初探:企业数据湖治理最佳实践!
通常,那些刚接触大数据的人,甚至是精通Hadoop的老手,都会尝试使用不同的脚本、工具和第三方供应商来组建几个集群并拼凑在一起,这既不符合成本效益,也不可持续。本文,作者将描述数据湖与集群拼凑方式相比的优势是什么,集群如何规划和治理才能构建有效的数据湖。
数据湖正在成为一种越来越可行的解决方案,用于企业从大数据中提取价值,并代表早期大数据采用者合乎逻辑的下一步。这一概念是2011年提出来的,最初的数据湖是对数据仓库的一个补充,主要是为了解决数据仓库开发周期漫长,开发和维护成本较高,细节数据丢失等问题。数据湖大多相对于传统的基于RDBMS的数据仓库,在隔离的逻辑区域中提供结构化、非结构化和历史数据的灵活性,这已经和安全性一起为企业带来了一系列转型的可能。
然而,许多潜在用户无法理解可用数据湖的定义。通常,那些刚接触大数据的人,甚至是精通Hadoop的老手,都会尝试使用不同的脚本、工具和第三方供应商来组建几个集群并拼凑在一起,这既不符合成本效益,也不可持续。本文,作者将描述数据湖与集群拼凑方式相比的优势是什么,集群如何规划和治理才能构建有效的数据湖。
区域
在数据湖中,区域允许数据的逻辑或物理分离,从而保护整体环境的安全性、有序性和敏捷性。通常,建议企业使用3或4个区域,但可以使用更少或更多区域。通用的4区系统可能包括以下内容:
Transient Zone(瞬态区域)——用于在获取之前短暂保存数据,例如临时副本,流式spool或其他短期数据。
Raw Zone(原始区域)——存放原始数据的区域,该区域敏感数据必须加密,标记化或以其他方式保护。
Trusted Zone(受信任区域)——对原始区域中的数据执行数据质量、验证或其他处理后,它将成为此区域中下游系统的“真实数据来源”,也就是说其下游系统会从该区域获取数据。
Refined Zone(再处理区)——操作和丰富的数据保存在此区域,这用于存储来自Hive或外部工具等的输出,这些工具将写入数据湖中。
这种区域划分可以根据需要适应企业的业务规模、成熟度和特殊用例,但将通过专用服务器或者集群实现物理隔离,通过故意构建目录和访问权限进行逻辑分离,或者两者进行特别组合。在视觉上,这种架构类似于下面的架构。
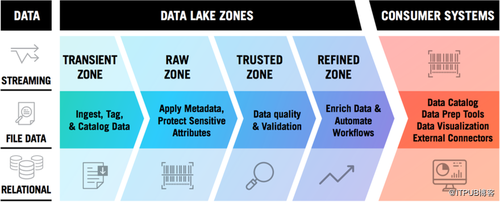
建立和维护定义明确的区域是创建健康湖泊的重要步骤。同时,了解哪些区域不提供灾难恢复或数据冗余策略也是非常重要的。尽管可以在DR中考虑该问题,但仍然需要投资可靠的底层基础架构以确保冗余和恢复能力。
Lineage
随着新数据源的不断添加以及现有数据源的更新或修改,维护数据集内部关系之间的记录变得更加重要。这些关系就像重命名列一样简单,也可能像连接不同源的多个表一样复杂,每个表本身可能有多个上游转换。在此上下文中,lineage有助于提供跟踪性以了解字段或数据集的来源以及审计跟踪,并了解更改的位置、时间和原因。听起来简单,但是当数据在湖中移动时捕获有关数据的细节非常困难,即使今天部署了一些专门的软件。跟踪的整个过程涉及事务级别(访问数据和做了什么?)以及结构或文件系统级别(数据集和字段之间的关系是什么?)等问题。数据湖中包括数据的批和流处理工具(例如MapReduce和Spark),以及可能操纵数据的任何外部系统,例如RDBMS系统。lineage可填补传统系统的部分空白,特别是随着GDPR等新法规的出现——灵活性和可扩展性是未来管理的关键。
数据质量
在数据湖中,并非所有数据都相同。因此,定义数据源以及管理和使用数据至关重要。通过清理来自各种物联网设备或社交媒体的数据,可以获得很多价值。企业还可以考虑在消费方而不是采购方应用数据质量检查。因为,单个数据质量体系结构可能不适用于所有类型的数据。必须注意的是,如果数据被“清理”,用于分析的结果可能会产生影响。修复数据集中值的字段级数据质量规则可以影响预测模型结果,因为这些修复可以影响异常值。通过比较“数据集的预期与接收大小”或“空值阈值”来衡量数据质量规则是否可用可能更适合此类情况。通常,所需验证的级别受传统限制或已经存在的内部流程影响,在设置新规则之前评估公司的现有流程是必须的。
隐私与安全
健康数据湖的关键组成部分是隐私和安全性,包括基于角色的访问控制、身份验证、授权以及静态和动态数据加密等。从纯数据湖和数据管理的角度来看,最重要的往往是数据混淆,包括标记化和数据屏蔽。应该使用这两个概念来帮助数据遵守最小特权的安全概念。限制数据访问也对许多希望遵守法规的企业具有意义。限制访问有几种形式,最明显的是存储层中区域的大量使用。简而言之,可以配置存储层中的权限,使得以最原始格式访问数据非常有限。由于该数据随后通过标记化和掩蔽(即隐藏PII数据)进行转换,因此可以将对后续区域中的数据访问扩展到更大的用户组。
DLM
企业必须努力发展其数据管理战略,以更有效地保护和服务其数字资产。这涉及投入时间和资源来完全创建生命周期管理策略,并确定是使用扁平结构还是利用分层保护。数据生命周期管理的前提是基于数据创建、使用和存档这一事实。如今,这个前提可能适用于某些交易数据。企业应该了解信息、数据和存储介质的相同点和差异,并能够最大限度地利用不同存储层消除复杂性和成本并释放价值。
结论
就像处于初期阶段的关系数据库一样,近年来Hadoop的应用因缺乏最佳实践而受到影响。企业在考虑将Hadoop用作数据湖时,需要参考尽可能多的最佳实践。利用区域和适当的授权作为数据工作流框架的一部分,为数据转换提供高度可扩展的并行系统。

时间:2018-10-04 10:56 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















