Hadoop中Hive原理及安装
Hive是什么(官网概念)
Apache Hive™数据仓库软件有助于使用SQL读取,写入和管理驻留在分布式存储中的大型数据集。可以将结构投影到已存储的数据上。提供命令行工具和JDBC驱动程序,用于将用户连接到Hive。
Hive是建立在Hadoop (HDFS/MR)上的用于管理和查询结果化/非结构化的数据仓库;
一种可以存储、查询和分析存储在Hadoop 中的大规模数据的机制;
Hive 定义了简单的类SQL 查询语言,称为HQL,它允许熟悉SQL 的用户查询数据;
允许用Java开发自定义的函数UDF来处理内置无法完成的复杂的分析工作;
Hive没有专门的数据格式(分隔符等可以自己灵活的设定);
适用场景
Hive不适用于在线事务处理。 它最适用于传统的数据仓库任务
Hive的执行延迟比较高,因为hive常用于数据分析的,对实时性要求不高;
Hive优势在于处理大数据,对于处理小数据没有优势,因为hive的执行延迟比较高。
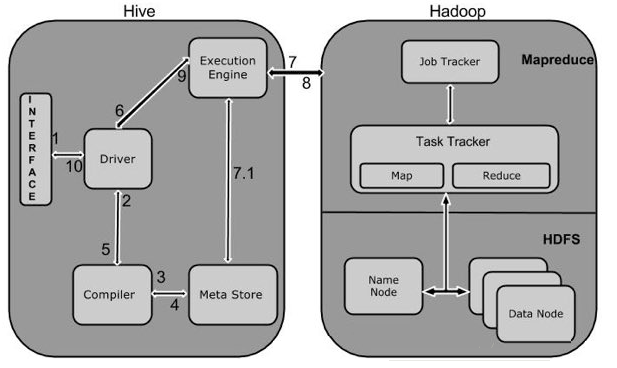
1 Execute Query
Hive接口,如命令行或Web UI发送查询驱动程序(任何数据库驱动程序,如JDBC,ODBC等)来执行。
2 Get Plan
在驱动程序帮助下查询编译器,分析查询检查语法和查询计划或查询的要求。
3 Get Metadata
编译器发送元数据请求到Metastore(任何数据库)。
4 Send Metadata
Metastore发送元数据,以编译器的响应。
5 Send Plan
编译器检查要求,并重新发送计划给驱动程序。到此为止,查询解析和编译完成。
6 Execute Plan
驱动程序发送的执行计划到执行引擎。
7 Execute Job
在内部,执行作业的过程是一个MapReduce工作。执行引擎发送作业给JobTracker,在名称节点并把它分配作业到TaskTracker,这是在数据节点。在这里,查询执行MapReduce工作。
7.1 Metadata Ops
与此同时,在执行时,执行引擎可以通过Metastore执行元数据操作。
8 Fetch Result
执行引擎接收来自数据节点的结果。
9 Send Results
执行引擎发送这些结果值给驱动程序。
10 Send Results
驱动程序将结果发送给Hive接口。
Hadoop中实际应用
通过上面流程解释,要想在hadoop中使用hive,至少需要安装hive和Metastore(任何数据库)本文安装mysql 。
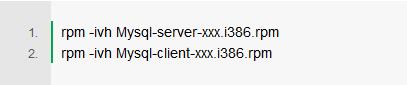
1 , 安装mysql
下载linux环境下的mysql安装包,需要两个,一个是server端的,一个是client端的。
查询linux机器上默认安装的mysql或者你以前安装的mysql, 暴力卸载之 。
执行安装命令
执行命令初始化设置mysql


使用客户端登陆

登陆成功后输入命令:(授予mysql远程用户连接的权限)
使用远程客户端连接(navicat 或Advanced Query Tools等等工具 )我用的navicat, 如图自行领悟。
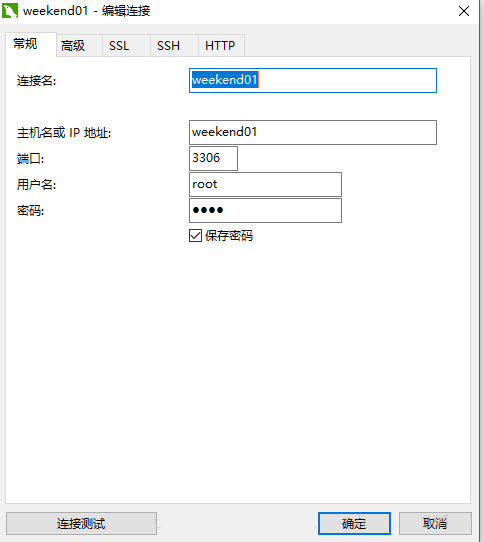
到这里hive就安装搭建完成了!

时间:2018-09-25 13:12 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















