算法基础:五大排序算法Python实战教程
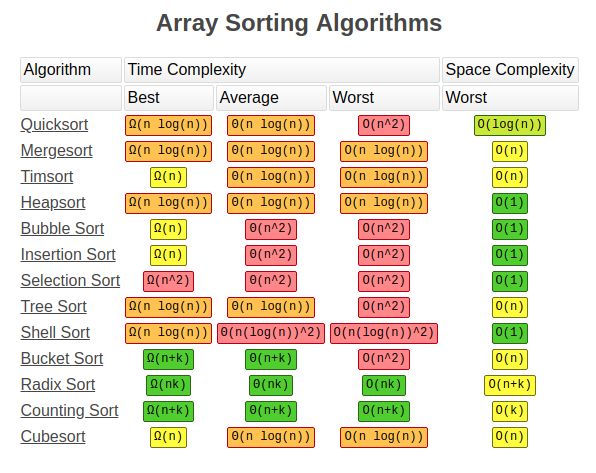
排序算法的复杂度
排序是每个软件工程师和开发人员都需要掌握的技能。不仅要通过编程面试,还要对程序本身有一个全面的理解。不同的排序算法很好地展示了算法设计上如何强烈的影响程序的复杂度、运行速度和效率。
让我们看一下前6种排序算法,看看如何在Python中实现它们!
冒泡排序
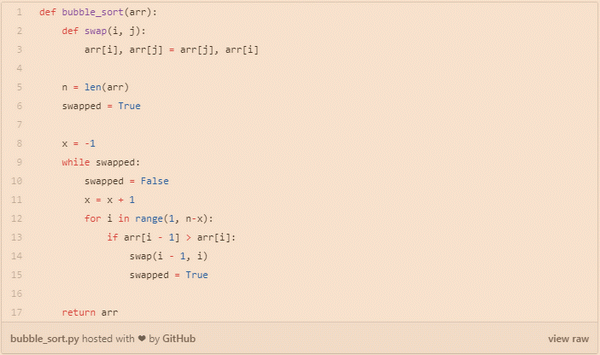
冒泡排序通常是在CS入门课程中教的,因为它清楚地演示了排序是如何工作的,同时又简单易懂。冒泡排序步骤遍历列表并比较相邻的元素对。如果元素顺序错误,则交换它们。重复遍历列表未排序部分的元素,直到完成列表排序。因为冒泡排序重复地通过列表的未排序部分,所以它具有最坏的情况复杂度O(n^2)。
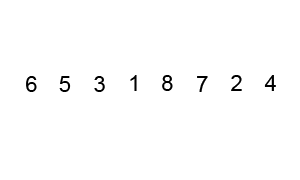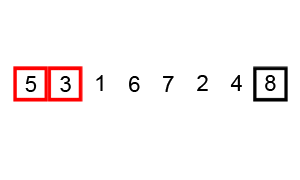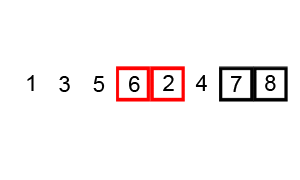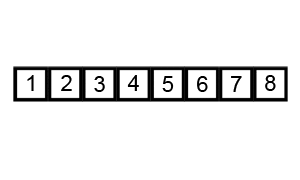
选择排序
选择排序也很简单,但常常优于冒泡排序。如果您在这两者之间进行选择,最好默认选择排序。通过选择排序,我们将输入列表/数组分为两部分:已经排序的子列表和剩余要排序的子列表,它们构成了列表的其余部分。我们首先在未排序的子列表中找到最小的元素,并将其放置在排序的子列表的末尾。因此,我们不断地获取最小的未排序元素,并将其按排序顺序放置在排序的子列表中。此过程将重复进行,直到列表完全排序。


插入排序
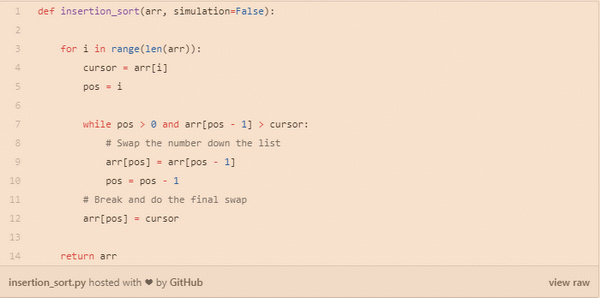
插入排序比冒泡排序和选择排序既快又简单。有趣的是,有多少人在玩纸牌游戏时会整理自己的牌!在每个循环迭代中,插入排序从数组中删除一个元素。然后,它在另一个排序数组中找到该元素所属的位置,并将其插入其中。它重复这个过程,直到没有输入元素。
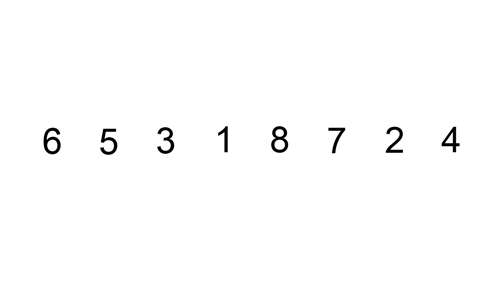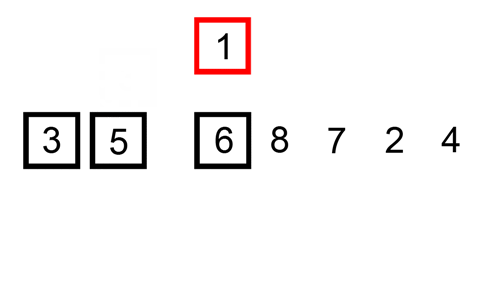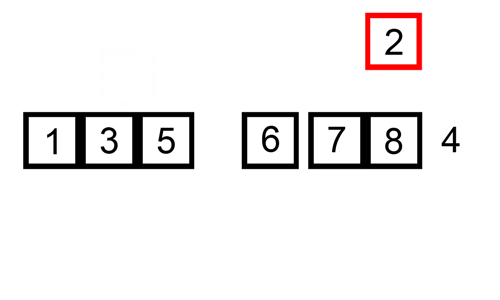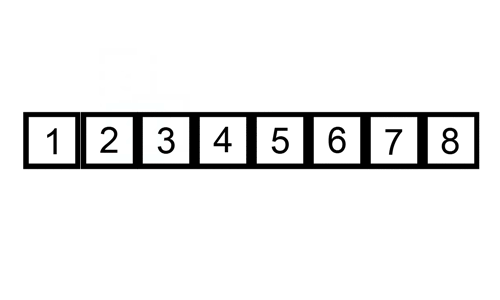
归并排序
归并排序是分而治之算法的完美例子。它简单地使用了这种算法的两个主要步骤:
(1)连续划分未排序列表,直到有N个子列表,其中每个子列表有1个“未排序”元素,N是原始数组中的元素数。
(2)重复合并,即一次将两个子列表合并在一起,生成新的排序子列表,直到所有元素完全合并到一个排序数组中。

快速排序
快速排序也是一种分而治之的算法,如归并排序。虽然它有点复杂,但在大多数标准实现中,它的执行速度明显快于归并排序,并且很少达到最坏情况下的复杂度O(n²) 。它有三个主要步骤:
(1)我们首先选择一个元素,称为数组的基准元素(pivot)。
(2)将所有小于基准元素的元素移动到基准元素的左侧;将所有大于基准元素的元素移动到基准元素的右侧。这称为分区操作。
(3)递归地将上述两个步骤分别应用于比上一个基准元素值更小和更大的元素的每个子数组。

原标题 :A tour of the top 5 sorting algorithms with Python code
作者:George Seif 翻译: 邓普斯•杰弗

时间:2019-01-08 22:58 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]底层I/O性能大PK:Python/Java被碾压,Rust有望取代
- [数据挖掘]RedMonk语言排行:Python力压Java,Ruby持续下滑
- [数据挖掘]不得了!Python 又爆出重大 Bug~
- [数据挖掘]TIOBE 1 月榜单:Python年度语言四连冠,C 语言再次
- [数据挖掘]TIOBE12月榜单:Java重回第二,Python有望四连冠年度
- [数据挖掘]这个可能打败Python的编程语言,正在征服科学界
- [数据挖掘]2021年编程语言趋势预测:Python和JavaScript仍火热,
- [数据挖掘]Spark 3.0重磅发布!开发近两年,流、Python、SQL重
- [数据挖掘]Python 为什么推荐蛇形命名法?
- [数据挖掘]Python才是世界上最好的语言
相关推荐:
网友评论:















