大数据生态之zookeeper(原理)
1. 集群的角色描述:
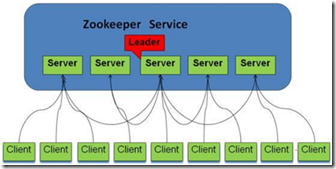

2. zookeeper的选主过程
(1)全新集群的选主:
根据启动的顺序和id进行选主(过半机制:集群中超过半数的集群可使用时,才开始选主)
以hadoop01(id=1)—hadoop02(id=2)---hadoop03(id=3)----hadoop04(id=r)----hadoop05(id=5)为例:
当hadoop01启动时,此时只有它一台服务器,,他发出取的报告没有任何相应,所有它的选举一直是looking状态。
Hadoop02启动:它与最开始启动的hadoop01进行通信,相互交换自己的选举结果,由于两者都没有历史数据,所以id值较大的服务器胜出,但是由于没有达到超过半数以上的服务器同意选举它(这个例子中的半数以上是 3),所有hadoop01、hadoop02还是继续保持looking状态。
Hadoop03启动,根据前面的分析,服务器 3 成为服务器 1,2,3 中的老大,而与上面不 同的是,此时有三台服务器(超过半数)选举了它,所Hadoop03它成为了这次选举的 leader
服hadoop04启动,根据上面的分析,理论上,hadoop04应该是服务器中id最大的,但是由前面已近有超过半数的服务器选举了hadoop03,所以hadoop04只能是follower
Hadoop05启动,与hadoop04一样,也是follower
zookeeper server的三种工作状态:
LOOKING:当前 Server 不知道 leader 是谁,正在搜寻,正在选举
LEADING:当前 Server 即为选举出来的 leader,负责协调事务
FOLLOWING:leader 已经选举出来,当前 Server 与之同步,服从 leader 的命令
(2)非全新集群的选主
leader 已经选举出来,当前 Server 与之同步,服从 leader 的命令,但是由于某种原因主节点宕机:
此时我们根据三个维度来选主:数据version、serverid、逻辑时钟。
数据version:数据新的version就大,数据每次更新,同时会更新它的version
Serverid:就是我们配置的 myid 中的值,每个机器一个
逻辑时钟:这个值从0开始,每一次选举对应一个值,也就是说,如果在同一次选举中,这个值应该一致,逻辑时钟越大,说明这一次选举leader人的进程更新,也就是每次选举拥有一个 zxid,投票结果只取 zxid 最新的
选举的标准:
逻辑时钟小的选举结果被忽略,重新投票
统一逻辑时钟后数据version大的胜出
逻辑时钟统一,version也相同,,server id 大的胜出。
根据以上的规则,快速选出集群的主节点。
3. zookeeper写数据的流程:
客户端发送写入数据的请求,这个请求最终会被leader处理
leader会先写入数据,写入完成之后通知follower进行数据的同步
follower就会开始进行数据的同步(并行,多台follower并行同步)
每一个follower只要数据同步完成就会向leader发送数据同步成功信息
leader接收到超过半数以上的成功信息后,则认为这次写数据成功
其他节点慢慢进行同步,在数据同步的过程中,不对外提供读写服务
4. zookeeper的数据的同步过程
follower连接leader并发送自己最大的zixd
leader进行对比,将自己最大的zxid和follower发送过来的zxid进行对比,如果leader的zxid大于follower的,则通知follower进行数据同步
follower发送数据同步请求
leader确定当前的follower的数据同步点(从follower最大的zxid到leader最大的zxid之间数据需要同步)
follower开始同步数据,这个过程不对外提供读写服务。
follower同步完成,发送消息给leader
leader就会修改当前的follower的状态为update,这个时候follower就可以接受客户端的读写请求,但是只能读,如果是写入请求,需要转发给leader
5. ZooKeeper 中各个角色的工作职责
(1)Leader
恢复数据
维持与follower的心跳,接收follower请求并判断follower的请求消息类型
根据不同的消息类型,进行不同的处理
(2)follower
向leader发送请求(同步数据,写入请求)
接收leader的消息并进行相应的处理
接收client的读写请求,如果是写入的请求转发给leader处理
返回client的读请求,查询的结果
作者:爱学习的小明-1993
来源:CSDN

时间:2019-02-16 23:13 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]ZooKeeper集群“脑裂”问题处理大全
- [数据挖掘]史上最便捷搭建 ZooKeeper 服务器的方法
- [数据挖掘]分布式锁用Redis好?还是Zookeeper好?
- [数据挖掘]ZooKeeper集群“脑裂”问题处理大全
- [数据挖掘]微服务架构:注册中心ZooKeeper、Eureka、Consul
- [数据挖掘]聊聊ZooKeeper的点
- [数据挖掘]分布式锁原理——redis分布式锁,zookeeper分布式锁
- [数据挖掘]分布式锁用 Redis 还是 Zookeeper?
- [数据挖掘]阿里巴巴为什么不用 ZooKeeper 做服务发现?
- [数据挖掘]图解!微服务为什么一定要Zookeeper?
相关推荐:
网友评论:















