担心被“暴雷”?不如做好数据的“为用之道”
李丹枫说,在的世界里,自己最看重的是“工匠精神”。
一身深灰色T恤,谈笑间谦和而沉稳的李丹枫确实有一些“匠人”的特质。他严谨、专注,对自己过手的事精益求精。
李丹枫对自己的定位,是一个业务型的。区别于学术界追求算法优化而忽略实际应用的做法,他非常注重包括算法在内的数据科学技术,在用户手中的实用性和稳定性,并认为这是自己的“工匠精神”所在。
“提高效率,或降低成本,或增加利润”,这是李丹枫给数据产品定的标准,也是他的“匠人原则”。
利基市场里孕育的人工智能
博士毕业后的李丹枫,本来是打算去一家风口浪尖上的硅谷互联网公司工作的。
但是2003年初,美国刚刚经历了互联网泡沫破裂的余震,整个互联网行业式微。机缘巧合之下,李丹枫的第一份工作选择了美国个人消费信用评估公司FICO。虽然现在因为互联网金融的兴起FICO已经被人熟知,但在当时它的名气远远不如风口中的互联网公司,相比于其他同学,李丹枫的选择显得很另类。
“现在想想还挺有意思,那时很多人在泡沫破裂前去了互联网初创公司,泡沫破裂后,那些公司在一夜间就消失了。”当时在硅谷,头一年还拿着高薪,第二年就失业了的科学家大有人在。
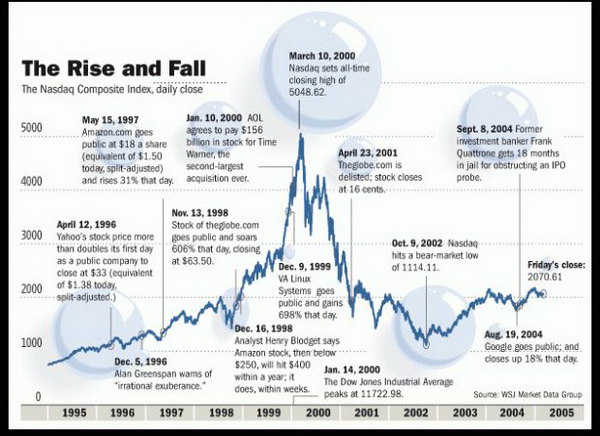
(图片说明:1995年开始的美国互联网泡沫,来源:Wall Street Journal)
李丹枫非常地幸运,他的第一份工作就与人工智能有关。
在二十年前,人工智能并没有现在这么火热。FICO是最早开始将人工智能技术大规模应用在业界生产实践中的公司。由于FICO的业务是在美国个人信用评级和信用卡反欺诈的利基市场(注:利基市场/niche market是指高度专门化的需求市场,是规模较小的细分市场),因此在当时并没有受到互联网泡沫破裂的太大影响。稳定的公司环境让李丹枫专心在信用卡反欺诈的利基市场中应用他在博士阶段学到的人工智能技术。
在李丹枫看来,人工智能当时有两个方向,一个是模拟人去做人可以做到的事,另一个是帮助人做不能做到的事。
人工智能模拟人的技术在当时非常初级。在当时很多大学和机构的实验室中,已经有非常多AI初级应用的模型,包括手写体识别、人脸识别、车牌号识别等等,这些现在热门的AI应用场景已经开始出现在实验室中。2000年,李丹枫在IBM Watson实习期间做的手写体识别技术,就是教机器如何识别手写数字,通过不断优化算法和模型来优化识别结果,但准确率只能达到95%左右,并没有达到应用到实践中的要求。现如今,利用谷歌的TensorFlow已经可以将手写识别的准确率提高到99%以上。
在FICO,李丹枫的工作就是利用人工智能“帮助人做不能做到的事儿”——信用卡反欺诈。全世界每天产生海量的交易,人做不到一笔一笔去检查是否有可能是欺诈,这时候,就需要机器对交易数据进行初筛,再将可疑的交易反馈给人工检查。
另外,观察到在建模过程中,很多环节都是依赖于人工,有不少优化的空间,李丹枫就建立了一套自动化建模的流程, 只需修改几个配置文件, 就可以实现自动建模,不仅将建模的时间大大缩短,而且减少了许多人为的错误。这个系统被公司使用了很长时间。
在FICO工作的经验,让李丹枫不仅较早地应用了人工智能技术,还培养了他的“匠人”思维——重视数据产品的实用性。在FICO做的模型需要满足多家银行的需求,在服务多个客户的过程中,李丹枫意识到数据质量和模型稳定性很重要,这决定了模型能否在实际应用时成功落地。
现在回过头看,很多泡沫期的硅谷互联网公司已经消失,而李丹枫在机缘巧合下的选择却为他在数据分析和人工智能领域铺就了坚实的基石。
拥抱国内的大数据浪潮
2014年,在美国数据分析和挖掘领域工作十多年后,李丹枫回到国内加入了【友盟+】,也加入了国内数据科学的发展大潮。
“2014年国内的创业氛围热火朝天,时刻有新鲜事物涌现,与国外的沉寂反差巨大。我希望回到国内以后,自己的技术长处能与业务有更多结合,驱动自己做更多正确的事。”谈到美国与中国在数据科学领域的区别,李丹枫认为国外的环境更像是一个“实验室”,国内则更像一个“试验田”。
他观察到,美国公司里有很多安心做研究的人,会去做长期性的底层工作,学校和公司里研究院的资源也比较丰富。现在流行的人工智能和大数据处理技术大部分都源自美国的实验室。另一方面,在美国这一较成熟的市场上,数据的使用受到了非常严格的管控,应用场景也大大受限。比如在信用评级过程中,用户的性别、年龄、种族、居住地等数据都被法律禁止使用,因为公众担心自己会因为这些因素而受到歧视,银行可能会根据这些数据评估用户的信用级别,进而针对不同群体制定不一样的利率。
中国虽然在基础研究领域不突出,但在应用层面优势明显。在国内这一新兴市场,庞大的用户群体产生了丰富的数据,带来了更加多样的应用场景,也有着自由度更高的数据使用环境。国内广阔的市场前景是最吸引李丹枫的地方。尽管在美国已经有家庭的羁绊,最终他还是决定回到国内,完成从技术人才到团队管理者的角色转变。
在国内,李丹枫的团队面对的是涵盖超过7亿真实网民的全域数据,其中包括了手机、电脑、媒体、实体店铺等线上线下产生的数据等等,是一个名副其实的“数据试验田”。他山之石,可以攻玉。李丹枫将自己丰富的金融业务经验,首先尝试应用在了互联网金融风控领域。
2016年,在中国互联网金融兴起的时候,其主要的用户群体大多没有人行征信数据,金融机构缺乏数据来鉴别欺诈行为,降低违约风险。李丹枫敏锐地意识到,在移动设备上的行为数据,或许可以用来破解风控难题。
在风控数据金字塔模型中,与风控相关性最强的是人行征信数据,但只有3.5亿的用户。底部的设备行为数据,虽然能够覆盖大部分网民,但是数据的应用难度也最大。李丹枫的团队结合多维数据和机器算法,形成金融风控模型,帮助金融企业提高风控决策模型的覆盖率和准确率。
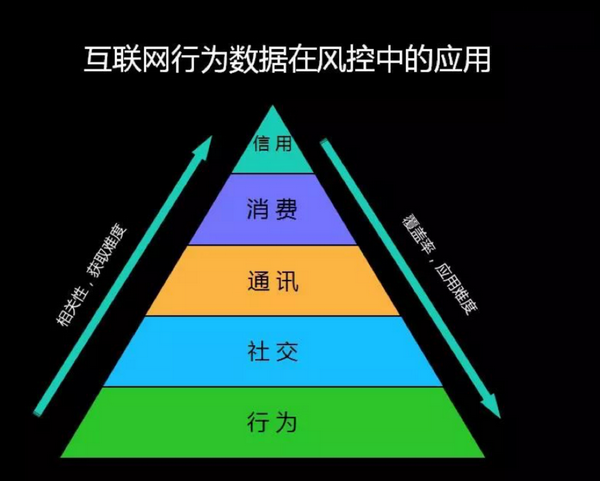
(图片说明:互联网金融风控数据金字塔模型 图片来源:【友盟+】)
其中比较典型的是多头借贷问题。基于手机上的行为数据,李丹枫团队可以判断哪些人是更有可能多头借贷的人。“比如这个人会安装多个借贷App,并且安装了自动抢红包、返利、博彩游戏之类的App”,李丹枫说道。除此之外,他们还会结合App使用的时间、时长、频次、兴趣偏好,以及手机的操作系统、品牌、价格、质量等上千个维度的数据来判断。李丹枫团队从这些相关性很弱的数据中提取信息,通过机器学习建模,用逻辑回归模型和树模型,通过时间序列的变量计算输出一个分值,从而判断借贷人的违约风险。
(图片说明:深度学习行为风控的三个场景 图片来源:【友盟+】)
庞大的数据背后是责任
十几年间,李丹枫见证了数据科学行业突飞猛进的发展。
随着数据量的不断增长和计算力的不断增强,模型的复杂度也在不断的提高。现在,李丹枫要面对的是服务 150 万款 App,710 万个网站,14 亿个设备的海量数据,数据存量高达55PB。如果拿一张 A4 纸,用正反两面把所有数据都写下来,纸垒起来可以装 15 万辆卡车。这些数据每天的运算量需要2 万个计算单元,相当于200个地球上的100亿人一天24小时不间断地运算。
“庞大的数据背后是责任。”
李丹枫认为,在实际生产环境中,如果不真正理解数据,往往会造成不可控的结果。现在随着建模能力越来越强,很多人在不理解数据的情况下直接把数据放到模型里去,他认为这是一种很不负责的行为。
在庞大的数据背后,需要数据科学家的“工匠精神”来支撑整个机制的运作。“数据科学家要对自己的模型和分析结果负责,要理解数据本身”,李丹枫说道。在多年的数据生涯中,他也总结了自己的一套应用方法论。
“用之为用之,不用为不用,是为用也”,他认为数据的应用需根据其特点找到合适的场景,“就像你无法用棉花造出飞机一样,每一种数据都有适用和不适用的场景。一定要清楚数据的来源和特性,找到数据本身和问题之间的相关性,使所用的数据能够解决本质的问题,这是一款数据产品取得成功的关键。”李丹枫要求自己时刻从现实的生产环境出发,思考如何让数据模型能够在复杂多变的现实环境中稳定地运转。
旧时的工匠对每一个零件、每一道工序都精心打磨,李丹枫对待数据产品同样如此。从源头数据质量的把控,到模型特征的加工,他将数据产品的稳定性贯彻到建模的每一步。不管现在的模型有多发达,他都会钻研透彻每一个业务的细节,为每一个产品量身定制最合适的模型。
李丹枫的责任感还体现在对数据安全和用户隐私的重视上。
大数据服务所带来的便利正悄然改变着人们的生活,但数据泄露和隐私的问题却时刻在威胁着每一个人和每一家公司。2017年3月,某公司试用期员工与网络黑客勾结,盗取涉及交通、物流、医疗等个人信息50亿条,在网络黑市贩卖。据统计,截至2017年2月,中国有15046个MangoDB数据库暴露在公网,数据安全问题日益凸显。
大数据应用场景下,无所不在的数据收集使得人们难以控制其个人信息的去处。利用大数据的超强分析能力对多源数据进行共享,能将原本经过匿名化处理的数据再次还原,用户的隐私时刻面临着威胁。
为了保护用户隐私,李丹枫在建模的每一步都十分注意安全问题。他以互联网金融风控模型为例,在实际的建模过程中,他们往往会使用到多达150万个维度的行为数据,但是并不会对外透露数据细节,而是输出标准化的风险指数,在保护用户隐私的前提下去评估用户的信用情况。
因果关系才是理解世界的方式
虽然人工智能在今天被炒得火热,但李丹枫认为现阶段它还是“弱”人工智能。
为此,他和团队提出了一个 “数据智能”(Data Intelligence)的概念。他觉得现在的人工智能是依赖大量的数据来训练一个参数众多的“黑箱模型”,从而找到数据之间的相关关系。这些模型是建立在输入数据和输出数据的“相关关系”上的,而不是建立在“因果关系”上。与其说是“人工”智能,不如说是“数据”智能。在李丹枫看来,因果关系才能帮助我们理解世界。我们知道了植物是怎样生长的,才有了万亩良田;知道了电和磁的相互转化,才有了万家灯火。
人类只有能够解释世界,才能理解世界,从而进一步改变世界。比如爱因斯坦著名的质能方程E=mc²,简单的三个参数解释了质量和能量之间的关系,人类在此基础上进一步用核裂变技术造出了原子弹,也使用上了核电。

(图片说明:原子弹爆炸 来源:中国科学院近代物理研究所)
因此,李丹枫认为未来大数据领域最有待突破的是模型的可解释性。真正的智能,在于能够帮助我们找到因果关系的模型,未来的强人工智能或许可以帮助人类去从大数据中归纳总结出简单的因果关系,去发现世界的运行规律。
不过,对于强人工智能时代的到来,他认为还需要经过很长一段时间。“现在人工智能在互联网、金融、医疗、物流、教育等领域都有很好的开端,当下大数据主要的发展方向是在更多的领域找到落地场景”, 李丹枫说道。
人工智能的第三次热潮能持续多久?未来的强人工智能可以帮助人类认识到更多世界的运行规律吗?我们或许还没有确切的答案,但在人工智能浪潮中,像李丹枫这样怀揣着工匠精神的数据科学家在各个领域脚踏实地地打磨好每个产品,将人工智能深深扎根在人们生活的方方面面,未来的美好图景或许就在不远的将来。
作者:李丹枫,友盟+CDO首席数据官
来源:DT数据

时间:2018-08-27 23:58 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















