舍弃Python,为什么知乎选用Go重构推荐系统?

作者:孙付伟
知乎从问答起步,已逐渐生长为一个大范围的综合性学问内容平台,截止目前,用户数打破 2.2 亿,有超越 3000 万的问题被提出,并取得超越 1.3 亿个答复。同时,知乎内还沉淀了数量众多的优质文章、电子书以及其它付费内容。
因而,在链接人与学问的途径中,知乎存在着大量的引荐场景。粗略统计,目前除了首页引荐之外,我们已存在着 20 多种引荐场景;并且在业务快速开展中,不时有新的引荐业务需求参加。在这个背景之下,构建一个较通用的且便于业务接入的引荐系统就变成不得不做的事了。
重构引荐系统需求思索哪些要素?如何做技术选型?重构的过程中会遇到哪些坑?希望知乎的踩坑经历能给你带来一些考虑。
背景
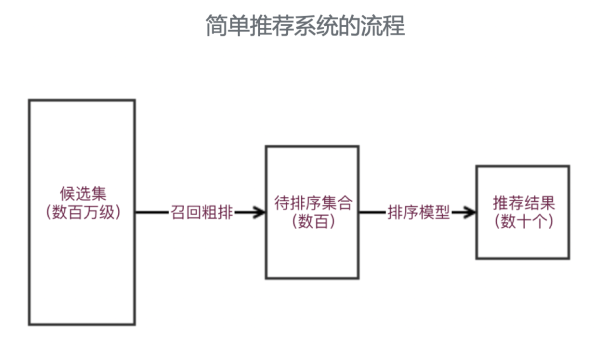
在讲通用架构的设计之前,我们一同回忆一下引荐系统的总体流程和架构。通常,由于模型所需特征及排序的性能思索,我们通常将简单的引荐系统分为召回层和 ranking 层,召回层主要担任从候选汇合中粗排选择待排序汇合,之后获取 ranking 特征,经过排序模型,选择出引荐结果给用户。
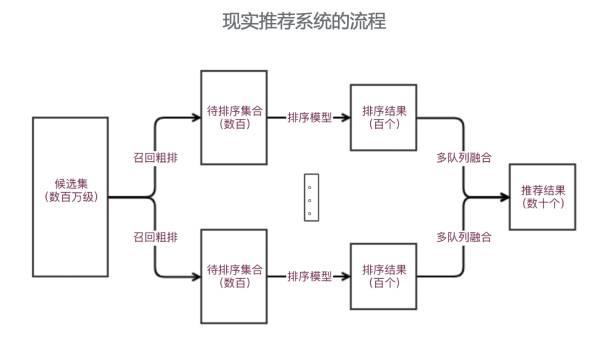
简单引荐模型合适一些引荐结果请求单一,只对单目的担任的引荐场景,比方新闻详情页引荐、文章引荐等等。但在理想中,作为通用的引荐系统来说,其需求思索用户的多维度需求,比方用户的多样性需求、时效性需求、结果的满足性需求等。因而就需求在引荐过程中采用多个不同队列,针对不同需求停止排序,之后经过多队列交融战略,从而满足用户不同的需求。
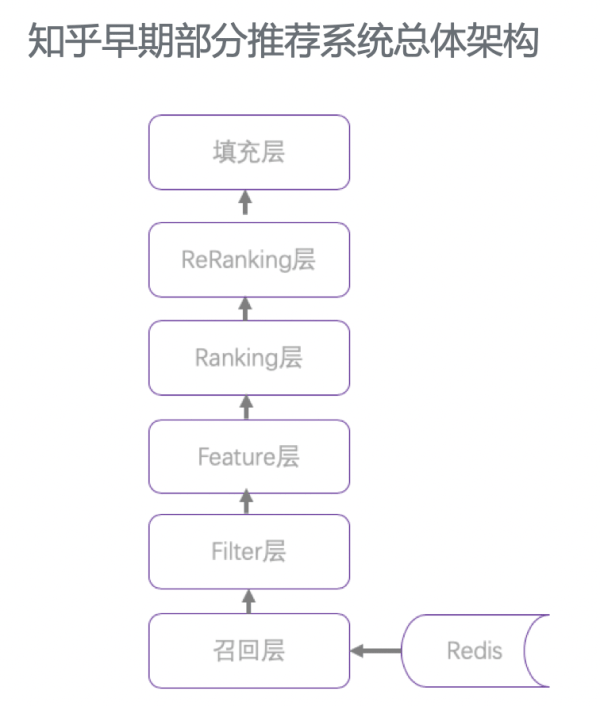
从我们知乎来说,也大致是这样一个开展道路,比方今年的 7 月份时,由于一些业务快速开展且架构上相对独立的历史缘由,我们的引荐系统存在多套,并且架构相对简单。以其中一个引荐架构设计相对完善的系统为例,其总体架构是这样的。能够看出,这个架构曾经包含了召回层和 ranking 层,并且还思索了二次排序。
那么存在哪些问题呢?
首先,对多路召回支持不友好。现有架构的召回是耦合在一同的,因而开发调研本钱高,多路召回接入相对艰难。
然后,召回阶段只运用 redis 作为召回根底。redis 有很多优点,比方查询效率高,效劳较稳定。但将其作为一切召回层的根底,就放大了其缺陷,第一不支持稍复杂的召回逻辑,第二无法停止大量结果的召回计算,第三不支持 embedding 的召回。
第三点,总体架构在完成时,架构逻辑剥离不够洁净,使得架构抽样逻辑较弱,各种通用特征和通用监控建立都较艰难。
第四点,我们晓得,在引荐系统中,特征日志的建立是十分重要的一个环节,它是引荐效果好坏的重要根底之一。但现有引荐系统框架中,特征日志建立缺乏统一的校验和落中央案,各业务『各显神通』。
第五点,当前系统是不支持多队列交融的,这就严重限制了通用架构的可扩展性和易用性。
因而,我们就准备重构知乎的通用引荐效劳框架。
重构之路
在重构前的思索
第一,言语的选择。早期知乎大量的效劳都是基于 Python 开发的,但在理论过程中发现 Python 资源耗费过大、不应用多人协同开发等各种问题,之后公司停止了大范围的重构,如今知乎在言语层面的技术选型上比拟开放,目前公司内部已有 Python、Scala、Java、Golang 等多种开发言语项目。那么关于引荐系统效劳来说,由于其重计算,多并发的特性,言语的选择还是需求思索的。
第二,架构上的思索,要处理支持多队列混排和支持多路召回的问题,并且其设计最好是支持可插拔的。
第三,召回层上,除了传统的 redis 的 kv 召回(局部 cf 召回,抢手召回等等应用场景),我们还需求思索一些其他索引数据库,以便支持更多索引类型。
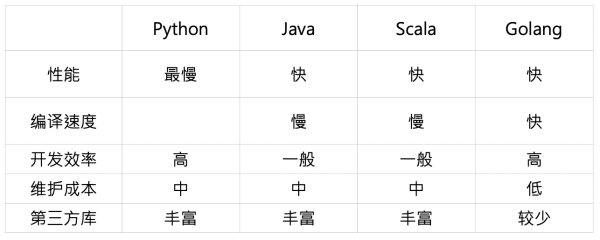
首先我们先看言语上的选择,先总体上比拟一下各种言语的特性,我们简单从如下几个方面停止比拟。
从性能上,按照公开的 benchmark,Golang 和 Java、Scala 大约在一个量级,是 Python 的 30 倍左右。其次 Golang 的编译速度较快,这点相关于 Java、Scala 具有比拟明显的优势,再次其言语特性决议了 Golang 的开发效率较高,此外由于缺乏 trycatch 机制,使得运用 Golang 开发时对异常处置考虑较多,因而其上线之后维护本钱相对较低。但 Golang 有个明显缺陷就是目前第三方库较少,特别跟 AI 相关的库。
那么基于以上优缺陷,我们重构为什么选择 Golang?
1、Golang 自然的优势,支持高并发并且占用资源相对较少。这个优势恰恰是引荐系统所需求的,引荐系统存在大量需求高并发的场景,比方多路召回,特征计算等等。
2、知乎内部根底组件的 Golang 版生态比拟完善。目前我们知乎内部关于 Golang 的运用越来越积极,大量根底组件都曾经 Golang 化,包括根底监控组件等等,这也是我们选择 Golang 的重要缘由。
但我需求强调一点,言语的选择不是只要独一答案的,这是跟公司技术和业务场景分离的选择。
讲完言语上的选择,那么为了在重构时支持多队列混排和支持多路召回,我们架构上是如何来处理的?
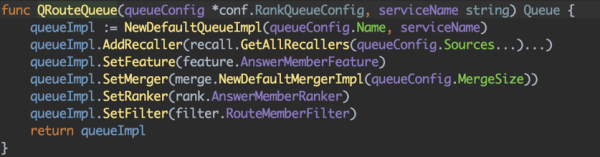
这点在设计形式比拟常见,就是『笼统工厂形式』:首先我们构建队列注册管理器,将回调注册一个 map 中,并将当前效劳一切队列做成 json 配置的可自在插拔的形式,比方如下配置,指定一个效劳所需求的全部队列,存入 queues 字段中,
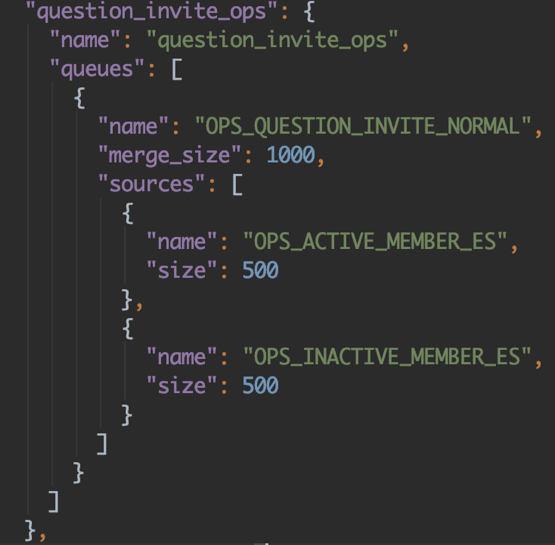
经过 name 来从注册管理器的 map 中调取相应的队列效劳,
之后呢我们就能够并发停止多队列的处置。
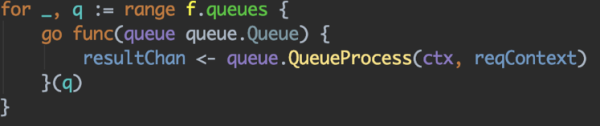
关于多路召回,及整个引荐详细流程的可插拔,与上面处置手法相似,比方如下队列
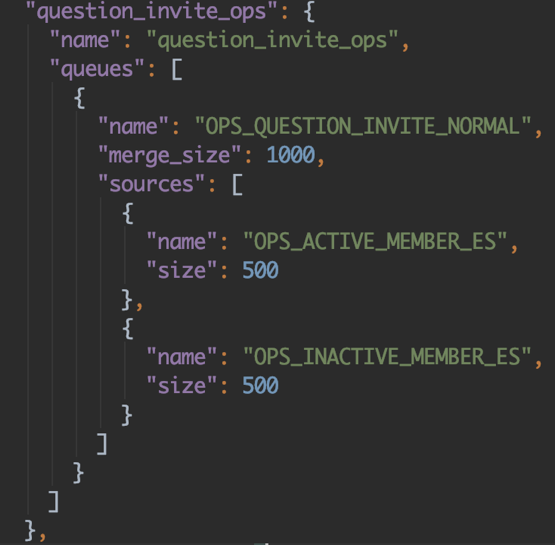
我们能够指定所需召回源,指定 merger 战略等等,当某个过程不需处置,会按自动默许步骤处置,这样在详细 Queue 的完成中就能够经过如下简单操作停止自在配置。
我们讲完了架构上一些考虑点和详细架构完成计划,下面就是关于召回层详细技术选型问题。
我们先回忆一下,在常用的引荐召回源中,有基于 topic(tag)的召回、实体的召回、地域的召回、CF(协同过滤)的召回以及 NN 产生的 embedding 召回等等。那么为了可以支持这些召回,技术上我们应该如何来完成呢?
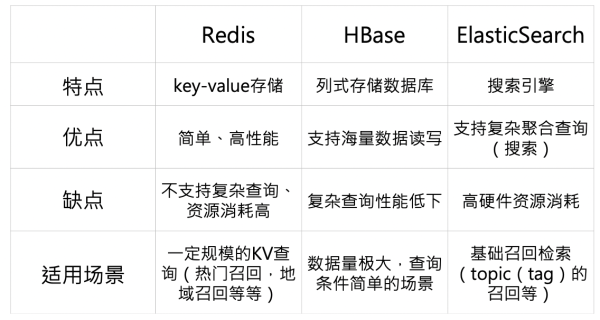
我们先从运用角度看一下常用的 NoSQL 数据库产品,Redis 是典型的 k-v 存储,其简单、并且高性能使得其在业内得到大量运用,但不支持复杂查询的问题也让 Redis 在召回复杂场景下并不占优,因而普通主要适用于 kv 类的召回,比方抢手召回,地域召回,少量的 CF 召回等等。而 HBase 作为海量数据的列式存储数据库,有一个明显缺陷就是复杂查询性能差,因而普通合适数据查询量大,但查询简单的场景,比方引荐系统当中的已读已推等等场景。而 ES 其实曾经不算是一个数据库了,而是一个通用搜索引擎范畴,其最大优点就是支持复杂聚合查询,因而将其用户通用根底检索,是一个相对合适的选择。
我们上面引见了通用召回的技术选型,那么 embedding 召回如何来处置呢,我们的计划是基于 Facebook 开源的faiss封装,构建一个通用 ANN(近似最近邻)检索效劳。faiss 是为稠密向量提供高效类似度搜索和聚类的框架。其具有如下特性:1、提供了多种 embedding 召回办法;2、检索速度快,我们基于 python 接口封装,影响时间在几 ms-20ms 之间;3、c++ 完成,并且提供了 python 的封装调用;4、大局部算法支持 GPU 完成。
从以上引见能够看出,在通用的引荐场景中,我们召回层大致是基于 ES+Redis+ANN 的形式停止构建。ES 主要支持相对复杂的召回逻辑,比方基于多种 topic 的混合召回;redis 主要用于支持抢手召回,以及范围相对较小的 CF 召回等;ANN 主要支持 embedding 召回,包括 nn 产出的 embedding、CF 锻炼产出的 embedding 等等。
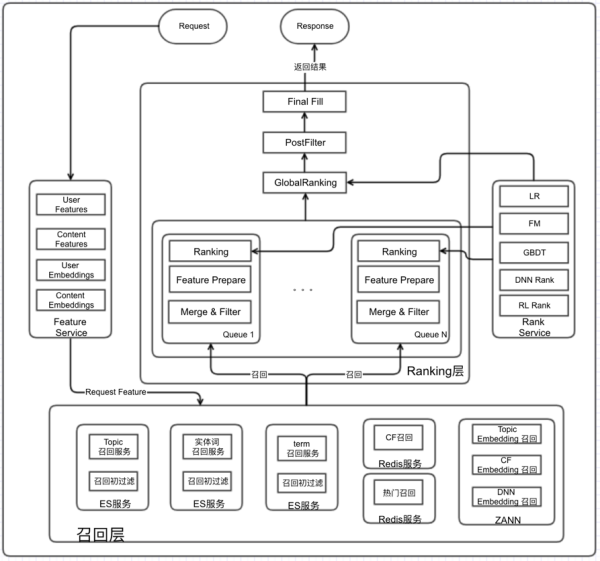
引见完以上考虑点,我们总体的架构就根本成型了,详细如下图所示。该框架能够支持多队列交融,并且每个队列也支持多路召回,从而关于不同引荐场景可以较好的支持,另外,我们召回选择了 ES+Redis+ANN 的技术栈计划,能够较好支持多种不同类型召回,并到达效劳线上的最终目的。
重构遇到的一些问题及处理计划
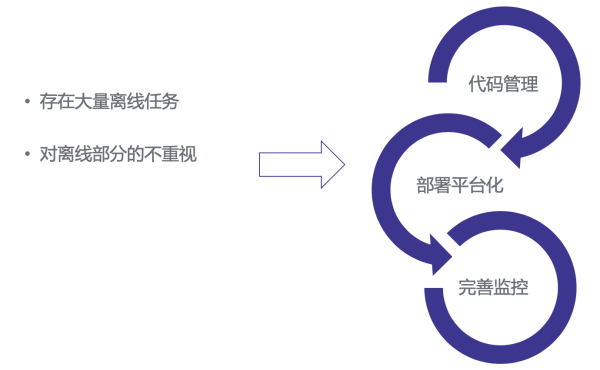
1、离线任务和模型的管理问题。我们做在线效劳的都有领会,我们经常容易对线上业务逻辑代码更关注一些,而常常无视离线代码任务的管理和维护。但离线代码任务和模型在引荐场景中又至关重要。因而如何有效维护离线代码和任务,是我们面临的第一个问题。
2、特征日志问题。在引荐系统中,我们常常会遇到特征拼接和特征的『时间穿越』的问题。所谓特征时间穿越,指的是模型锻炼时用到了预测时无法获取的『将来信息』,这主要是锻炼 label 和特征拼接时时间上不够严谨招致。如何构建便利通用的特征日志,减少特征拼接错误和特征穿越,是我们面临的第二个问题。
3、效劳监控问题。一个通用的引荐系统应该在根底监控上做到尽可能通用可复用,减少详细业务关于监控的开发量,并便当业务定位问题。
4、离线任务和模型的管理问题。
在包括引荐系统的算法方向中,需求构建大量离线任务支持各种数据计算业务,和模型的定时锻炼工作。但实践工作中,我们常常疏忽离线任务代码管理的重要性,当时间一长,各种数据和特征的质量常常无法保证。为了尽可能处理这样的问题,我们从三方面来做,第一,将通用引荐系统依赖的离线任务的代码统一到一处管理;第二,分离公司离线任务管理平台,将一切任务以通用包的方式停止管理,这样保证一切任务的都是依赖最新包;第三,建立任务结果的监控体系,将离线任务的产出完好监控起来。
5、特征日志问题。
Andrew Ng 之前说过:『发掘特征是艰难、费时且需求专业学问的事,应用机器学习其实根本上是在做特征工程。』我们理想中的引荐系统模型应该是有洁净的 Raw Data,便当处置成可学习的 Dataset,经过某种算法学习 model,来到达预测效果不时优化的目的。
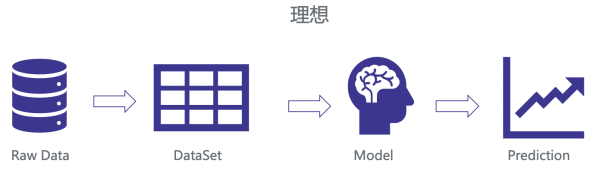
但理想中,我们需求处置各种各样的数据源,有数据库的,有日志的,有离线的,有在线的。这么多来源的 Raw Data,不可防止的会遇到各种各样的问题,比方特征拼接错误,特征『时间穿越』等等。
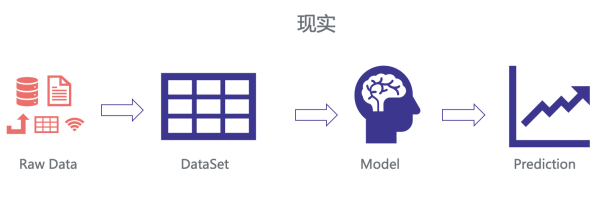
这里边反响的一个实质问题是特征处置流程的标准性问题。那么我们是如何来处理这一点呢,首先,我们用在线替代了离线,经过在线落特征日志,而不是 Raw Data,并统一了特征日志 Proto,如此就能够统一特征解析脚本。
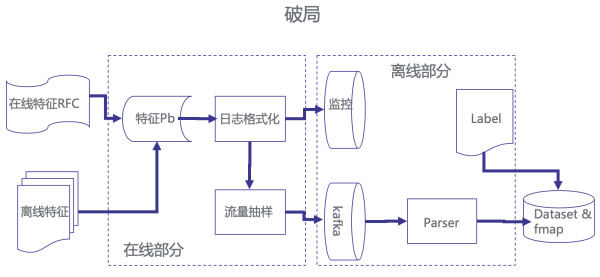
6、效劳监控问题。
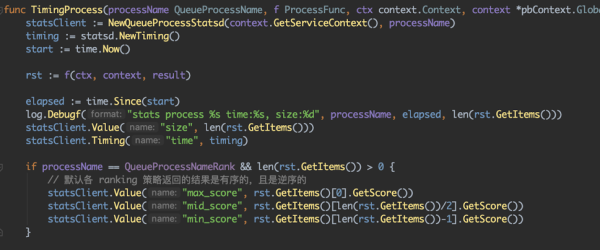
在监控问题上,知乎搭建了基于 StatsD + Grafana + InfluxDB 的监控系统,以支持各种监控日志的搜集存储及展现。基于这套系统,我们能够便利的构建本人微效劳的各种监控。
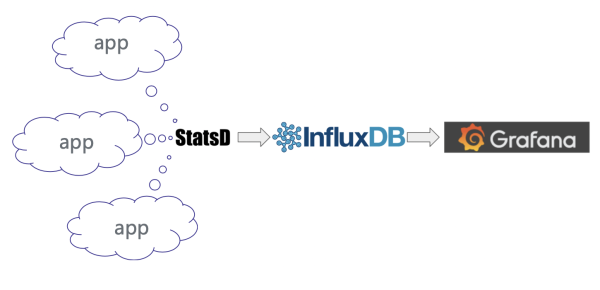
我们这里不过多引见通用监控系统,主要引见下,基于引荐系统我们监控建立的做法。首先先回忆一下我们引荐系统的通用设计上,我们采用了『可插拔』的多队列和多召回的设计,那么能够在通用架构设计获取到各种信息,比方业务线名,业务名,队列名,process 名等等。如此,我们就能够将监控运用如下方式完成,这样就能够通用化的设计监控,而不需各个引荐业务再过多设计监控及相关报警。

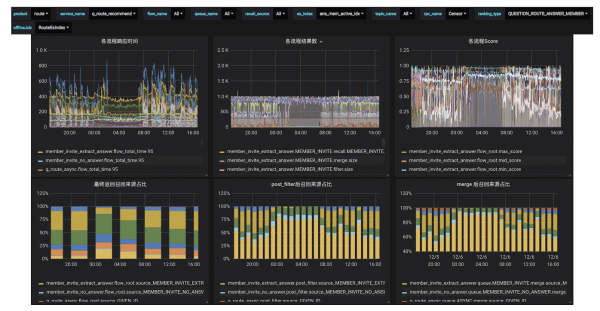
依照如上完成之后,我们引荐系统的监控体系大约是什么样子?首先各个业务能够经过 grafana 展现页面停止设置。我们能够看到各个 flow 的各种数据,以及召回源的比例关系,还有特征散布,ranking 得分散布等等。
将来应战
讲完了遇到的一些问题之后,我们来看一下将来的应战。随着业务的快速开展,数据和范围还在不时扩张,架构上还需求不时迭代;第二点,随着引荐业务越来越多,战略的通用性和业务之间的隔离如何谐和分歧;第三点,资源调度和性能开支也需求不时优化;最后,多机房之间数据如何坚持同步也是需求思索的问题。
总结
最后,我们做个简单总结:第一点,重构言语的选择,关键要跟公司技术背景和业务场景分离起来;第二点,架构尽量灵敏,并不时自我迭代;第三点,监控要早点展开,并尽可能底层化、通用化。
团队引见
我们是知乎的引荐技术团队,属于知乎的技术中台,主要为公司各个业务方提供完好的引荐效劳,其中包括问题路由、知乎大学的引荐和搜索、答复引荐、文章引荐、视频引荐、和知乎个性化 Push 等多个引荐场景。在这里,我们除了建立通用引荐效劳架构之外,还不时将最新的引荐算法应用到详细引荐业务中,提升用户体验,满足用户需求。

时间:2018-12-27 22:19 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]精通哪些编程语言的程序员更“吃香”?
- [数据挖掘]底层I/O性能大PK:Python/Java被碾压,Rust有望取代
- [数据挖掘]TIOBE 3 月编程语言:Swift 一路低走,Java 份额大跌
- [数据挖掘]RedMonk语言排行:Python力压Java,Ruby持续下滑
- [数据挖掘]不得了!Python 又爆出重大 Bug~
- [数据挖掘]TIOBE 1 月榜单:Python年度语言四连冠,C 语言再次
- [数据挖掘]TIOBE12月榜单:Java重回第二,Python有望四连冠年度
- [数据挖掘]这个可能打败Python的编程语言,正在征服科学界
- [数据挖掘]2021年编程语言趋势预测:Python和JavaScript仍火热,
- [数据挖掘]十年后将要消失的五种编程语言
相关推荐:
网友评论:















