HBase 协处理器入门及实战
HBase 和 MapReduce 有很高的集成,我们可以使用 MR 对存储在 HBase 中的数据进行分布式计算。但是在很多情况下,例如简单的加法计算或者聚合操作(求和、计数等),如果能够将这些计算推送到 RegionServer,这将大大减少服务器和客户的的数据通信开销,从而提高 HBase 的计算性能,这就是本文要介绍的协处理器(Coprocessors)。
HBase 的协处理器是从 0.92.0 开始引入的,参见 HBASE-2000。它的实现灵感来源于 Jeff Dean 在 LADIS 2009 分享主题 《Designs, Lessons and Advice fromBuilding LargeDistributed Systems》中关于 Google 的 BigTable 协处理器的分享。当时的 BigTable 协处理器具有以下功能:
每个表服务器的任意子表都可以运行代码;
客户端的高层调用接口;
跨多行的调用会自动拆分为多个并行化的 RPC 请求;
通过协处理器可以非常灵活的构建分布式服务模型,能够自动化扩展、负载均衡、应用请求路由等。
HBase 当然也想要一个这么好的功能,因为通过这个功能我们可以实现二级索引(secondary indexing)、复杂过滤(complex filtering) 比如谓词下推(push down predicates)以及访问控制等功能。虽然 HBase 协处理器受 BigTable 协处理器的启发,但在实现细节方面存在差异。HBase 为我们建立了一个框架,并提供类库和运行时环境,使得我们可以在 HBase RegionServer 和 Master 上运行用户自定义代码;而 Google 的 BigTable 却不是这样的。
协处理器支持的扩展
协处理器框架已经为我们提供了一些实现类,我们可以通过继承这些类来扩展自己的功能。这些类主要分为两大类,即 Observer 和 Endpoint。
Observer
Observer 和 RDMBS 的触发器很类似,在一些特定的事件发生时被执行。这些事件包括用户产生的事件,也包括服务器内部产生的事件。 目前 HBase 内置实现的 Observer 主要有以下几个:
WALObserver:提供控制 WAL 的钩子函数;
MasterObserver:可以被用作管理或 DDL 类型的操作,这些是集群级的事件;
RegionObserver:用户可以用这种处理器处理数据修改事件,它们与表的 Region 联系紧密;
BulkLoadObserver:进行 BulkLoad 的操作之前或之后会触发这个钩子函数;
RegionServerObserver :RegionServer 上发生的一些操作可以触发一些这个钩子函数,这个是 RegionServer 级别的事件;
EndpointObserver:每当用户调用 Endpoint 之前或之后会触发这个钩子,主要提供了一些回调方法。
Endpoint
Endpoint 和 RDMBS 的存储过程很类似,用户提供一些自定义代码,并在 HBase 服务器端执行,结果通过 RPC 返回给客户。比较常见的场景包括聚合操作(求和、计数等)。有了 Endpoint ,我们就可以充分利用服务器的资源,进行一些计算,大大提升计算的效率和通讯的开销。
协处理器编写和配置
下面我将通过介绍一个计数的例子来介绍 HBase 协处理器的使用。我们知道,HBase 自带了一个 count 命令用于计算某张表的行数,但是这个命令是单线程执行,效率非常低。我们可以通过 Endpoint 来实现一个计数类,并利用集群的资源来计算,最终将结果返回到客户端,客户端这边通过对结果进行汇总得到最终的结果。其实,HBase 自带了一个名为 RowCountEndpoint 的例子,里面就实现了计数逻辑。注意本文基于 HBase 1.4.0 进行介绍的,HBase 2.x 的代码已经有些变化,但大部分结构都类似。

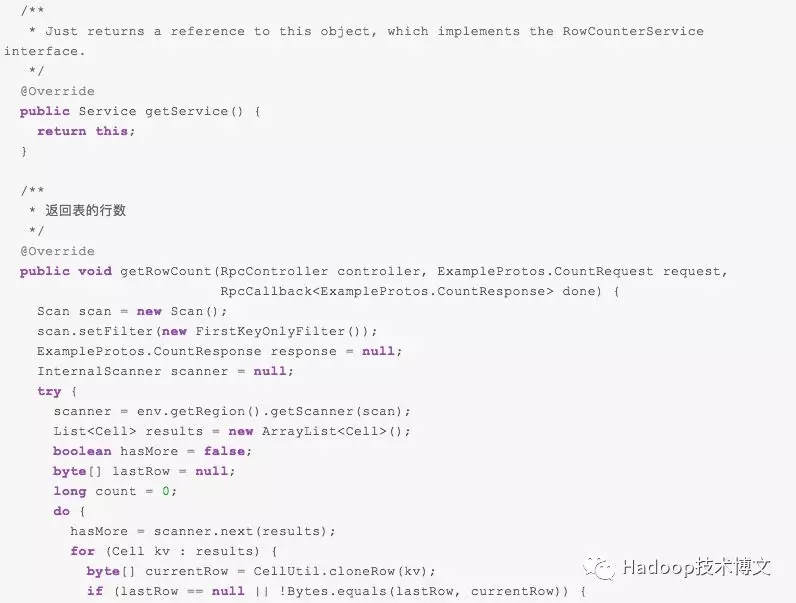
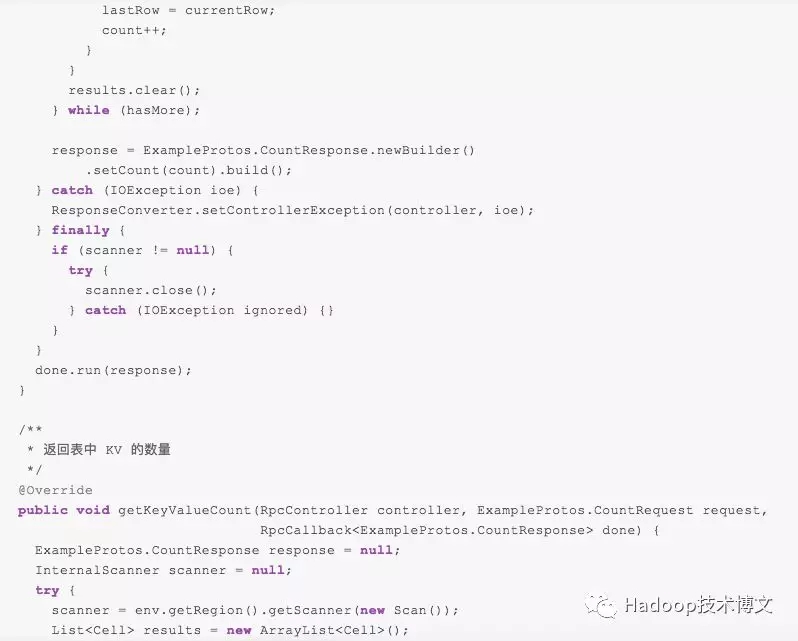
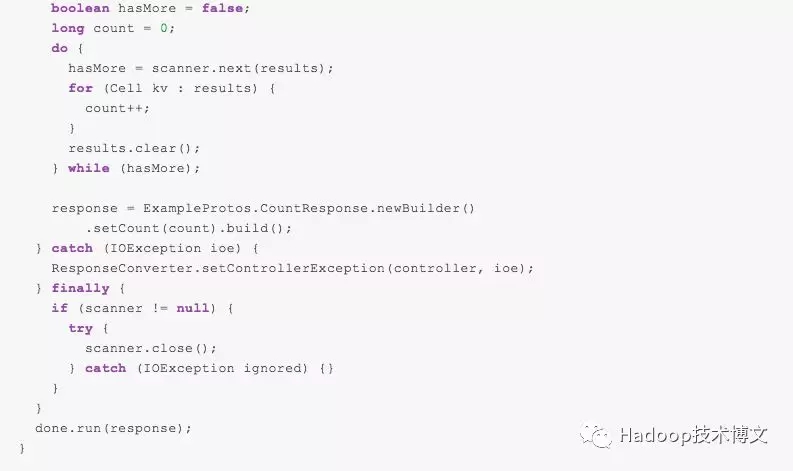

由于 HBase 内部使用 protobuf 协议进行通信,所以这个例子定义了名为 Examples.proto 的文件:

由于 RowCountEndpoint 类是 HBase 自带的例子,所以在我们的 HBase 类路径下已经加载了这个类,在实际的应用中,我们需要将 Examples.proto 文件生成对应的类,并将相关的类进行编译打包(具体如何编译可以参见 《在 IDEA 中使用 Maven 编译 proto 文件》)。因为这个类 HBase 其实已经编译好了,所以我就不再进行介绍了,直接讲如何部署。
协处理器部署
协处理器的部署有很多种方法,这里我将一一进行介绍。
通过 hbase-site.xml 文件进行配置
我们可以直接在 hbase-site.xml 文件里面进行配置,配置完之后需要重启 HBase 集群,而且这个配置是全局影响的。如下设置:

因为 RowCountEndpoint 这个类是 HBase 自带的,如果是我们自定义的 Endpoint,我们需要将打包好的 jar 包放到所有节点的 $HBASE_HOME/lib/ 路径下。
通过 HBase Shell 配置
如果我们只想对某一张表设置 Endpoint,那么可以直接在 HBase Shell 中进行配置,如下:

说明:上面的 coprocessor 设置的值为 '|org.apache.Hadoop.hbase.coprocessor.example.RowCountEndpoint ||',它的值主要由四部分组成。'coprocessor' => 'Jar File Path|Class Name|Priority|Arguments'。其中
Jar File Path:协处理器实现类所在 Jar 包的路径,这个路径要求所有的 RegionServer 能够读取得到。比如放在所有 RegionServer 的本地磁盘;比较推荐的做法是将文件放到 HDFS 上。如果没有设置这个值,那么将直接从 HBase 服务的 classpath 中读取。
Class Name:协处理器实现类的类名称,包括包名。
Priority:协处理器的优先级,是一个整数。如果同一个钩子函数有多个协处理器实现,那么将按照优先级执行。如果没有指定,将按照默认优先级执行。
Arguments:传递给协处理器实现类的参数列表,可以不指定。
这四个部分使用 | 符号进行分割。
通过 HBase API 配置
除了可以通过 HBase Shell 和 hbase-site.xml 配置文件来加载协处理器,还可以通过 Client API 来加载协处理器。具体的方法是调用 HTableDescriptor 的 addCoprocessor 方法。该方法有两种调用形式:
addCoprocessor(String className):传入类名。该方法类似通过配置来加载协处理器,用户需要先把jar包分发到各个 RegionServer 的 $HBASE_HOME/lib 目录下。
addCoprocessor(String className, Path jarFilePath, int priority, final Map kvs):该方法类似通过 Shell 来加载协处理器。通过调用该方法可以同时传入协处理器的 className 以及 jar 所在的路径,priority 是协处理器的执行优先级,kvs 是给协处理器预定义的参数。
使用如下:

如何判断协处理器设置生效
可以通过 HBase Shell 提供的 describe 命令查看的
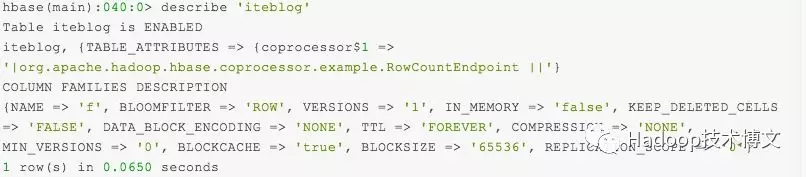
当然,我们也可以通过 HBase 提供的 UI 页面查看的,这里就不介绍了。
卸载协处理器
如果你需要卸载之前部署好的协处理器,可以使用下面命令实现:

使用协处理器
通过上面几步,我们已经为表设置好了协处理器,现在我们可以编写客户端程序来调用这个协处理器,主要通过 HTable 的 coprocessorService 方法实现,这个方法主要由三种实现:
coprocessorService(byte[] row):这个通过 row 来定位对应的 Region,然后在这个 Region 上运行相关的协处理器代码。
coprocessorService(final Class service, byte[] startKey, byte[] endKey, final Batch.Call callable):service 指定是调用哪个协处理器实现类,因为一个 Region 上可以部署多个协处理器,客户端必须通过指定 Service 类来区分究竟需要调用哪个协处理器提供的服务。startKey 和 endKey 主要用于确定需要与那些 Region 进行交互。callable 定义了如何调用协处理器,用户通过重载该接口的 call() 方法来实现客户端的逻辑。在 call() 方法内,可以调用 RPC,并对返回值进行任意处理。
coprocessorService(final Class service, byte[] startKey, byte[] endKey, final Batch.Call callable, final Batch.Callback callback):这个方法和第二个比较多了一个 callback,coprocessorService 会为每一个 RPC 返回结果调用该 callback,用户可以在 callback 中执行需要的逻辑,比如执行 sum 累加。第二个方法,每个 Region 协处理器 RPC 的返回结果先放入一个列表,所有的 Region 都返回后,用户代码再从该列表中取出每一个结果进行累加;用这种方法,直接在 callback 中进行累加,省掉了创建结果集合和遍历该集合的开销,效率会更高一些。
这里我们调用第二种方法,具体的代码如下:

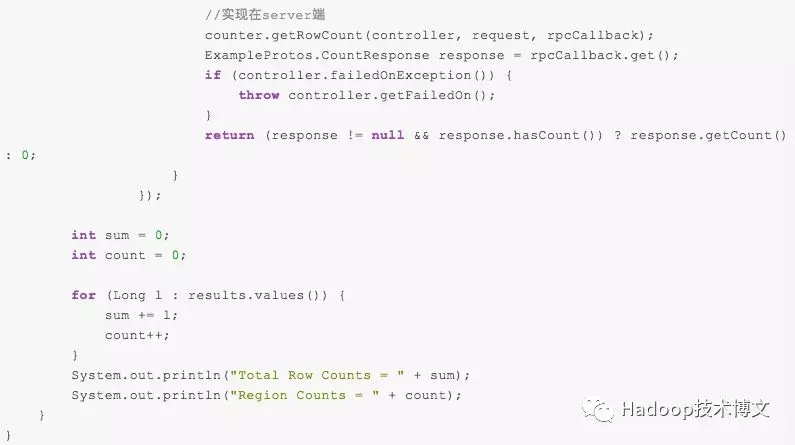
运行这段代码,就可以快速算出 iteblog 表的总行数。如果我们把 counter.getRowCount(controller, request, rpcCallback); 修改成 counter.getKeyValueCount(controller, request, rpcCallback);,那么将会返回 iteblog 表 KV 的总数。上面查询运行的流程可以用下面的图来表示
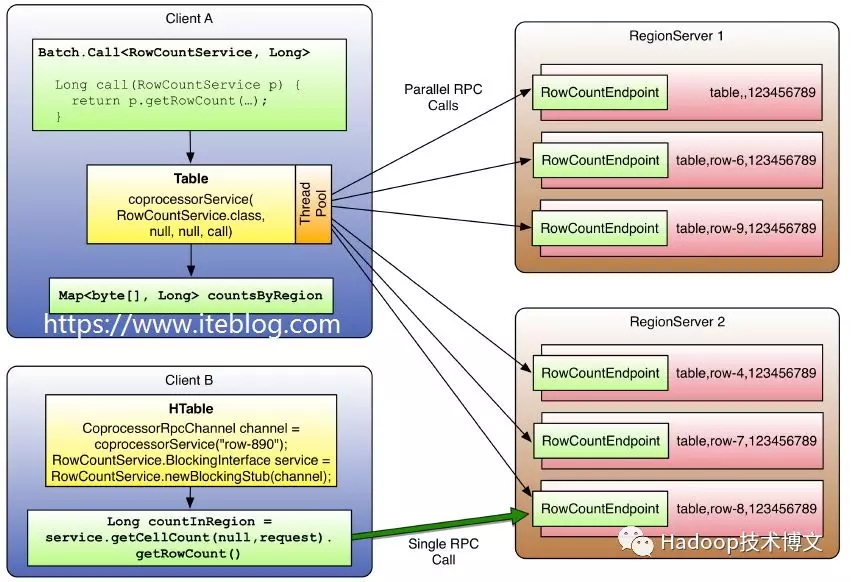
图中 Client A 的过程就是上面程序的处理流程,主要是并行 RPC 请求。从图中可以看到,这个表的所有 Region 都会参与计算,每个 Region 计算出自己的总数,然后返回给客户端,所有的 Region 结果最后存储在 Map results 中,其中 Key 是每个 Region 的名字,Value 就是这个 Region 计算到的行数。我们只需要遍历这个 Map,然后将所有 Region 计算的行数加起来就是整个表的行数。
如果我们仅仅想计算某个 row 对应的 Region 的行数,可以实现如下:

上面代码可以返回 row-890 所在 Region 的行数,由于这个 Row 只对应于一个 Region,所以上面代码的运行流程见上图的 Client B 运行过程。可以看出,这个程序仅仅发出一个 RPC 请求。
来自: Hadoop技术博文

时间:2019-02-27 22:29 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]Spark 迁移到 K8S 在有赞的实践与经验
- [数据挖掘]HBase数据迁移到Kafka?这种逆向操作你懵逼了吗?
- [数据挖掘]Spark Operator 初体验
- [数据挖掘]如何实现Spark on Kubernetes?
- [数据挖掘]Spark SQL 物化视图技术原理与实践
- [数据挖掘]Spark on K8S 的最佳实践和需要注意的坑
- [数据挖掘]Spark 3.0重磅发布!开发近两年,流、Python、SQL重
- [数据挖掘]Spark 3.0开发近两年终于发布,流、Python、SQL重大
- [数据挖掘]Apache Spark 3.0.0 正式版终于发布了,重要特性全面
- [数据挖掘]Spark 3.0 自适应查询优化介绍,在运行时加速 Sp
相关推荐:
网友评论:















