先有鸡or先有蛋?浅谈数据拆分与特征缩放的顺序
环节中重要的两个环节,与特征缩放,关于他们两个的先后顺序问题,我将在下文进行阐述
前些天在 100-Days-Of-ML-Code 上回答了一个关于数据拆分与特征缩放的顺序先后的一个issue,感觉挺有争议性的,故单独拎出来做下笔记说明。我的观点是:机器学习工程中,应该先进行数据划分,再进行特征缩放。出于严谨性,本篇文章是从-方面进行数据拆分与特征缩放的顺序问题阐述,同时也欢迎大家一起讨论这个问题。
问题阐述
关于数据拆分与特征缩放的顺序先后问题,一般会在工程中遇到,具体表现为:
先数据拆分再特征缩放

先数据缩放再数据拆分

论点阐述
首先先来看下我们常用的两种 sklearn 上的特征缩放:StandardScaler()与MinMaxScaler()

从图中可以看出StandardScalar涉及到了均值μ与标准差σ,而MinMaxScaler则涉及到了最大值max与最小值min。这些参数的取值都得考虑到全局样本的,什么意思呢?我们来看下两者的输出结果:
先数据拆分再特征缩放
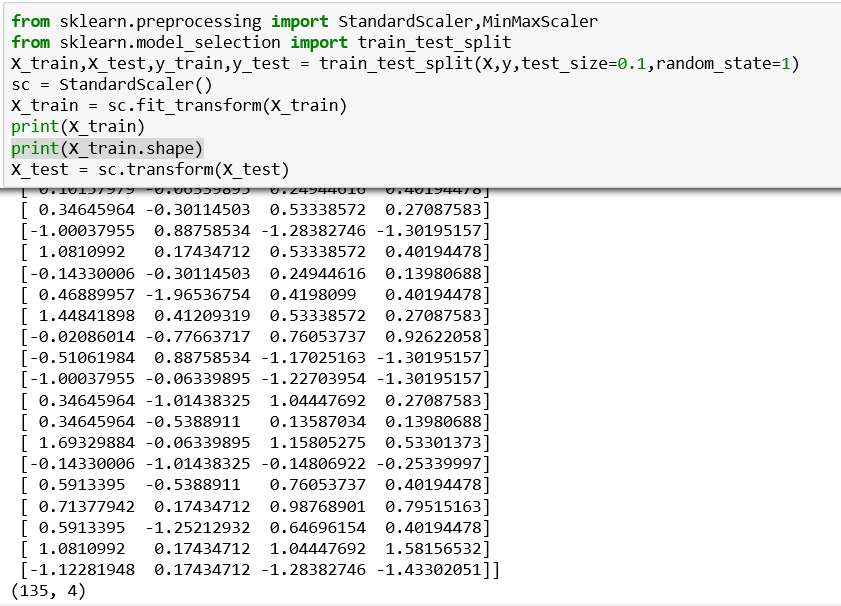
先数据缩放再数据拆分
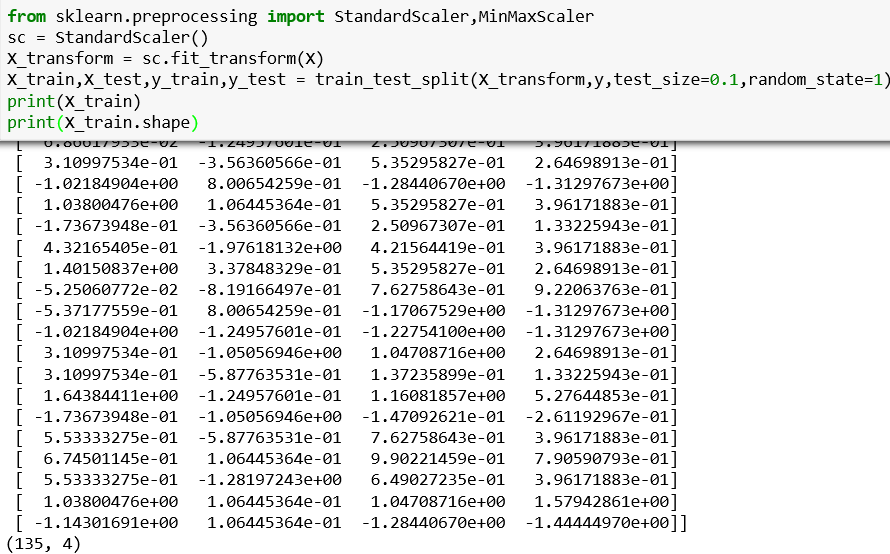
可以很明显看出,两种不同的操作顺序输出的数据是完全不同的,也就是说样本的分布是完全不同的(很重要!后面阐述要用到),那这种差异性在现实工程中会有什么影响?要解答这个问题,首先我们首先需要了解fit_transform()方法,fit_transform()你可以理解为fit()方法和transform()方法的pipeline,进行特征缩放时我们的顺序是
• 先fit获得相应的参数值(可以理解为获得特征缩放规则)
• 再用transform进行转换
fit_transform方法就是先执行fit()方法再执行transform()方法,所以每执行一次就会采用新的特征缩放规则,我们可以将训练集的特征缩放规则应用到测试集上,可以将测试集的特征缩放规则应用到训练集上(不过一般很少这么做),但是通过全部数据集(训练集+测试集)fit到的的特征缩放规则是没有模型训练意义的。
这里我们举一个例子:假设农业部要求我们用LR模型来对花类型进行分类,我们经过学习得到了一个LR模型,模型上线后,现在需要对新的花数据进行预测分类(此时我们可以把旧花数据看做训练集,新花数据看做测试集):
• 按照先数据拆分再特征缩放的做法是:先将旧花数据fit出特征缩放规则,接着将其transform到新花数据上,接着对应用旧花数据特征缩放规则的新花数据进行预测分类;
• 按照先数据缩放再数据拆分的做法是:将新旧花数据合并为一个总数据集,接着对总数据集进行fit_transform操作,最后再把新花数据切分出来进行预测分类;
重点!!!
这时候问题来了,“我们经过学习得到了一个LR模型”,请问我们学习的数据是什么?旧花数据 OR 新旧花合并数据?答案肯定是旧花数据啊,更为详细地讲,是应用旧花数据特征缩放规则的旧花数据,这时候第二种做法的问题就出来了,我们这个LR模型是根据应用旧花数据特征缩放规则的旧花数据的分布学习到的这条分类线
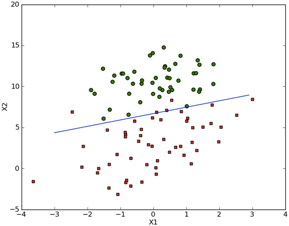
而此时你却将这条分类线去应用在应用新旧花数据特征缩放规则的新花数据上,根据上方我们得到的论点“两种不同的操作顺序输出的样本的分布是完全不同”,两种完全不同的分布,你用根据其中一种分布学习得到分类线对另一种分布来说是完全没有使用意义的,因为两者根本可以说是根据不同的数据学习而来的,所以有些时候第二种做法效果可能会很好也可能会很糟糕,这就像你拿牛数据学习的LR模型去预测花的分类一样。而机器学习的前身就是统计学,而统计学的一个样本基本原则就是样本同质性(homogenetic)。
总结

这里我贴的是sklearn的一段官方demo代码,可以看出sklearn的演示代码也是遵从先数据拆分再特征缩放的顺序进行的操作,先fit到X_train的特征缩放规则,再将其应用在X_test上,这也从一个小方面验证了我的观点吧(虽然我也不喜欢不严谨的举例论证方法)。所以综上所述,我的观点是在进行数据挖掘方面的工作时,面对特征缩放环节,应该先进行数据拆分再进行特征缩放。

时间:2018-08-31 13:29 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















