成向量后,基于向量的相似度进行召回。该方法在各个模块取得了不错的效果,其中在无结果推荐等模块甚至取得数倍转化率的提升。另外,在精准召回环节往往还会进行一轮粗排,主要是为了在效果和性能上进行更好的平衡。
智能化排序(Rank)环节在外卖这种强 LBS 熟悉的业务下更为关键,会对召回环节的结果通过模型进行重排序,以达到更优的体验和业务目标。在这个环节,我们经历了算法模型和优化目标的多次升级,后面会重点介绍下。
最上层是产品 / 业务层,会更偏一些调控策略。右侧所示会有一些通用服务,如实时数据服务、画像服务、特征服务等。
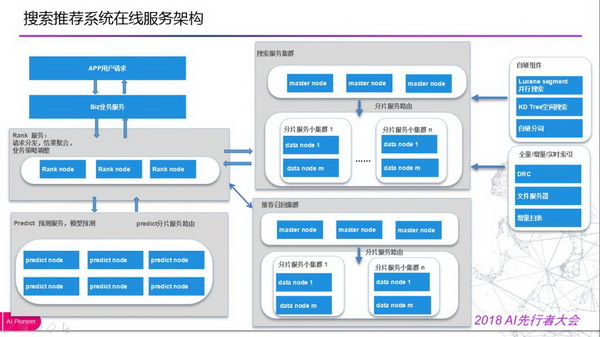
在线服务架构:用户请求过来后,Rank 服务会主要负责请求分发、结果聚合以及用户策略调整。会将请求依据用户场景发送到搜索服务集群或者推荐召回集群,会做一个相应的召回和初排。真正的模型预测是在模型预测服务,会做机器学习预测或者精排。
Rank 模型升级路线
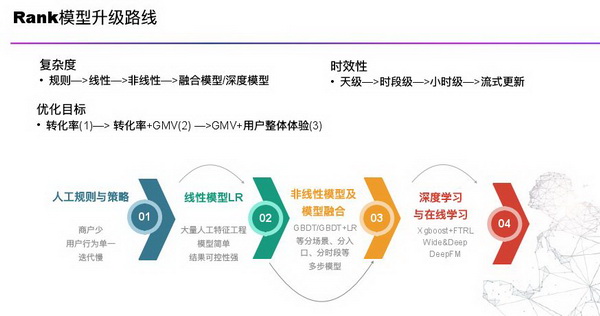
升级路线:
从先前的人工规则演进到线性模型的 LR,再到后来的非线性模型以及模型融合阶段,然后到深度学习和在线学习为主的模型。总体来看模型复杂度越来越高,时效性越来越快,由最开始的天级到后来的流式秒级更新。优化目标也会结合平台目标进行演进,目前主要是基于 GMV+ 用户整体体验最大化。虽然模型复杂度越来越高、时效性越来越强,但是模型总体收益与原来相比越来越少,如 LR 与人工规则相比相差 10%,再到 GBDT/GBDT+FTRL 为主就是 5 个百分点提升。到深度学习模型阶段,工程与算法复杂性进一步提升,但收益的提升也进一步缩窄。
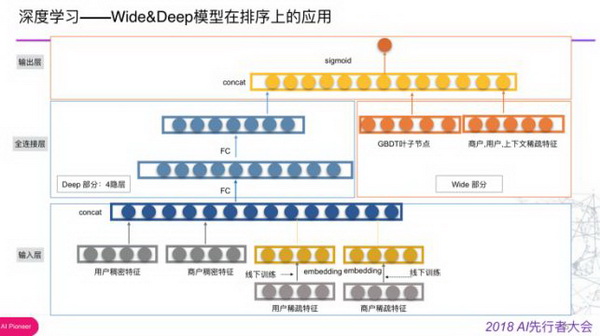
接下来介绍下 Wide&Deep 模型在排序上的应用,主要参照的是 Google 发布的论文做了一些改造,第一点是在 Wide 部分加入了 GBDT 的叶子节点,包括点击模型和下单模型。因为我们是从 GBDT 迁移过来,很多工作可以复用,在 deep 部分加入一些预训练的商家特征或者用户特征的 embedding,或者相互间融合。后面又尝试了 DeepFM 模型,总体结构和论文中一致,改方案充分利用了 DNN 在学习高阶交互特征方面的能力以及 FM 在学习二阶交互特征方面的能力,完全避免的人工构建特征,是一个端到端的模型 ,线上实验效果上也更佳。
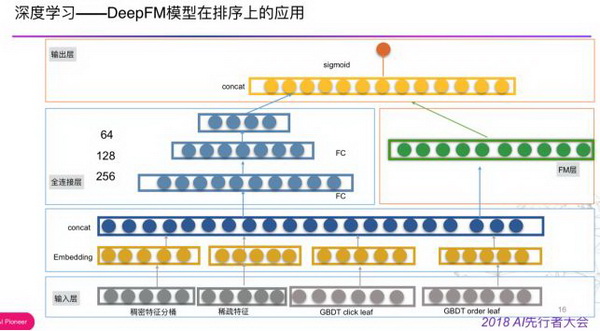
在线学习与实时引擎
在线学习在外卖推荐中应用主要是解决用户行为变化快的问题以及商家经营状况、运力、天气等因素随时变化。通过对实时生态体系的不断完善,实时样本流构建、实时特征、实时模型更新和评估等方案逐步成熟,基于此上线的多步融合的 xgboost+FTRL 取得了大幅提升,在一段时间内是效果最好的模型。主要采用 Google 论文算法 FTRL,优点有可以产生稀疏解、收敛速度很好、支持并行化处理、可以训练大规模模型、工程实现简单。
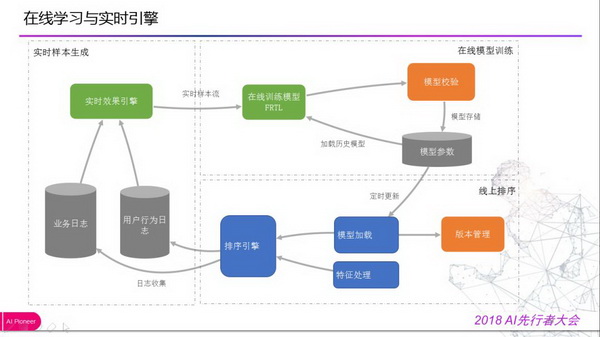
左边是实时效果引擎,会基于在线排序引擎会将业务日志和用户行为埋点数据做一个聚合,生成一个实时样本流。然后进入在线训练模型做一个实时模型训练和更新,排序引擎会定期加载模型训练的参数,用于线上的排序。
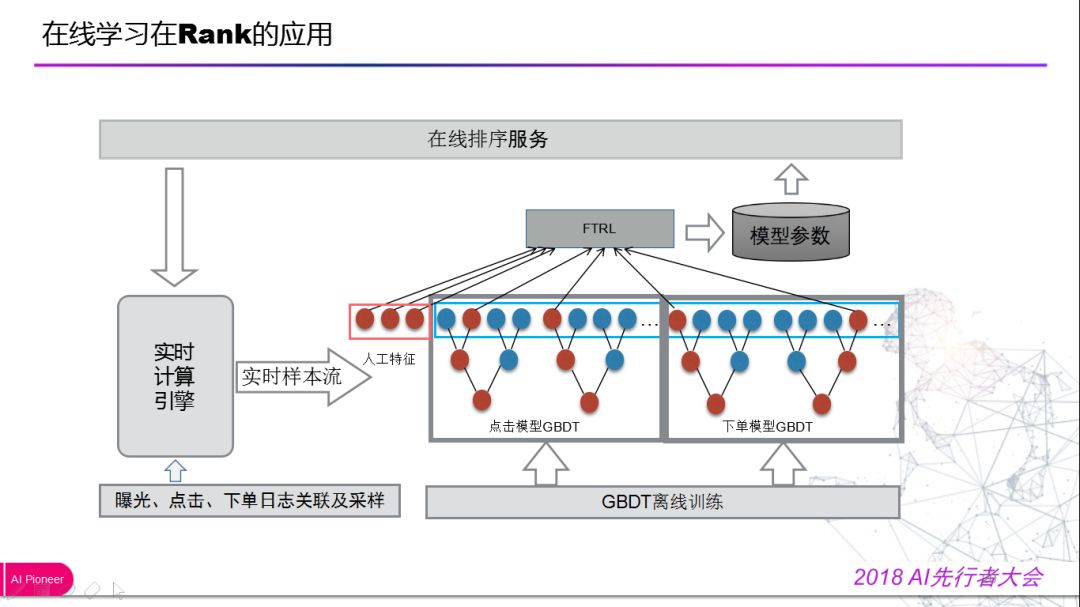
从模型结构上看,将 GBDT 和 FTRL 进行融合,会输出 GBDT 的叶子节点,将人工特征进入模型进行一个预测。
目前前面三个模型在线上不同应用场景模型复杂度等方面都有流量在跑,推荐技术升级路线总体路线也包含了数据、特征、模型还有业务理解升级。
5. 外卖推荐算法中的调控手段
调控手段主要用来解决长期平台生态问题,是效率最大化的基础上的流量再分配。兼顾平台的短期目标与长期目标。包括多个方面的平衡。如果单纯以最大化单日 GMV 为目标,会存在多方面的问题,比如流量分布的马太效应以及新店成长问题。
• 用户对商家、商品的偏好以及总体满意度方面的平衡
• 当天立即下单转化的需求和对用户兴趣探索成本的平衡;
• 自然流量效率和商家在平台成长或赋能线下商家间的平衡;
• 平台短期收益和长期生态间的平衡。
• 不同业务线间流量平衡、短期平台广告收入与平台转化间的平衡。
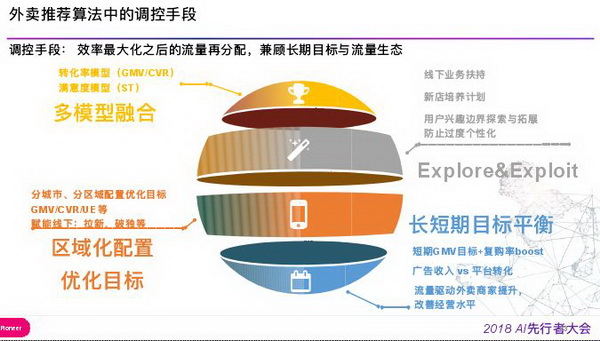
针对这些问题采用很多调控手段解决这些问题,比如利用多模型融合结局用户当前转化率与满意度的问题,预估用户下单时的总体时长与转化率的关系。用 EE 算法迫近流量比例去促进新店成长,还有用户兴趣的边界探索与扩展,防止过度个性化问题。配置区域化优化目标,将一定流量赋能线下,支持区域化的特定目标或者对特定业务支持,最后一点是长短期目标平衡,短期 GMV 目标 + 复购率 boost,短期 GMV 只考虑到当次收益最大化,需要加入复购率来平衡长期目标。还有广告收入 vs 平台转化流量,通过 AB Test 来控制广告流量密度,通过流量驱动外卖商家提升,改善经营水平。
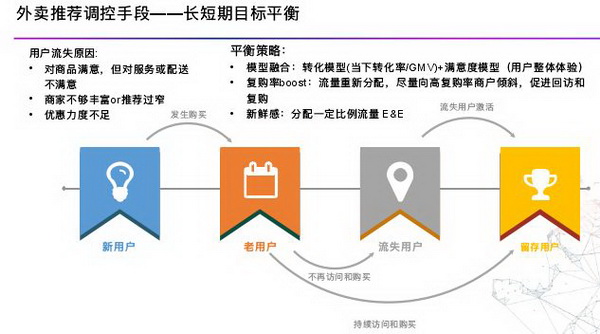
一些尝试:
(1)对用户生命周期分析,核心的流失原因有(对商品满意,对服务或配送不满意,商家不够丰富 or 推荐过窄),策略是通过多个目标模型的融合,转化模型 (当下转化率 /GMV)+ 满意度模型(用户整体体验);复购率 boost:流重新分配,尽量向⾼复购率商户倾斜,促进回访和复购;新鲜感:分配⼀定⽐例流量 E&E。
(2)区域化定制⽬标与流量分配,起先依据城市建立模型,但是不理解每个城市目标是不一样的,只是做一个分开的建模优化其转化率。目前是针对每一个区域做一个目标配置化,或者拿出一定的流量分配到特定的商家或商户。
(3)外卖推荐调控手段——E&E
为了在扶持和效率上做一些平衡,介入了一些算法机制,如 EE 算法去解决新店成长扶持、区域化业务流量扶持、用户新鲜感策略。策略也经过一定的演化,从早期的锁定位到轮播策略到现在的探索利用。常用的 MAB 算法有 Thompson sampling、 Epsilon-Greedy、UCB、Lin UCB。
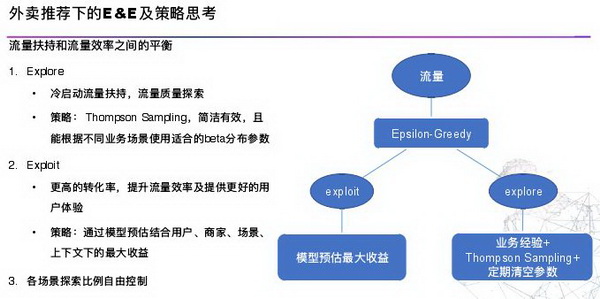
算法我们也做了一些探索,如冷启动流量扶持,流量质量探索。Explore 阶段是结合业务经验会赋予初始优先级,再加上 Thompson sampling 和定期清空参数做到足够的探索。利用阶段,用商家累计统计收益做一个利用,在外卖场景会出现不同时间场景、用户用统计收益不准确,因此用统计收益结合预估收益做利用。在新店扶持方面曝光效率和人工相比提升 70%, 新店扶成率提升 30%。
作者介绍:
马尧,饿了么研发总监,搜索推荐及商业策略研发负责人

时间:2019-03-29 18:44 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















