谷歌的Dataset Search开放至今,为什么还搜不到我的
本月早些时候,谷歌推出了数据集搜索专用引擎 Dataset Search,这是一个建立在元数据上的搜索引擎,可以对网络上数千个存储库中的数百万个数据集进行搜索。谷歌团队称其为「Google Scholar for data」。本文将介绍构建 Dataset Search 的一些技术细节,概述有助于开发开放数据生态系统的内容。此外,谷歌还解决了自 Dataset Search 启动以来反馈最多的问题——「为什么我的数据集没有出现在谷歌 Dataset Search 中?」
概述
谷歌 Dataset Search 高度依赖大大小小的数据集提供者,利用开放 schema.org/Dataset 标准在自己的站点上添加结构化的元数据。元数据指定了每个数据集的显著属性:名称和描述、空间和时间覆盖、出处信息等。Dataset Search 利用这一元信息,将其与谷歌上的其他可用资源连接,并为这个丰富的元数据语料库建立索引。建好索引之后就可以开始响应用户检索,并找出最符合检索的结果。
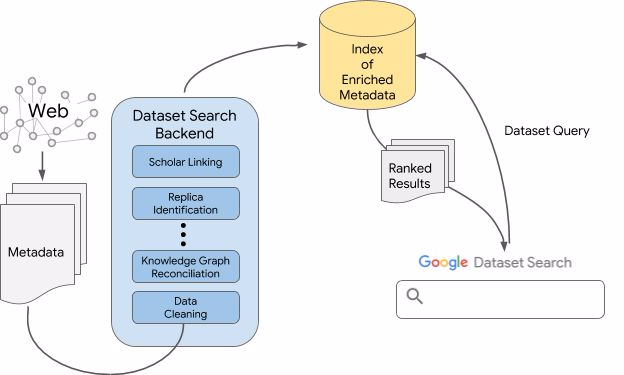
谷歌 Dataset Search 技术概览
利用来自数据集提供者的结构化元数据
当谷歌的搜索引擎处理带有 schema.org/Dataset 标记的网页时,它知道那里有数据集元数据,并处理那个结构化元数据以创建描述页面上每个标注数据集的「记录」。schema.org 的使用允许开发人员将这种结构化信息嵌入到 HTML 中,而不影响页面的外观,同时使信息的语义对所有搜索引擎可见。
然而,无论 schema.org 定义或指引有多么精确,一些元数据将不可避免地不完整、错误或完全缺失。此外,某些字段之间的区别可能很模糊:数据集存储库属于数据集的发布者还是提供者?如何区分引用描述数据集创建的科学论文和描述数据集使用的论文?事实上,许多这样的问题都会激发热烈的学术讨论。
尽管存在这些问题,Dataset Search 必须在前端提供统一、可预测的用户体验。因此,在某些情况下,我们用更通用的字段名(如「provided by」)来显示来自多个其他字段(如「publisher」、「creator」等)的值。在其他情况下,我们根本无法使用某些字段:如果数据集提供者在阐释某个特定字段时出现了各种各样的错误,谷歌就暂时绕过该字段,并与社区一起理清指引。每一项决策中都有一个特定的问题用于解决困难——「最有助于数据发现的因素是什么?」这种对正在处理的任务的关注使得一些问题比最初看起来容易。
连接重复数据集
对于流行的数据集,在多个资源库中重复出现是很常见的事情。谷歌使用了多种信号来确定两个数据集是否重复。例如,schema.org 可以通过(schema.org/sameAs)中指出的某种方法明确两个数据集之间的联系,即利用明确指示条目标识的参考网页的 URL(例如,条目的维基百科页面、维基数据条目或官方网站的 URL)。这是将不同重复数据集连接起来并指向规范数据集来源的最好方法。其它信号还包括两个数据集的描述指向相同的规范页面,具有相同 DOI,共享数据集下载链接,或者在其它元数据字段中有大量重叠。这些信号都不是完全独立的,因此谷歌将它们结合起来以得到数据集重复的最强可能标示。
用谷歌知识图谱进行协调
谷歌的知识图谱是一个很强大的平台,描述和连接了很多实体之间关系的信息,包括出现在数据集元数据中的信息:提供数据集的机构、数据集覆盖范围的位置 、赞助机构等等。因此,谷歌尝试用知识图谱中的条目来协调元数据字段中提到的信息。基于两个原因,谷歌能以很高的精度实现这种协调。首先,我们知道知识图谱中的条目类型和元数据字段中的大致期望实体类型。因此,我们可以限制知识图谱中用于匹配特定元数据字段值的实体类型。例如,一个数据集的提供者应该匹配知识图谱中的一个机构实体,而不是匹配覆盖范围的位置。其次,网页信息的语境可以帮助减少选择的数量,这对于分辨拥有相同缩略词的机构尤其有用。例如,缩略词 CAMRA 可以代表「Chilbolton Advanced Meteorological Radar」,或者「Campaign for Real Ale」。如果我们使用了网页上的条目,当在网页上出现诸如「云」、「蒸汽」和「水」等关键词时,我们可以更容易地确定 CAMRA 实际上是 Chilbolton Radar(Chilbolton 雷达)。
这种协调提供了许多提升用户搜索体验的可能性。例如,Dataset Search 可以通过用与页面其余部分相同的语言显示元数据的协调值来定位结果。此外,它可以使用同义词,校正拼写错误,扩展缩略词,或使用知识图谱中的其它关系进行查询扩展。
连接到其它谷歌资源
谷歌拥有很多其它可增强数据集元数据的数据资源,例如 Google Scholar。知道哪个数据集被参考和引用可以实现两个目的:
提供有关数据集重要性和显著性的有价值信息;
为数据集作者提供查看引用和获得荣誉的简便方式。
实际上,谷歌希望的是,强调使用数据的出版物可以带来更加健康的数据引用生态。目前,由于缺少描述人们如何引用数据的模型,从 Dataset Search 到 Google Scholar 的链接还是相当近似的。谷歌尝试使用 DOI 以外的信息以提供更好的覆盖范围预测,但引用一个数据集的文章数量因而变得很不准确。谷歌希望在这个问题上取得更多进展,以得到更高的预测精度。
搜索和结果的排序
当用户进行一次查询时,谷歌进行数据集语料库的搜索,其工作方式和 Google Search 搜索网页的方式没多大区别。对于任意一次搜索,我们需要确定一个文档是否和查询相关联,然后对相关文档进行排序。由于对用户如何搜索数据集并没有相应的大规模研究,作为首个近似方案,其利用了谷歌网页排序方法。然而,数据集排序和网页排序是不同的,因此谷歌添加了一些涉及元数据质量、引用等的额外信息。随着 Dataset Search 被用户更频繁地使用,谷歌将能更好地理解用户的数据集搜索行为,从而显著提升排序质量。
更好的开放数据生态
谷歌构建 Dataset Search 的目的是为数据发现带来积极的影响。该搜索引擎的标记决策依赖于开放的标准(schema.org、W3C DCAT、JSON-LD),因为 Dataset Search 仅能做到和其支持的开放数据生态一样好的程度。因此,谷歌的 Dataset Search 希望支持一个强大的开放数据生态,通过鼓励:
广泛支持描述发布数据的开放元数据格式;
进一步发展描述更多数据类型和更多细节的开放元数据格式;
发展类似引用研究文献的引用数据文化,为创建和发布数据的作者提供应有的荣誉;
发展利用该元数据的工具,以实现数据的更好发现和利用。
开放元数据标准的采用与数据集搜索的持续发展相结合,可促进更健康的开放数据生态系统。在这个生态系统中,数据是研究的「一等公民」。
那么你的数据集为什么搜不到呢?
现在大致理清了一个思路,即 Dataset Search 的质量与网页上元数据的质量息息相关。对于「为什么某些数据集没有出现在谷歌的搜索结果中」这一问题,最常见的答案是:该数据集没有任何标记。只要将该页面弹出到结构化数据测试工具中,就可以看到标记是否存在。如果没有看到任何标记,并且你有该页面的修改权限,那么你可以添加标记,如果没有页面的修改权限,你可以让有权限的人执行这一步骤,这将使他们的页面更容易被每个人发现。
谷歌希望 Dataset Search 对社区有所帮助,帮助用户有所发现从而节省时间,帮助科学研究人员节省数据检索时间,从而让他们有更多的时间去利用数据。
原文链接:https://ai.googleblog.com/2018/09/building-google-dataset-search-and.html

时间:2018-09-29 14:13 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















