浅谈人工智能在流媒体领域的应用
人工智能正加速改变各个行业,而流媒体领域可能是其中改变最快的一个。随着神经网络相关算法问题得到解决,人工智能技术在最近几年得到了快速的发展,而人工智能技术在流媒体领域的渗透,使这项技术获得了新的突破。当下图片、长视频、短视频、直播、AR等各种媒体形式占据着互联网圈,在媒体内容和形式都非常丰富的今天,如何辨识、解析这些内容,并通过人工智能反馈是目前所有科技巨头关注的焦点,其中图像识别、语音语义识别、同声传译、字幕识别等应用场景的进一步挖掘,需要人工智能大战拳脚。
什么是人工智能?
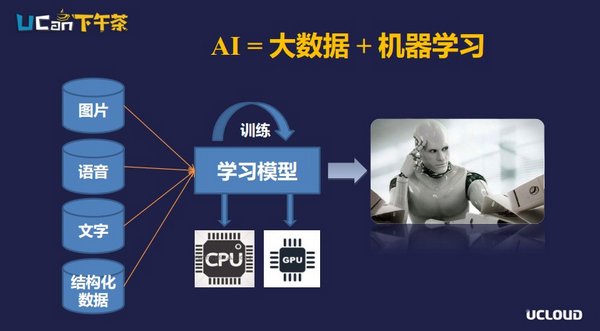
通俗一点讲,人工智能就是大数据+机器学习。这跟我们人类很像,我们想要获取知识的话,需要很多的源材料,比如通过观察外边的世界,去阅读各种书籍,或者请教老师、他人等。对于计算机来说也是这样的原理,它需要获取大量的数据去做训练,在大量数据里边抽取出有用的信息,构成它的知识库。
数据是人工智能的基础
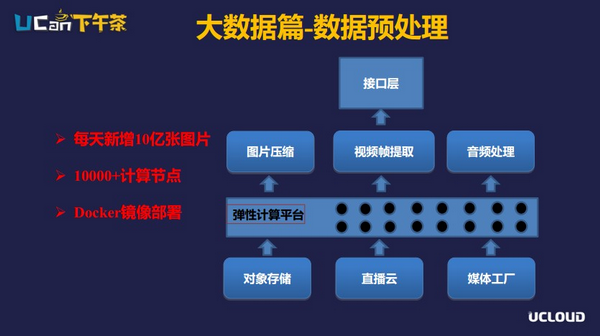
数据是人工智能技术实现的基础,在UCloud平台中,数据处理是如何操作的呢?首先,我们我们的对象存储、直播云、媒体工厂每天会产生大量的原始数据,比如对象存储每天新增的图片会超过10亿张,但是这些原始数据并不一定是对计算机友好的,例如直播数据,里面有传输的协议、音视频的交错,还有各种编码在里面,这样的原始的数据对机器学习来说是不友好的。我们就需要预处理的平台对原始数据进行处理,譬如图片压缩、音频提取与声道、采样率归一化、视频的抽帧等,这些预处理的功能目前采用docker镜像部署的方式跑在我们的弹性计算平台上,目前有超过10000个虚拟节点在做这个事情。
仅有数据还是不够的,我们需要对数据打上标签,让计算机知道这个东西是什么,然后它通过数据标签去训练和想学习,认识这一类的事物。目前打标签有多种形式,如人工标注、关键字主动抓取等,对于难于标注的语音类的数据,我们也会购买第三方的数据。数据是人工智能的基础,未来在人工智能这个领域,数据层面的竞争将会非常激烈。
机器学习解决哪些问题?
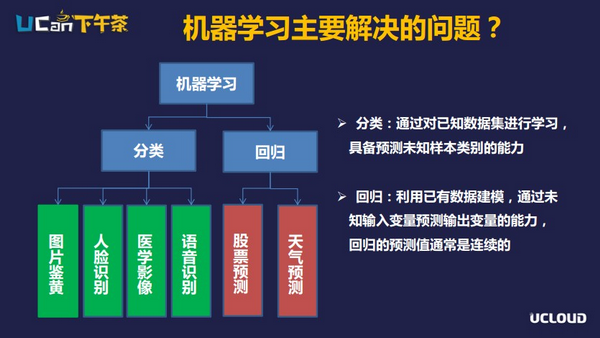
人工智能的另外一个重要环节机器学习,它解决的主要是两类问题,一是分类,二是回归。
分类目前应用得比较广泛,也相对成熟一些,如图片的分类,给出一张图片,识别这个图片是小猫还是小狗;或是对文字内容的分类,比如让计算机去分析一篇文章到底是体育类的还是经济类的等等。回归则是数学的概念,它处理的问题也是偏数学方向的,输入和输出都是数字类型的。据了解,目前有些团队在做类似股票预测的场景,像这种场景依赖的变量非常多,而且本身系统非常复杂,难度比较大。
分类功能在媒体领域的应用
在当下这个内容为王的时代,分类和回归在媒体方面的应用十分广泛,如内容审核、人脸识别、自动标签、字幕识别、同声传译等。
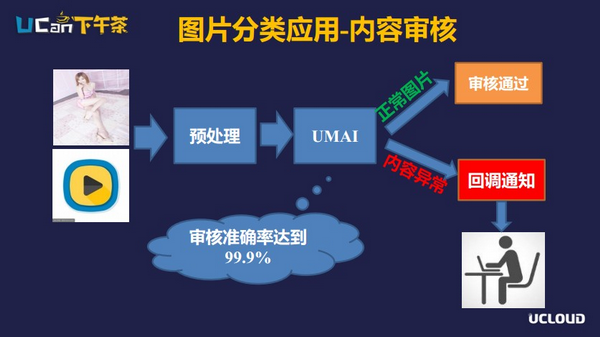
【内容审核】
目前大多数的内容平台对用户都是开放的,用户可以上传图片、视频等。开放本身是好事,使得内容更加丰富,但会涉及到很多网络监管问题,在国家和政府对网络内容的监管要求越来越严格的背景下,很多内容平台公司会专门成立内容审核部门,采用人工审核的方式,对用户上传内容进行全量审核。这项工作如果完全依赖人力审核的话是一项巨大的工程,且审核团队的工作枯燥乏味。
目前UCloud的UMAI平台支持图片与视频的涉黄、暴力等内容识别,通过调用UMAI接口来对内容做预处理,可以将占比为绝大多数的正常内容过滤掉,而只留下极少数判定为疑似不健康的内容,需要审核团队进行进一步的复查,这样极大的减少了人工审核的工作量。
【人脸识别】
人脸识别现在在人工智能这块应用较为广泛,如身份认证、手机刷脸、系统登录等;另外是人脸的搜索,比如在一段视频里快速确定有没有出现某个关键人物,或一个图片集里有没有包含这样的人。人脸识别主要的流程一般如下,首先对这个图片进行人脸的检测,然后提取关键点,包括眼睛、鼻子、嘴巴、耳朵、轮廓等,切分处理以后,再给到卷积网络提取特征,最后再做人脸识别,目前我们在公司考勤、政治任务识别方面已有相关的应用。
【自动标签】
针对用户自主上传的图片,自动标签则发挥出重要作为。用户在上传图片的时候,往往只会标注一到两个关键词,对图片进行描述,而图片里边包含的大量其他的内容和信息,是没办法检索出来的,因为现在很多后台的搜索是基于关键字的。通过计算机视觉的场景识别功能,可以很好的将图片的隐藏信息挖掘出来,让图片有更多的关键字,能够被更多的场景检索出来,发挥其作用。
【字幕识别】
字幕识别的应用非常直接而实用,例如身份证、发票、名片的识别,可以减少手写录入的工作量,而类似视频字幕识别这种,则可以帮助计算机更好地去理解视频的内容。
【同声传译】
目前国内企业出海风潮正盛,利用人工智能实现同声传译可以帮助跨国公司、员工进行不同语种间的交流。在视频直播这一块,我们做了这样的系统,可以在视频直播传输前,把里面的音频提取出来,做切片处理以后,把语音识别出来,经过翻译系统后输出字幕并打上时间戳,播放终端拿到字幕和视频数据后,做一次时间戳同步,在播放端进行展示。
这个系统主要有两个难点:一是它是经过了两次计算机的识别,第一次是语音的识别,第二次是翻译,这会有一个误差的累积;二是这种场景的实时性要求比较高,比如说字幕的翻译有点滞后,视频数据又需要比较低的延迟,这样体验会非常不好。这也是这款产品正在优化的两个方向。
人工智能私有化部署应用
以上提及的是聚焦于公有云平台的人工智能的应用,而我们在跟很多客户的交流中,因为政策以及保密的原因,他们不希望将数据放到公有云上,在他们内部也有不少服务器、视频采集设备等硬件资源,希望能够直接利用上。针对这样的需求,我们会建议使用私有化部署的方案。

UCloud平台做了两件事去实现私有化部署的方案:第一是组件化,我们内部有很多功能,比如直播、存储、录制、截图等,我们将这些功能剥离开,做成各种组件的形式。这样有一个好处,组件可以灵活搭配,用户需要什么功能就部署什么组件,如果对某些功能有个性化需求,只要简单修改对应组件的功能就可以了。第二是我们提供训练好的模型,部署到客户的私有环境中,目前这个模型是在我们公有云上训练好的。
私有化部署在自动考勤系统等场景已经有成熟的应用,我们也在不断挖掘更多可应用的场景,希望运用人工智能技术让我们的工作更便利、生活更美好。

时间:2018-11-11 23:39 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















