面向数据科学和 AI 的开发库推荐:Python、R 各
本文作者 Favio Vázquez 是一位数据科学家、物理学家和计算机工程师,他从 2018 年初开始写作并发布《数据科学和人工智能每周文摘:Python & R》系列文章,为数据科学家介绍,能真正帮助他们更好地完成各项任务的最好的开发库、开源项目、安装包以及工具。随着一年结束,Favio Vázquez 也应读者需要,从该系列文章中盘点出了 Python/R 语言 7 大开发库。编译如下。
前言
如果你一直都有关注我,你就会知道今年我开始写作《数据科学和 AI 每周治摘要:Python & R》(Weekly Digest for Data Science and AI: Python & R)系列文章,在这些文章中,我列出了能帮助我们数据科学家更好地完成各类任务的最好的开发库、开源项目、安装包以及工具。
Heartbeat(https://heartbeat.fritz.ai/)上的大量用户对这些摘要给予了支持,并且他们还建议我从这些摘要中挑选出那些真正改变或改善了我们这一年的工作方式的开发库,创建一份「最最好」的开发库榜单。
如果你想要阅读之前的摘要,可以前往以下地址进行查看:
https://www.getrevue.co/profile/favio
免责声明:此清单基于我在个人文章中复盘的开发库和安装包,它们在某种程度上适用于程序员、数据科学家以及人工智能爱好者,其中一些是在 2018 年之前创建的,但是如果它们依旧具有趋势性,也同样可以被考虑使用。
面向 R 语言的 TOP 7 开发库

7. AdaNet—提供学习保证的快速、灵活的 AutoML
开源地址:https://github.com/tensorflow/adanet

AdaNet 是一个轻量级的、可扩展的 TensorFlow AutoML 框架,可使用 AdaNet 算法(点击查看相关论文:AdaNet: Adaptive Structural Learning of Artificial Neural Networks,https://arxiv.org/abs/1607.01097)来训练和部署自适用神经网络。AdaNet 集成了多个学习的子网,来降低设计有效的神经网络的固有的复杂度。
这个安装包可以帮助你选择最优的神经网络架构,实现自适用算法,来将神经架构当做子网的集成进行学习。
你使用这个包之前先要对 TensorFlow 有所了解,因为它实现了 TensorFlow Estimator 接口。然后它可以通过封装训练、评估、预测和服务导出来帮助简化机器学习编程。
你可以创建一个神经网络的集成,然后这个开发库可以帮助优化你的训练目标——让这个集成模型在训练集上的表现和它泛化到未见过的数据之间的能力两者之间取得平衡。
6. TPOT—使用遗传编程优化机器学习工作流的自动 Python 机器学习工具
开源地址:https://github.com/EpistasisLab/tpot

在之前的一篇摘要中(https://heartbeat.fritz.ai/weekly-digest-for-data-science-and-ai-python-and-r-volume-6-830ed997cf07),我谈到过 Python 领域面向自动机器学习的一个很好的开发库——Auto-Keras。现在我要谈谈针对自动机器学习的另一个很有趣的工具。
这个工具叫做基于树表示的工作流优化(Tree-based Pipeline Optimization Tool,TPOT),它是一个非常棒的开发库。它基本上是一个 Python 自动机器学习工具,使用遗传编程来优化机器学习工作流。
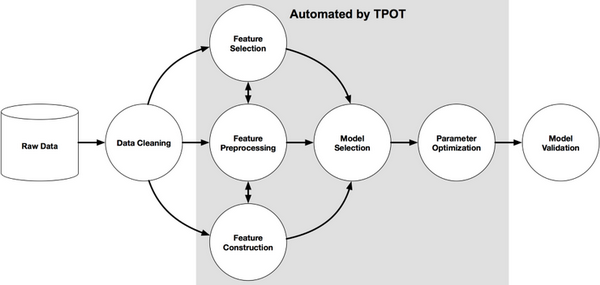
TPOT 可以实现特征选择、模型选择、特征构建等大量任务的自动化。幸运的是,如果你是一位 Python 机器学习者,TPOT 生成的所有代码都是你比较熟悉的——因为其创建在 Scikit-learn 之上。
它所做的就是通过智能地探索数千种可能的工作流,来为数据找到最好的那个,从而将机器学习最冗长的部分自动化,之后,它会为其所找到的最好的工作流生成 Python 代码,然后接下来你就可以对工作流进行修补了。
它的工作方式如下:
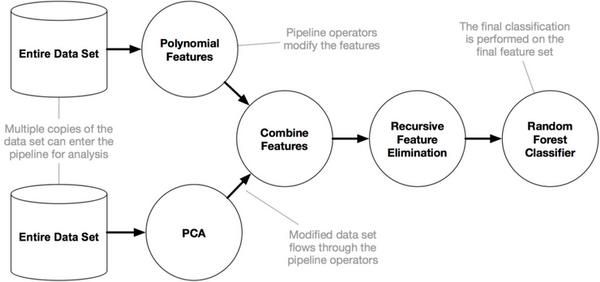
关于 TPOT 的更多细节,你可以阅读其他作者所写的这一系列文章:
Matthew Mayo,https://www.kdnuggets.com/2018/01/managing-machine-learning-workflows-scikit-learn-pipelines-part-4.html
Randy Olson,https://www.kdnuggets.com/2016/05/tpot-python-automating-data-science.html
5.SHAP——解释机器学习模型输出的统一方法
开源地址:https://github.com/slundberg/shap
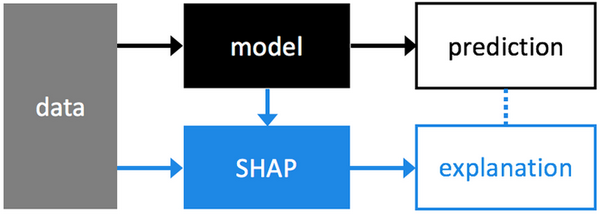
解释机器学习模型往往并不容易,但它对于一系列的商业应用却非常重要。幸运的是,现在有一些很好的开发库可以帮助解释机器学习模型。在许多应用中,我们需要了解、理解或者验证怎样在模型中使用输入变量,以及输入变量怎样影响最终的模型预测。
SHAP (SHapley Additive exPlanations) 是解释机器学习模型输出的统一方法,它将博弈论和局部解释关联起来,并将之前的一些方法进行了统一,然后基于解释,表示唯一可能的一致的、局部精确的加性特征属性方法。
可前往以下地址阅读更多 SHAP 相关信息:
https://github.com/slundberg/shap#sample-notebooks
4.Optimus——使用 Python 、Spark 即可轻易制作的敏捷的数据科学工作流
开源地址 :https://github.com/ironmussa/Optimus

坦诚地说,Optimus 这个开发库就像是我自己的孩子。现在为止,我已经花了很长时间来开发这个库,非常高兴能向大家展示 Optimus 的第二个版本。
Optimus V2 专门针对简化数据清洗而开发,它的 API 设计对于新手来说非常简单,之前使用 pandas 的开发者也会对其非常熟悉。Optimus 扩展了 Spark DataFrame 的功能,为其增加了.rows 和.cols 的属性。
由于 Optimus 的后端可以使用 Spark、TensorFlow 以及 Keras,你可以使用 Optimus 来清洗、准备以及分析数据,创建配置文件和图表,并运行机器学习、深度学习,而且所有这一切都是可以分布式运行的。
对于我们来说,Optimus 非常易于使用。它就像是带着点 dplyr 特色的、由 Keras 和 Spark 连接起来的 pandas 的进化版本。你使用 Optimus 创建的代码可以在你的本地机器上工作,同时只要简单改下命令,这个代码就可以在本地集群或者云端上运行。
为了帮助数据科学周期的每一个步骤,我为 Optimus 开发了大量有趣的功能。
作为数据科学敏捷方法的配套开发库,Optimus 可以说是完美的,因为它几乎能为数据处理过程中的每一步骤提供帮助,并且它可以轻易地与其他的开发库和工具连接起来。
如果你想要阅读更多关于敏捷方法的信息,可前往以下地址查看:
https://www.business-science.io/business/2018/08/21/agile-business-science-problem-framework.html
3.spaCy——结合 Python 和 Cython 使用的工业级的自然语言处理开发库
项目地址:https://spacy.io/

spaCy 针对帮助开发者完成真实产品开发、真实意见收集等实际工作而设计,它会最大程度地帮助你节约时间。该开发库易于安装,并且它的 API 非常简单和高效。我们喜欢将 spaCy 比作自然语言处理轨道上的「红宝石」(Ruby)。
spaCy 是为深度学习准备文本的最佳方式,它可以与 TensorFlow、 PyTorch、Scikit-learn、 Gensim 以及 Python 良好 AI 生态系统中的其他开发库无缝地互操作。你可以使用 spaCy,轻易地为各类 NLP 问题构建语言复杂的统计模型。
2.jupytext——相当于 Markdown 文档、Julia、Python 或者 R scripts 的 Jupyter notebooks
开源地址:https://github.com/mwouts/jupytext

对于我来说,jupytext 是年度最佳安装包之一,它对于我们数据科学家的工作非常重要。基本上,我们所有人都在 Jupyter 等类型的 notebook 上工作,但是我们也会使用 PyCharm 等 IDE 来完成项目更核心的部分。
现在的好消息是,在使用 jupytext 时,可以让你在最爱的 IDE 中拟草稿和测试的普通的脚本,会一目了然地以 Jupyter notebooks 的格式打开。在 Jupyter 中运行 notebook,可以生成输出,联合 .ipynb 表示,同时或者以普通的脚本或者以传统的 Jupyter notebook 的输出形式,来保存和分享你的研究工作。
下面的动图就展示了可以用这个包做的各种事情的工作流:
1.Charify—让数据科学家更容易创建图表的 Python 开发库
开源地址:https://github.com/chartify/chartify
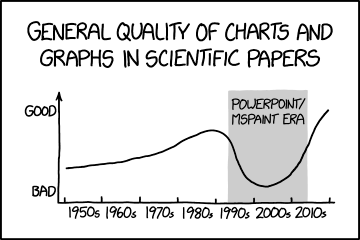
对于我来说,Chartify 是今年面向 Python 的开发库中排名第一的开发库。如果你从事 Python 相关工作,你可能要耗费大量的时间在尝试创建合适的图表上。幸运地是,我们有类似 Seaborn 这样的开发库可以让我们的工作变得更简单,但是它们的问题在于其图表不是动态的。之后,我们又有了 Bokeh 这样非常棒的开发库,但是用它创建交互式的图表是一件非常蛋疼的事情。如果你想知道更多关于 Bokeh 和针对数据科学的交互性图表,可以阅读 William Koehrsen 写的这些优秀的文章:
https://towardsdatascience.com/data-visualization-with-bokeh-in-python-part-one-getting-started-a11655a467d4
https://towardsdatascience.com/data-visualization-with-bokeh-in-python-part-ii-interactions-a4cf994e2512
https://towardsdatascience.com/data-visualization-with-bokeh-in-python-part-ii-interactions-a4cf994e2512
Chartify 创建于 Bokeh 之上,不过它要比使用 Bokeh 创建交互性图表简单得多。来自 Chartify 作者自己的介绍:
为什么使用 Chartify?
一致的输入数据格式:花费更少的时间转换数据格式就能开始在图表上处理数据,所有的图表函数都使用一致的、有条理的输入数据的格式。
智能的默认样式:只需要很少的用户自定义操作就可以创建好看的图表。
简单的 API:我们试图让 API 尽可能地直观易学。
灵活性:Chartify 创建于 Bokeh 之上,所以如果你需要进行更多控制操作,你可以依靠 Bokeh 的 API。
面向 R 语言的 TOP 7 开发库

7.infer—面向友好型 tidyverse 统计推断的 R 语言安装包
开源地址:https://github.com/tidymodels/infer
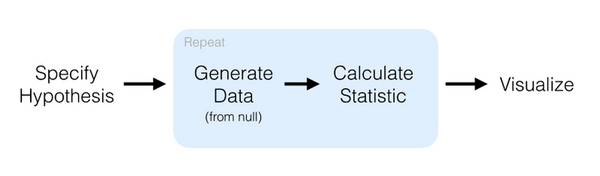
推断或者统计推断是使用数据分析来推断潜在概率分布的性质的过程。infer 这个安装包的目标是,使用与 tidyverse 设计框架保持一致的表达统计语法来执行统计推断。
如果你想要阅读更多关于 infer 的信息,可前往以下地址查看:
https://infer.netlify.com/index.html
6. janitor—用 R 语言进行数据清洗的简单工具
开源地址:https://github.com/sfirke/janitor

数据清洗是跟我关系紧密的领域。一直以来,我都在与我在 Iron-AI(https://iron-ai.com/)的团队一起开发一项面向 Python 语言的工具——Optimus,你可以在这里(https://hioptimus.com/)查看更多关于 Optimus 的信息。
不过,我现在给你展示的工具,是一个使用简单函数就能进行数据清洗的很厉害的工具——janitor。
它主要有三个主要的功能:
完美地对 data.frame 列名进行格式化
创建和格式化一个、两个或者三个变量的频率表,如一个优化的 table() ;以及
隔离部分重复的记录
同时,它也是一个面向 tidyverse(https://github.com/tidyverse/tidyverse/blob/master/vignettes/manifesto.Rmd)的安装包。特别地,它在与 %>% 管道一起执行的时候表现很好,并且为通过 readr(https://github.com/tidyverse/readr)和 readxl(https://github.com/tidyverse/readxl)两个包引入的数据的清洗做过优化。
5.Esquisse——使用 ggplot2 制作图表的 RStudio 插件
开源地址:https://github.com/dreamRs/esquisse

这个插件让你可以通过使用 ggplot2 安装包将数据可视化,来交互地搜索这些数据。它可以让你绘制条形图、曲线、散点图和柱状图,然后输出图表或者检索到代码来生成图表。
4.DataExplorer—自动数据检索和处理工具
开源地址:https://github.com/boxuancui/DataExplorer

探索性数据分析 (Exploratory Data Analysis,EDA,https://en.wikipedia.org/wiki/Exploratory_data_analysis)是创建数据分析/预测模型的关键阶段。在这个过程中,分析师/建模师会先浏览一下数据,然后做出一些相关的假设并决定下一步骤。然而,EDA 这一过程有时候会很麻烦。DataExplorer 这个 R 语言安装包旨在将大部数据处理和可视化实现自动化,从而让用户可以专注在研究数据和提取观点上。
如果你想要阅读更多关于 DataExplorer 的信息,可前往以下地址查看:
https://boxuancui.github.io/DataExplorer/articles/dataexplorer-intro.html
3.Sparklyr—面向 Apache Spark 的 R 接口
开源地址:https://github.com/rstudio/sparklyr

Sparklyr 有以下几项功能:
实现 R 和 Spark(http://spark.apache.org/)的连接。Sparklyr 安装包提供了一个完整的 dplyr(https://github.com/tidyverse/dplyr)后端。
筛选和聚合 Spark 数据集,然后将它们带入到 R 中进行分析和实现可视化。
使用 Spark 的 MLlib 机器学习开发库(http://spark.apache.org/docs/latest/mllib-guide.html)在 R 中执行分布式机器学习算法。
创建一个用于调用 Spark API 的扩展(http://spark.rstudio.com/extensions.html),并为 Spark 的安装包提供了一个接口。
如果你想要阅读更多关于 Sparklyr 的信息,可前往以下地址查看:
https://spark.rstudio.com/mlib/
2.Drake—针对复现性、高性能计算的以 R 语言为中心的工作流工具包
开源地址:https://github.com/ropensci/drake

Drake 编程项目
配图文字:(Drake是如何做程序员的:不喜欢真的编程,但是完全可以花30分钟和别人争论这个变量要起什么名字)
开玩笑的,不过这个安装包的名字真的就叫 Drake!

Drake 是一个非常棒的包,我之后将会发布一篇详细介绍它的文章,敬请期待!
Drake 是一个用在数据驱动任务中的通用的工作流管理工具。当中间的数据目标的依赖性发生改变时,它可以对这些中间的数据目标进行重建,同时,当结果出炉时,它会跳过这项工作。
此外,并不是每一个完整的工作都从数据抓取开始,而完整的工作流都可以切实表示出它们是具有复现性的。
可复现性、好的管理以及跟踪实验对于轻易地检测其他的工作和分析来说,都是必需的。在数据科学领域,Drake 是十分重要的,你可以前往以下地址阅读更多关于该工具包的信息:
Zach Scott:
https://towardsdatascience.com/data-sciences-reproducibility-crisis-b87792d88513
https://towardsdatascience.com/toward-reproducibility-balancing-privacy-and-publication-77fee2366eee
以及我所写的一篇文章:
https://towardsdatascience.com/manage-your-machine-learning-lifecycle-with-mlflow-part-1-a7252c859f72
Drake 可以帮助你实现自动地:
1. 开始处理与此前相比发生了改变的部分;
2. 跳过剩余的工作。
1.DALEX—描述性机器学习解释(Descriptive mAchine Learning EXplanations)
开源地址:https://github.com/pbiecek/DALEX

解释机器学习模型往往并不容易,不过,它对于一系列的商业应用非常重要。幸运的是,现在有一些很好的开发库可以帮助解释机器学习模型。
https://github.com/thomasp85/lime
(顺便一提,有时候,使用 ggplot 进行简单的可视化可以帮助你更好地解释模型。对此,Matthew Mayo 在其所写的文章中进行了很好的介绍:https://www.kdnuggets.com/2017/11/interpreting-machine-learning-models-overview.html)
在许多应用中,我们需要了解、理解或者验证怎样在模型中使用输入变量,以及输入变量怎样影响最终的模型预测。DALEX 是帮助解释复杂模型是怎样工作的一套工具。
via:https://heartbeat.fritz.ai/top-7-libraries-and-packages-of-the-year-for-data-science-and-ai-python-r-6b7cca2bf000?gi=27d5c4b5f4ef

时间:2019-01-11 12:58 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]底层I/O性能大PK:Python/Java被碾压,Rust有望取代
- [数据挖掘]RedMonk语言排行:Python力压Java,Ruby持续下滑
- [数据挖掘]不得了!Python 又爆出重大 Bug~
- [数据挖掘]TIOBE 1 月榜单:Python年度语言四连冠,C 语言再次
- [数据挖掘]TIOBE12月榜单:Java重回第二,Python有望四连冠年度
- [数据挖掘]这个可能打败Python的编程语言,正在征服科学界
- [数据挖掘]2021年编程语言趋势预测:Python和JavaScript仍火热,
- [数据挖掘]Spark 3.0重磅发布!开发近两年,流、Python、SQL重
- [数据挖掘]Python 为什么推荐蛇形命名法?
- [数据挖掘]Python才是世界上最好的语言
相关推荐:
网友评论:















