在大规模数据集上应用潜在语义分析的三种方式
原标题 3 Ways to Apply Latent Semantic Analysis on Large-Corpus Text on macOS Terminal, JupyterLab, and Colab,作者为 Dr. GP Pulipaka。
在上利用自然语言处理产生描述发现场景,潜在语义分析会发挥作用。这有很多种不同的方法能在多个层次上执行潜在语义分析,比如文本层次,短语层次和句子层次。最重要的是,语义分析能被概括进词汇语义学和连词成段或成句的研究中。
词汇语义学能对词汇项进行分类和分解,利用词汇语义结构有不同内容的特点来区分词的异同。段或句中的一类术语是上位词,下位词提供了下位词实例间关系的含义。下位词在相似结构中有相似语法或相似拼写,但却有不同含义。下位词间无相互关系。
「book」是一个简单的下位词,对于有些人而言,是阅读,或是有着相同拼写,形式或语法的预订行为,但含义却大相径庭。一词多义是另一种词法现象,它是指单个词能和多个相关联的理解或是截然不同的意思相联系,一词多义是希腊词汇,表示有很多种符号。
提供了 NLTK 库,通过将大段文字切成短语或有意义的字符串来实现抽象化文字。处理文字是通过抽象化的方式得到符号,词形还原是将文字从当前屈折的形式转变为基本形式。
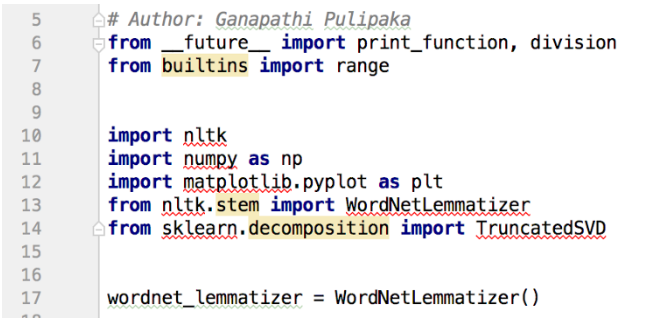
图一:词形还原的代码片段
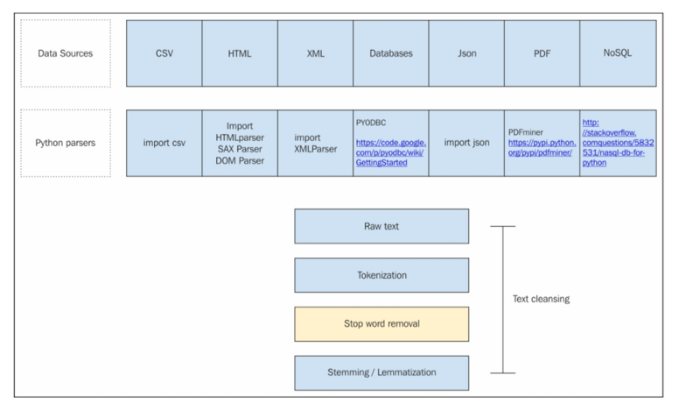
图二:用 Python 对不同数据资源进行自然语言处理
潜在语义分析
在大规模数据集的文本文档上应用潜在语义分析,是将数学和统计计算方法用在大型文本语料库中。大多数情况下,潜在语义分析的效果赶超人类水平,而受制于人类主导的重要测试。潜在语义分析的精确度很高,是因为它在网络规模上通读了机器易读文档和文本。潜在语义分析是项应用在奇异值分解和主成分分析的技术(PCA)。文档能被表达成矩阵 A=Z×Y, 矩阵的行代表集合里的文档。矩阵 A 代表典型大规模语料库文本文档里大量成百上千的行列。应用奇异值分解提出了一系列成为矩阵分解的操作。Python 自然语言处理的 NLTK 包应用一些低秩逼近词频矩阵,而后,低秩逼近有助于索引和恢复文档,这些文档因聚类大量文字得到潜在语义索引而得名。
线性代数简述
矩阵 A=Z×Y 包含实数值,使用非负值作为词频矩阵。确定矩阵的秩伴随着矩阵中大量线性独立的行或列。矩阵 A≤{Z,Y} 的秩。平方式 c×c 代表了对角矩阵,也即非对角线上的值均为零。在测试矩阵时,如果所有的 c 对角矩阵为 1,那么,矩阵就是被 lc 表示 c 的维度的单位矩阵。对于 Z×Z 的平方矩阵,A 有不包含全部零的向量 k。矩阵分解适用于利用特征向量分解成矩阵乘积的方阵。这样可以降低词汇的维度,从高维到可视化呈现在图上的二维。利用主成分分析(PCA)和奇异值分解(SVD)的降维技术在自然语言处理上保持了较强的相关性。文档单词频率的 Zipfian 属性使得确定处于静态阶段词汇的相似度很难。所以,特征值分解是奇异值分解的一个副产品,因为文档的输入是高度不对称的。潜在语义分析是一种特殊技术,它在语义空间上对文档进行解析,并用 NLKT 库确定多义词。像类似 punkt 和 wordnet 的资源就必须从 NLTK 库中下载。
使用 Google Colab notebooks 进行大规模深度学习
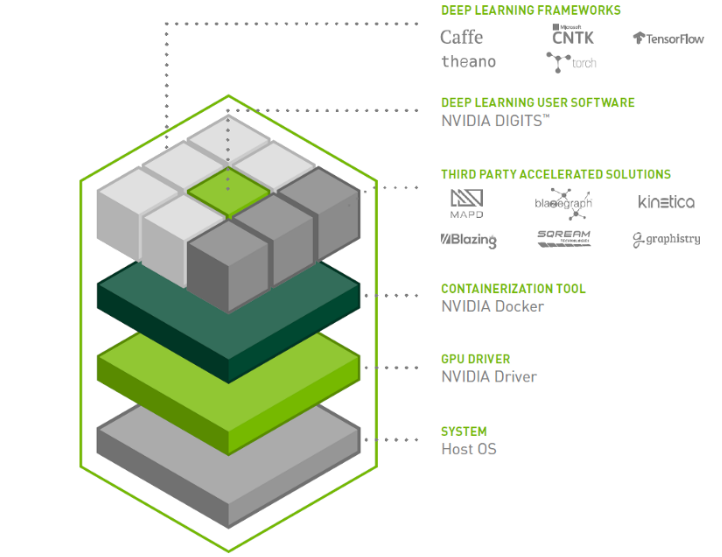
图 3 采用多个 NVIDIA GPU 的深度学习堆栈
在 CPU 上训练机器学习或者深度学习模型可能需要数个小时之久,并且就编程效率而言,这样的代价对计算机资源的时间和能源来说可谓是相当昂贵的。出于研究和开发的目的,Google 建造了 Colab Notebook 环境。它完全在云上运行,无需为每台设备设置额外的硬件或者软件。它完全等同于 Jupyter notebook,它可以帮助数据科学家们通过存储在 Google Drive 云端硬盘上来分享 Colab notebooks,这就像是在协作环境下的一些 Google 表格或文档。Colab notebook 在程序运行中启用 GPU 以加速程序的运行时,没有其他的消耗。不像 Jupyter notebook 那样可以直接从机器的本地目录访问数据,将数据上传到 Colab 会有一些挑战。在 Colab 中,从本地文件系统中上传文件时会有多种文件来源选项,或者也可以安装一个驱动,如通过 Google 的 drive FUSE wrapper 去加载数据。

图 4 安装 Google 的 driver FUSE wrapper
完成完成此步骤后,它会显示如下日志并没有报错:
图 5 macOS 上的安装显示的安装日志
下一步是生成身份验证令牌,用以验证 Google Drive 云端硬盘和 Colab 的 Google 凭据。
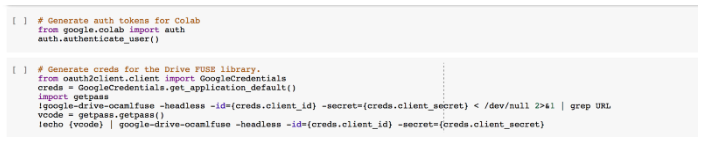
图 6 验证凭据
如果显示成功获取访问令牌,则 Colab 会准备就绪。

图 7 验证访问令牌
在此阶段,当访问文本文件的内容时,如果驱动尚未安装, 那么它将显示 False。

图 8 验证对 Google Drive 云端硬盘中已上传的 Colab notebook 文件的访问
驱动安装后,Colab 可以访问 Google Drive 云端硬盘中的数据集。

图 9 在此键入标题
一旦文件可访问,Python 就可以像是在 Jupyter 环境中执行一样执行。Colab notebook 显示的结果也类似于我们在 Jupyter notebook 中所看到的那样。
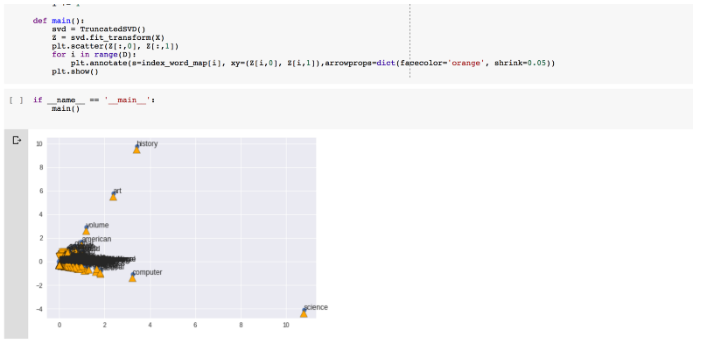
图 10 程序运行的结果
PyCharm IDE
该程序可在 PyCharm IDE 环境中编译,并在 PyCharm 上运行,也可以在 OSX 终端中执行。
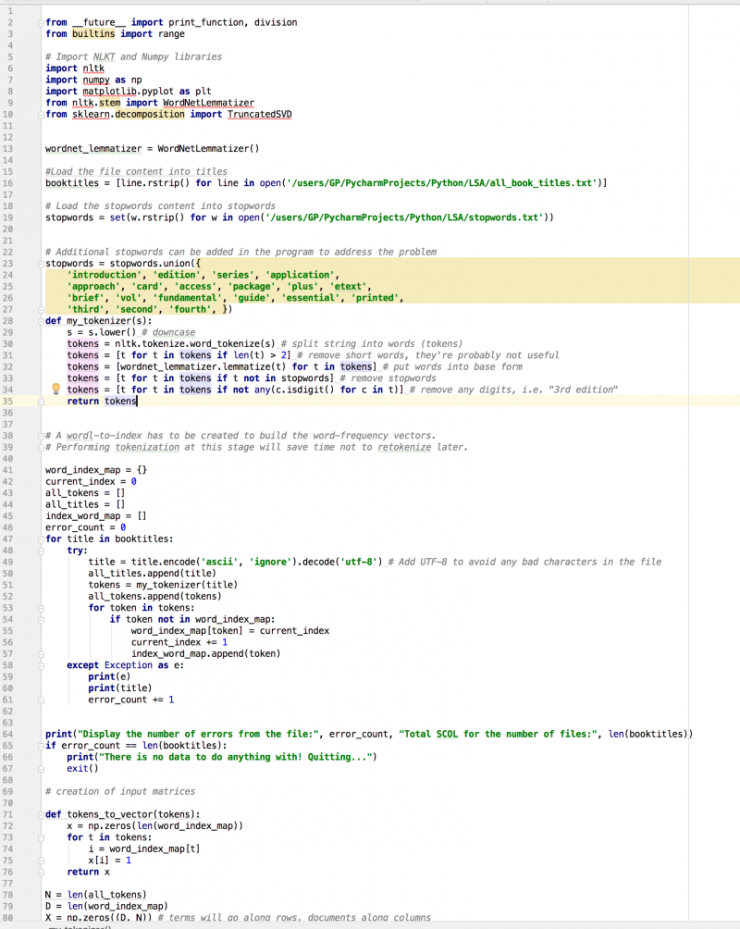
图 11 PyCharm IDE 中 Python 自然语言处理中的 LSA 分析
在 OSX 终端中运行的结果
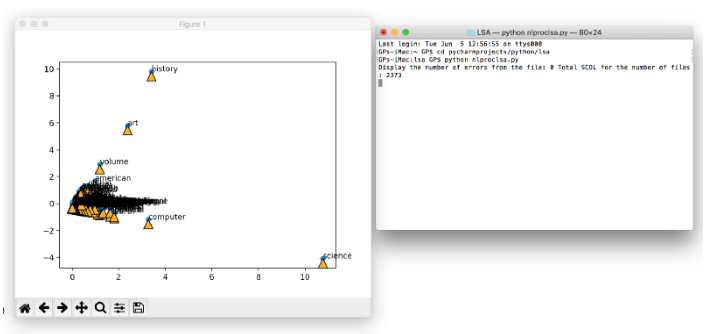
图 12 在 OSX 终端中运行的结果
独立运行的计算机中的 Jupyter Notebook
在本地机器上运行潜在语义分析的 Jupyter Notebook 给出了一个相似的输出:
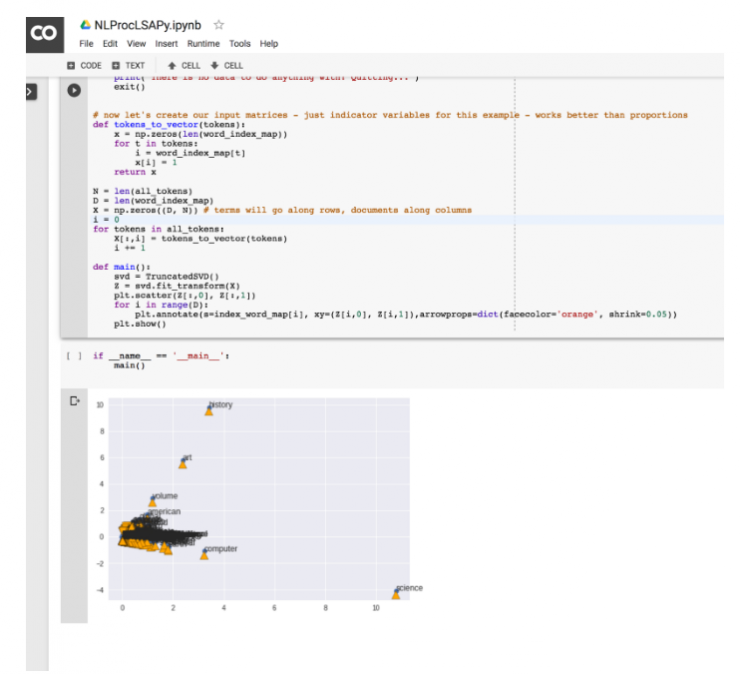
图 13 在 Jupyter notebook 上运行潜在语义分析
图 14 结果
参考文献
Gorrell, G. (2006). Generalized Hebbian Algorithm for Incremental Singular Value Decomposition in Natural Language Processing. Retrieved from https://www.aclweb.org/anthology/E06-1013
Hardeniya, N. (2016). Natural Language Processing: Python and NLTK . Birmingham, England: Packt Publishing.
Landauer, T. K., Foltz, P. W., Laham, D., & University of Colorado at Boulder (1998). An Introduction to Latent Semantic Analysis. Retrieved from http://lsa.colorado.edu/papers/dp1.LSAintro.pdf
Stackoverflow (2018). Mounting Google Drive on Google Colab. Retrieved from https://stackoverflow.com/questions/50168315/mounting-google-drive-on-google-colab
Stanford University (2009). Matrix decompositions and latent semantic indexing. Retrieved from https://nlp.stanford.edu/IR-book/html/htmledition/matrix-decompositions-and-latent-semantic-indexing-1.html
原文链接:https://medium.com/datadriveninvestor/3-ways-to-apply-latent-semantic-analysis-on-large-corpus-text-on-macos-terminal-jupyterlab-colab-7b4dc3e1622

时间:2018-08-23 23:38 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















