Spark Streaming 在数据平台日志解析功能的应用
一、日志解析功能的背景
通过日志,我们可以获得很多有用的信息,最常见的日志信息包括应用产生的访问日志、系统的监控日志,本文所针对的日志是大数据离线任务产生的运行日志。目前日志解析功能依附于有赞大数据平台,也就是有赞的 data_platform,为该平台的一个功能。
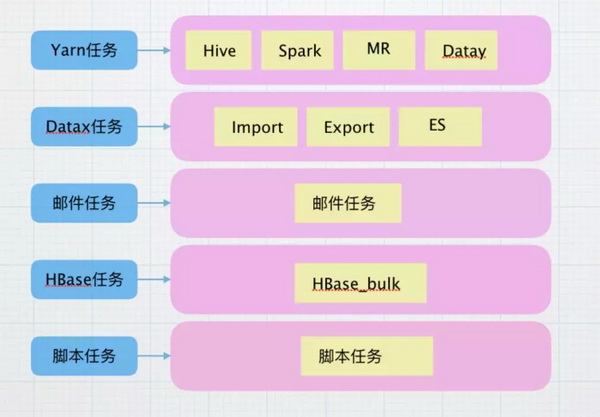
目前支持解析的日志类型包括:Hive 任务、Spark 任务、Datay 增量任务、导入任务、导出、MR 任务、Hbasebulk、脚本任务等。dataplatform 支持的调度类型为:批量重跑、测试类型、正常调度和手动导入任务。
做这个日志解析部分的目的分为几个,首先,在调度页面主要显示的是正常调度的任务,希望通过该功能了解不同调度类型的占比,比如测试类型,第二,了解每种任务类型的调度情况,比如查看运行成功、失败、重试等情况,第三,了解每种任务类型的资源占比,比如读写 byte 数量。
二、设计分析
2.1 针对不同类型的任务,日志的结构也不相同,针对这些任务进行了划分
目前,使用 yarn 进行调度的任务,资源情况已经进行了收集,主要获取总读取量、总写入量、shuffle 量、和 gc 时间等指标,进行存储汇总和展示,解析该种类型的日志时,需要将任务开始时间、结束时间等通用的信息进行保存,解析之后读取收集的指标表,进行统一封装,存储到缓存。
Datax 任务类型是导表任务,支持Hive -> Mysql ,Mysql -> Hive , Mysql -> ElasticSearch,Datax 任务类型的日志结构类似,主要的指标是读出总记录数、读写失败数、任务耗时、读取表、总比特数、使用表等信息。
不同的任务有不同的运行情况和需求指标,但是大体逻辑和以上两个类似。
2.2 根据调度类型进行划分
由于不同的调度类型在存储的时候目录信息不同,并且日志的开始、结束、失败等等标识不同,这些可以解析出来,标记任务的运行情况。根据任务类型进行分类,可以将任务分为正常调度、测试类型、手动导表和批量重跑,进而方便在后续解析过程中使用以及标记任务状态。
2.3 使用架构
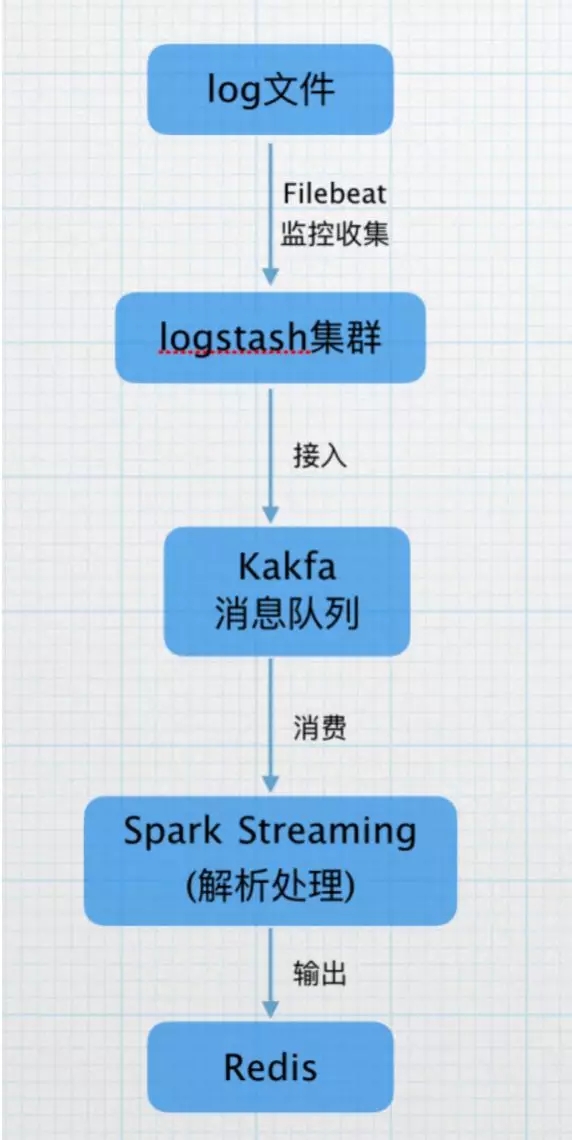
由于数据平台的任务调度日志是实时产生,所以我们选择流处理框架进行日志的处理。并且日志是从调度的集群上进行收集,目前调度数量是每日一万以上,而在每日凌晨会是任务调度的高峰期,对于吞吐量的要求也比较高,在调研了 Spark Streaming 后,考虑 Spark 支持高吞吐、具备容错机制的实时流数据的处理的特性,我们选择 Spark Streaming 进行处理。
目前,我们使用Filebeat监控日志产生的目录,收集产生的日志,打到logstash集群,接入kafka的topic,再由Spark Streaming 进行实时解析,将解析的结果打入Redis缓存,供后续统计查询使用。
三、功能实现
1. 实现资源统计
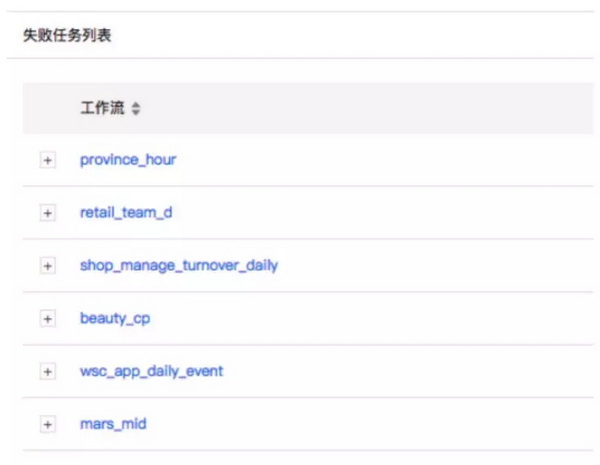
可以一目了然的看到,任务的运行情况,可以让用户一目了然的查看自己任务的运行情况,查看当天失败、成功、重试的数量以及统计。

2. 针对失败的任务和重试的任务进行集中的关注,进而实现 task 级别的优化,同时简化用户的操作成本,再这个页面就可以集中查看。
3. 实现资源量的排名统计,可以让 data_platform 的用户根据自己使用的情况,尤其是一些特别注意的地方,比如 GC 时间、Shuffle 量等影响大的指标进行集中的管理和优化,同时进行实时的监测。
四、一些注意事项
1. 由于 Spark standalone 模式只支持简单的资源分配策略,每个任务按照固定的 core 数分配资源,不够时会出现资源等待的情况,这种简单的模式并不适用于多用户的场景,而 Yarn 的动态分配策略可以很好的解决这个问题,可以实现资源的动态共享以及更加灵活的调度策略,所以公司也是采用 Spark on Yarn 的模式。
但是,目前 Spark on Yarn 支持 2 种方式的提交,一种是 Client 模式,这种模 dirver 运行在客户端,运行情况会收到启动机器的影响,推荐使用 Cluster 模式,这种模式是将 driver 运行在 Yarn 集群上,可以在客户端启动进程消失后进行平稳的运行,同时运行日志也保存在 Yarn 集群上,方便管理和问题排查。
2. 集群上分配给 Spark Streaming 的核数一定要大于接收器的数量,一个核占据一个 core,否则的话只会接收,没有 core 进行 process。
3. Spark 有 2 中接收器,可靠接收器和不可靠接收器,可靠接收器保存数据时带有备份,只有可靠接收器发送 acknowledgment 给可靠的数据源才可以保证在 Spark 端不丢失数据。
来源:Spark技术日报

时间:2019-02-27 22:29 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]Spark 迁移到 K8S 在有赞的实践与经验
- [数据挖掘]Spark Operator 初体验
- [数据挖掘]如何实现Spark on Kubernetes?
- [数据挖掘]Spark SQL 物化视图技术原理与实践
- [数据挖掘]Spark on K8S 的最佳实践和需要注意的坑
- [数据挖掘]Spark 3.0重磅发布!开发近两年,流、Python、SQL重
- [数据挖掘]Spark 3.0开发近两年终于发布,流、Python、SQL重大
- [数据挖掘]Apache Spark 3.0.0 正式版终于发布了,重要特性全面
- [数据挖掘]Spark 3.0 自适应查询优化介绍,在运行时加速 Sp
- [数据挖掘]Flink SQL vs Spark SQL
相关推荐:
网友评论:















