你的食物变质没?用AI算法来检测一下吧
最近一条幼儿园采用过期食物的新闻引起了社会的强烈关注,对于食品安全而言,国家一直是严格要求的,尤其是对于婴幼儿食品安全的标准,部分已经超越了国际上的标准。但可能是由于无法严格地执行到每一个地方且检测周期较长,造成这一现象的出现,着实有些令人愤怒。程序员,用代码改变世界的一群人,今天向大家介绍用AI算法来检测食物是否过期,希望能够在以后普及应用到食物安全的初步检测之中,下面以披萨为例。

在俄罗斯最大的披萨连锁店“Dodo Pizza”的最新Dbrain用例中,首席数据科学家Arthur Kuzin解释了开发的AI算法如何通过短信控制披萨质量,将披萨面团打分1到10分。下面详细解释如何教AI算法来评估披萨质量!
本文重点关注以下内容:i)仅从少数标记样本中获取完整数据集的标记; ii)将方框拉伸到对象的分割掩模(将方框的方形掩模应用于任何形状)。
想法
Dodo pizza有许多活跃的客户,在完成订单后,他们同意分享他们对披萨质量的看法。为了简化反馈环节及其处理过程,Dbrain开发了一个AI算法驱动的应用程序来检查披萨质量。此应用程序类似于聊天机器人,客户上传照片后可以获得得分为1到10的等级评分。
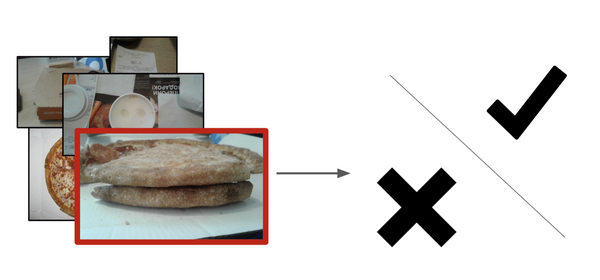
问题陈述
当程序员收到开发请求时,就着手开发一种可以客观地确定面团质量的算法。问题在于确定披萨烘焙过程是何时停止的,披萨外皮上的白色气泡与产品的变质相关。
数据挖掘
该数据集收集了披萨烘焙的照片,还包括了一些不相关的图像。如果配方不正确,披萨外皮上就会出现白色气泡。此外,专家还对面团质量进行了二元标记。因此,得到数据集之后,算法的开发就只是时间问题了。
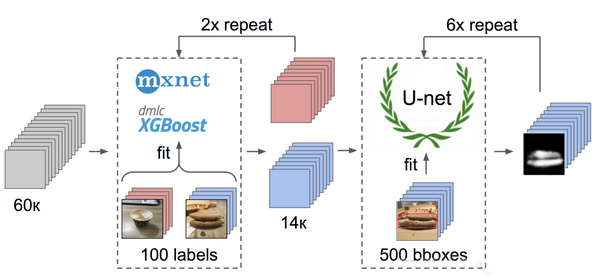
这些数据集的照片是在不同的手机上、在不同的光线条件下以及从不同的角度拍摄得到的。整个数据集有17k张的披萨标本图像,而整个数据集的图片总数为60k张。
由于该任务需求非常简单明了,因此用不同的方法来处理数据是一个很好的操练场。那么,以下就是我们解决任务所需要的:
1.选择能够看到披萨外壳的照片;
2.区分所选照片中的披萨外皮与背景区域;
3.在选定区域训练神经网络。
数据过滤
此外,我自己标记了一小部分照片,而不是向其他人解释我真正需要的东西,因为,如果你想要做得好,自己就需要对数据进行处理,以下就是我所做的:
1.标记了50张有披萨外皮图像,标记了50张没有披萨外皮图像:

2.使用resnet-152网络在imagenet11k上预训练权重等参数,在全连接层后提取特征;

3.将两个类别的特征的平均值作为基准点;
4.计算从该基准点与剩余的60k图片的所有特征之间的距离;
5.确定前300个与正类别相关的样本,后500个与负类别相关的样本;
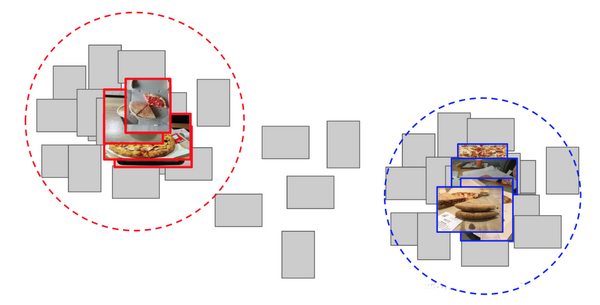
6.基于这些样本的特征训练LightGBM;
7.使用此模型在整个数据集上预测出标签;
这与我在kaggle比赛中用作基线的方法大致相同。
前传
大约一年前,我和Evgeny Nizhibitsky一起参加了“海狮” kaggle比赛。任务是从无人机拍摄的图像上统计海豹的个数。标记只是给出了尸体的坐标,但在某些时候, Vladimir Iglovikov用方框标记了它们,并在社区慷慨地进行了分享。
我决定通过分割来解决这个任务,在第一阶段只将海豹方框作为目标。经过几次训练迭代后,很容易找到一些硬样品,但是效果不好。

对于此示例,可以选择没有海豹的大区域,手动将蒙版设置为零,还可以添加到训练集。因此,Evgeny和我训练了一个模型,该模型已经学会了分割大型海豹鳍。

披萨外皮检测和提取
再次回到主题披萨,为了识别所选和过滤后的图像上的外壳,最佳选在标签上做文章。通常,一些贴标机工作对同一样本的工作方式是不同的,但当时我们已经对这种情况应用了一致性算法并将其用于方框中。这就是为什么我只是做了几个例子就把它交给了贴标机。最后,获得了500个样本,这些样本特别突出了披萨外皮区域。
为了识别所选过滤照片上的外壳,我为贴标机做了几个例子。
第一次迭代模型训练的结果仍然是错误的,预测的可信度定义如下:
1 ——(灰色区域的面积)/(掩膜的面积)
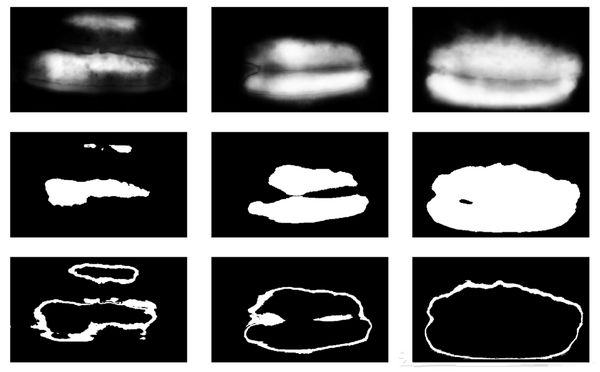
接下来,为了完成获得接近掩模方框的下一次迭代,在小的样本集上用TTA预测掩模。这在某种程度上可以被认为是WAAAAGH式的知识蒸馏,但更为正确地将其称之为伪标签。

然后,我人为地确定某个阈值,用于形成新训练集的置信度,还可以选择出标记出集成失败的最复杂样本。我认为这将是有用的,并在自己休息时标记了20张图片。
最终模型训练
最后——模型的训练。为了准备样品,我用掩膜提取了披萨外皮区域。此外,我通过扩大掩膜并将其应用于图片以去除背景来略微充气掩膜,因为它不包含有关面团质量的任何信息。然后我从Imagenet中调整了几个模型。我总共收集了大约14k张合适的样本,此外,没有训练整个神经网络,而只训练最后一组全连接层层以防止过拟合。
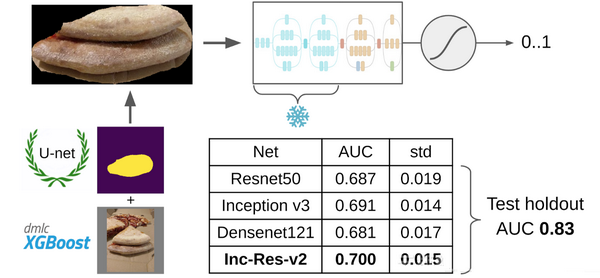
最终发现模型为Inception-Resnet-v2时效果最好,其ROC-AUC达到0.700。如果没有进行处理并在没有掩膜的原始图像上训练模型的话,那么得到的ROC-AUC将为0.58左右。
验证
在开发解决方案时,DODO披萨回传了下一批数据,并且使用这些数据测试了整个模型,结果ROC-AUC达到了0.83。
上述结果表明,我们仍然无法完全保证在没有错误的情况下管理披萨的质量。考虑到错误出现的原因,我再一次训练了模型并取得了积极的成果。我们现在看一下错误:

从上图可以看出,它们与披萨外皮标签的错误有关,因为有些标记为正常的披萨有明显的变质迹象。

这里的误差是由于第一个模型未能选择正确的样本,这导致难以确定正常披萨的关键特征。解决这个问题后,模型的性能会有所提升。
结论
我的同事有时会取笑我几乎所有的分割任务都是通过使用Unet完成,但我仍然希望他们会喜欢它,因为Unet网络是一种相当强大和方便的方法,它可以使得模型误差可视化,且表现优异,可以节省处理数据集的时间。此外,整个模型看起来非常简单,应用十分方便。
以上是整个算法流程及实验记录,现在是时候吃一块比萨饼放松一下了,干杯!
文章原标题《Your Pizza is Good: How to Teach AI to Evaluate Food Quality》,译者:海棠

时间:2018-09-26 13:42 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















