深度学习文本分类在支付宝投诉文本模型上的应
随着的快速发展,以及在图像、语音领域取得的不错成果,基于的自然语言处理技术也日益受到人们的关注。计算机是怎么理解人类的语言的呢?
传统的应用,常常是利用上述人工总结的文本特征,但往往会遇到一些问题。比如“猫”和“咪”这两词语的语义很接近(即近义词),但计算机并不能真正的在词语语义层面理解,只是把他们当作了两个不同的词语。再比如“小狗”和“小猫”是很相关的两个词语,也不能被很好的理解和刻画。
本文主要介绍了中的文本分类任务,以及一些应用于文本分类的深度学习模型。文本分类是自然语言处理领域最经典的场景之一,试图推断出给定的文本(句子、文档等)的标签或标签集合。通过这些技术,计算机能够更好地理解人类的语言。
针对支付宝投诉欺诈场景,蚂蚁金服人工智能团队设计了多个文本深度学习模型。包括双向GRU,Capsule Network和Attention-based Model等等,均在支付宝投诉欺诈场景上取得了不错的效果。大家一起来看看吧!

背景介绍
对于风控业务,用户的投诉是理解黑产运作方式和监控风控变化的重要形式。风险决策中心每天会得到大量用户投诉文本信息,每个投诉文本通常对应一定的风险形式。目前分类模型只解决了部分对于文本信息利用率的问题。目前支付宝投诉欺诈场景主要应用到的深度学习模型有TextCNN和双向GRU。
相关工作分析
本文的主要目的是想介绍一下深度学习中的文本分类任务,以及一些应用于文本分类的深度学习模型。文本分类是自然语言处理领域最经典的场景之一,试图推断出给定的文本(句子、文档等)的标签或标签集合。
文本分类中包含了大量的技术实现,从是否使用了深度学习技术作为标准来衡量,可以将这些技术实现分为两大类:基于传统机器学习的文本分类和基于深度学习的文本分类。
文本分类的应用非常广泛,其中比较有常见的应用有垃圾邮件分类,情感分析,新闻主题分类,自动问答系统中的问句分类以及一些现有的数据竞赛等。现有的数据竞赛包括知乎的看山杯机器学习挑战赛,BDCI2017的比赛“让AI当法官”和Kaggle的比赛“Toxic Comment Classification Challenge”等。
文本分类中主要有三种分类类型,包括二分类问题,多分类问题以及多标签问题。比如垃圾邮件分类中判断邮件是否为垃圾邮件,属于一个二分类问题。在情感分析中,判断文本情感是积极还是消极,或者判断文本情感属于非常消极,消极,中立,积极,非常积极中的一类,既可以是二分类问题也可以是多分类问题。在BDCI 2017的比赛“让AI当法官”中,基于案件事实描述文本的罚金等级分类和法条分类,分别属于多分类问题和多标签分类问题。
文本分类的评价指标会根据不同的分类类型有各自不同的评价指标。二分类问题中常常用到Accuracy,Precision,Recall和F1-score等指标;多分类问题往往会使用到Micro-Averaged-F1,Macro-Averaged-F1等指标;多标签分类问题中则还会考虑到Jaccard相似系数等。
在基于传统机器学习的文本分类中,一般采用TF-IDF和Word Counts提取不同word n-gram的文本特征,然后将提取到的文本特征输入到Logistics回归、Naive Bayes等分类器中进行训练。但是当统计样本数量比较大的时候,就会出现数据稀疏和维度爆炸等问题。这时候就需要做一些特征降维处理,比如停用词过滤,低频n-gram过滤,LDA降维等。
随着深度学习的快速发展,以及在图像、语音领域取得的不错成果,基于深度学习的自然语言处理技术也日益受到人们的关注。传统机器学习的应用,是利用上述人工总结的文本特征,但往往会遇到一些问题。比如“猫”和“咪”这两词语的语义很接近(即近义词),但计算机并不能真正的在词语语义层面理解,只是把他们当作了两个不同的词语。再比如“小狗”和“小猫”是很相关的两个词语,也不能被很好的理解和刻画。
为了解决上述问题,让计算机一定程度上能够理解词语的语义,词向量技术应用而生。Mikolov et al. 2013 [1] 提出了word2vec模型,可以通过词语上下文的结构信息,将单词的语义映射到一个固定的向量空间中。如果需要判定两个词语的语义相似度(或相关度),只需要计算两个词向量的夹角余弦或欧式距离等即可。比如,“小狗”与“小猫”的相似度值就会很高。凭借词向量算法,计算机有了一定的词语语义上的理解能力。
在此基础上,我们希望可以更好的刻画整个句子的语义信息。Yoon Kim, 2014 [2] 提出将CNN模型首次应用到文本分类问题上。这里,词向量作为网络的第一层的输入,而CNN的核心点在于可以捕捉局部相关性,在文本分类任务中可以利用CNN来提取句子中类似word n-gram的关键信息。
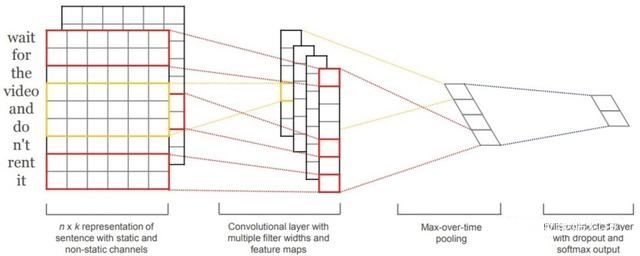
TextCNN模型架构如下图所示,句子中每个word使用K维向量来表示,于是句子可表示为一个N*K的矩阵,作为CNN的输入。使用不同的Filter Window进行卷积操作得到Feature Map,之后对Feature Map使用Max-over-time Pooling的池化操作,即将Feature Map向量中最大的值提取出来,组成一个一维向量。经过全连接层输出,使用Softmax层进行分类,并且加上Dropout层防止过拟合。
自然语言处理中更常用的是递归神经网络(RNN, Recurrent NeuralNetwork),能够更好的表达上下文信息。Liu et al., 2016 [3] 介绍了RNN用于分类问题的设计。用于文本分类的RNN网络结构如下图所示,网络中将最后一个单元的结果作为文本特征,连接全连接Softmax层进行分类。
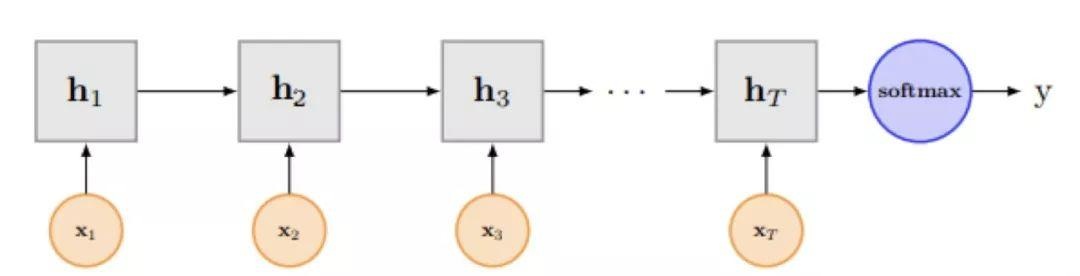
除此之外,还有使用双向RNN网络 [4](Bidirectional RNNs,BiRNNs)的两个方向的输出向量的连接或均值作为文本特征。
一般的循环神经网络往往存在许多弊端。在训练网络过程中,经过许多阶段传播后会出现梯度消散(Gradient vanishing)或梯度爆炸(Gradient exploding)等问题。循环神经网络在反向传播中得到误差的时候,可以想象一下多次乘以自身的参数权重,该乘积消散或爆炸取决于的幅值。针对于梯度爆炸的情况,常常会使用截断梯度方法。但是梯度截断并不能有效地处理梯度消散问题,有一个容易想到的方法是使用正则化或约束参数,当然还有更好的解决方案,那就是使用LSTM(Long Short-Term Memory)或GRU(Gated recurrent unit)等门控RNN(Gated RNN)。
梯度消散是原生RNN中一个很大的问题,也就是后面时间的节点对于前面时间的节点感知力下降,也就是忘事儿。Hochreiter et al., 1997[5] 提出了LSTM,它的设计初衷就是来解决梯度消散问题。在标准的RNN中,这个重复的模块只有一个非常简单的结构,例如一个tanh层。LSTM同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。如下图所示,一个LSTM块有四个输入。
(1)输入(Input):模块的输入;
(2)输入门(Input Gate):控制输入;
(3)遗忘门(Forget Gate):控制是否更新记忆单元(Memory Cell);
(4)输出门(Output Gate):控制输出。
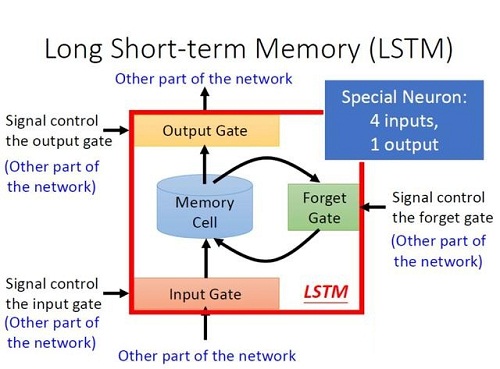
在多个LSTM连接的循环网络中,单个的LSTM的各个门的控制方式如下:

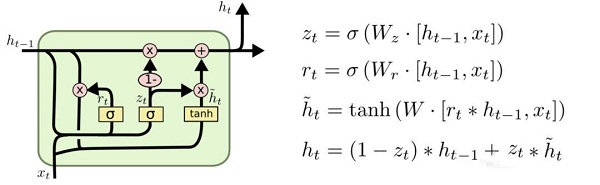
Cho et al., 2014 [6] 提出了GRU网络结构,GRU作为LSTM的一种变体,将遗忘门和输入门合成了一个单一的更新门。同样还混合了细胞状态和隐藏状态,加诸其他一些改动。最终的模型比标准的LSTM模型要简单,是目前非常流行的变体。
具体在文本分类任务中,BiRNNs(实际使用的是双向GRUs)从某种意义上可以理解为可以捕获变长且双向的“word n-gram”信息。
问题与挑战
word2vec算法虽然可以学到有用的词向量,但是该算法只刻画了词语的上下文结构信息,并不能很好的利用中文词语内部的结构信息,而中文又是一种强表义的语言文字。尤其是在大安全领域的数据里,有很多词语的变种写法。比如“小姐”和“小女且”这两个词语,经常会有不法分子为了绕开拦截系统,故意采用“形变”写成后者;再比如“微信”和“威芯”这两个词语,则是“音变”的刻意回避。因此,我们希望尝试一种新的算法,可以很好的刻画出中文词语的“形”和“音”的特性,生成更高质量的词向量,进而为后面的深度神经网络提供更大的信息量。
TextCNN能够在很多任务里面能有不错的表现,CNN卷积特征检测器提取来自局部的序列窗口的模式,并使用max-pooling来选择最明显的特征。然后,CNN分层地提取不同层次的特征模式。然而,CNN在对空间信息进行建模时,需要对特征检测器进行复制,降低了模型的效率。但在实际中文的语料库中,文本结构丰富,单词的位置信息、语义信息、语法结构等,对于CNN这种空间不敏感的方法不可避免会出现问题。
BiGRUs在文本分类上有明显的效果,但是在可解释性以及关注文本整体重要性上有明显的不足,特别是在分析badcase的时候感受尤其深刻。
如何解决TextCNN在文本中深入理解文字的位置信息、语义信息、语法结构等信息,以及使BiGRUs文本模型能够关注文本整体重要性将是下面要探索的内容。
CW2VEC
Cao et al. 2018 [7] 在AAAI 2018的论文里提出了cw2vec算法。(相关阅读请参考《AAAI 2018 论文 | 蚂蚁金服公开最新基于笔画的中文词向量算法》)该算法通过构造“n元笔画”提取出汉字的表义单元,比如“森林”与“木材”这两个词语具有很多共同的“4元笔画”-“木”,因此这两个词语具有较高的相关度。相对于汉字、偏旁粒度的词语拆解,n元笔画是一种非人工总结、由算法自动统计出来的表义结构。在中文的公开测试集中,cw2vec相对于word2vec, GloVe, CWE等算法均取得了一致性的提升。

cw2vec算法同时利用了中文词语内部和上下文的结构信息,来设计损失函数,因此产生更高质量的中文词向量。
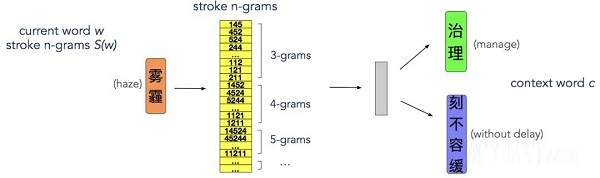
除了“形”之外,“音”的刻画可以通过“n元拼音”来实现。这里拼音字符从“a”到“z”,按照同样的方法获得词语的拼音,然后通过滑窗进一步得到“n元拼音”。
为了同时获得“形”和“音”的特征信息,我们采用了一种简单有效的实验方案,即分别基于“n元笔画”和“n元拼音”模式学习词向量,然后再对词向量进行拼接。相对于词向量平均(可以看作是线性加权),这种拼接方法,对后续的深度神经网络保有了更高的非线性信息融合能力。
目前cw2vec算法在内容安全宝、保险等场景中取得了不错的效果,这里我们也将探索其在支付宝投诉欺诈场景的作用。
Capsule Network
Hinton et al., 2017 [8] 在去年发表的论文中,Hinton介绍Capsule是一组神经元,其输入输出向量表示特定实体类型的实例化参数(即特定物体、概念实体等出现的概率与某些属性)。我们使用输入输出向量的长度表征实体存在的概率,向量的方向表示实例化参数(即实体的某些图形属性)。同一层级的Capsule通过变换矩阵对更高级别的Capsule的实例化参数进行预测。当多个预测一致时(本论文使用动态路由使预测一致),更高级别的Capsule将变得活跃。
到目前为止,将胶囊网络应用到自然语言处理上的论文研究较少,其中Zhao et al., 2018 [9] 提出了将胶囊网络应用到文本分类任务上。对于传统的分类问题上,胶囊网络取得了较好的性能,并且其性能超过了TextCNN,其模型结构图如下所示。
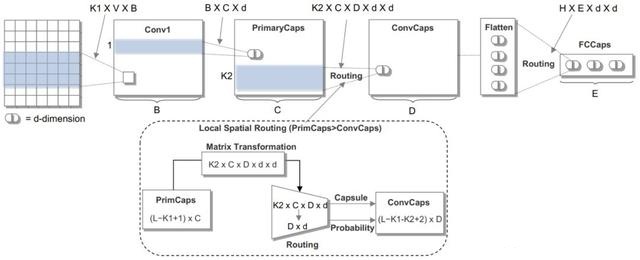
我们当前使用的网络结构是隐藏大小为128的BiGRUs(双向GRUs),连接胶囊网络层,胶囊数量设置为10,路由数量设置为3。
Attention机制
在谈及基于Attention机制的模型时,不能不先提及一下Encoder-Decoder框架,Encoder-Decoder框架可以理解成由一个句子生成另一个句子的通用处理模型。其架构如下图所示:
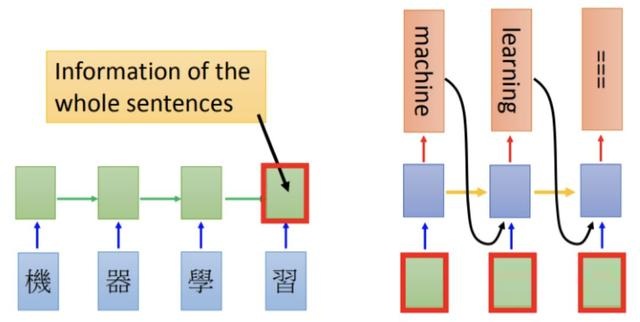
如图中的例子可以看到通过Encoder编码了“机器学习”四个繁体字,得到一个中间语义,即图中标了红框框的绿色方块。然后将这个红框框的绿色方块作为Decoder的输入。这里得做一下解释,Encoder-Decoder是一个通用的计算框架,其中的Encoder和Decoder可以是不同的模型组合,比如CNN、RNN等,上图展示的就是Encoder和Decoder都是RNN的组合。
仔细看上图的翻译框架可以看到,在生成目标单词的时候,无论哪个单词都是用到同一个红框框的绿色方块,即同一个中间语义。这就是展现出一种注意力不集中的分心模型。那注意力模型是如何的呢?
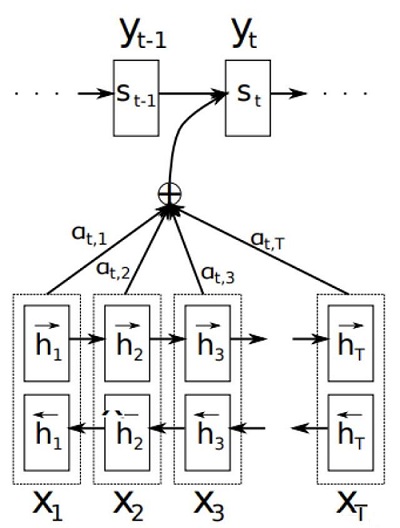
Bahdanau et al., 2014 [10] 提出了将Attention机制应用到在机器翻译。注意力模型会在输出目标单词的时候关注到输入单词的,比如输出“machine”的时候,注意力模型应该将目光注意到“机器”两个词上,即“机器”的关注重要性应该大一些,而“学习”两个词的重要性应该小一些。基于Attention机制的模型架构如下图所示。
Yang et al., 2016 [11] 提出了用词向量来表示句子向量,再由句子向量表示文档向量,并且在词层次和句子层次分别引入Attention的层次化Attention模型(Hierarchical Attention Networks,HAN)。HAN的模型结构如下图所示。
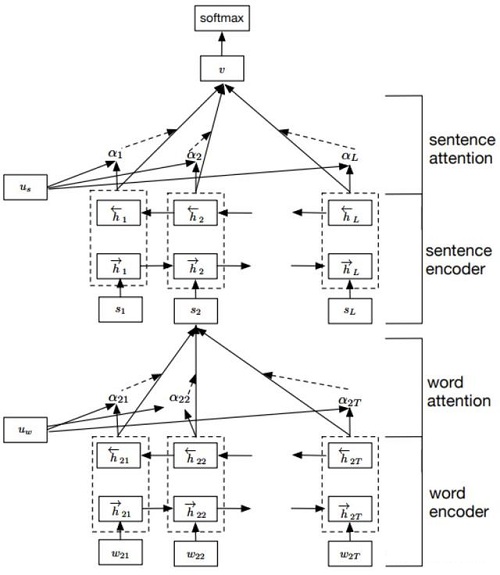
我们当前使用的网络结构是隐藏大小为128的BiGRUs(双向GRUs),连接word-level的Attention层。
实验结果
实验中读取了支付宝投诉欺诈场景的一段数据作为训练集,另一段时间的数据作为测试集。数据的标签是三分类,有违禁类,非案件类和欺诈类。其中欺诈的分类结果是我们主要关注的结果。数据集经过一些去重数据,去除文本中的标点,填充空值等预处理操作后,将处理后的数据输入我们的神经网络模型中,得到如下结果。
实验中我们主要对比Capsule Network和TextCNN模型以及BiGRU模型和Attention模型在不同词向量作为初始网络Embedding层在不同评价指标下的效果对比。其中为了验证两种词向量拼接后的高维词向量对网络结构的效果,添加了一组词向量拼接后对不同网络结构的实验对比。
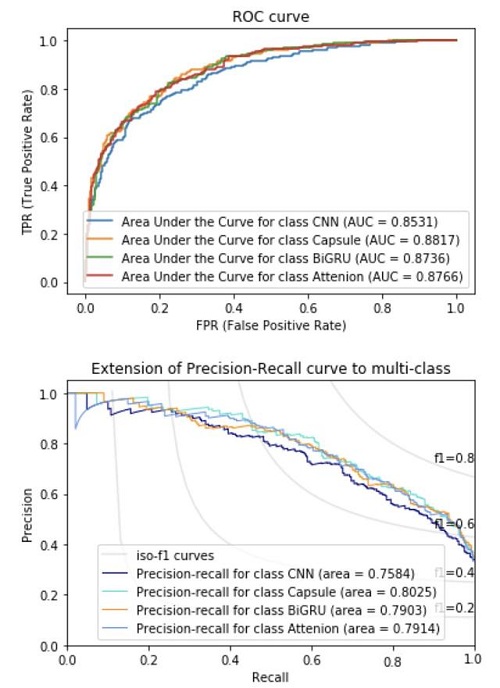
上图是使用word2vec作为词向量,多个网络模型在支付宝投诉文本上的一组实验示例。第一张图是该组模型的ROC曲线,第二张图是该组模型的Precision/Recall曲线。
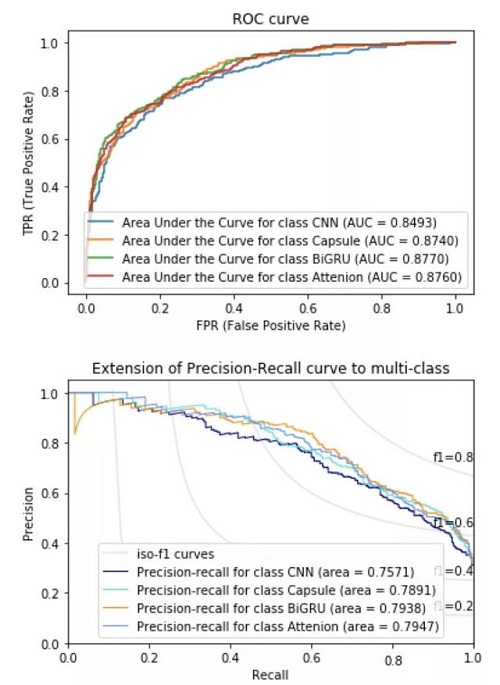
上图是使用cw2vec作为词向量,多个网络模型在支付宝投诉文本上的一组实验示例。第一张图是该组模型的ROC曲线,第二张图是该组模型的Precision/Recall曲线。
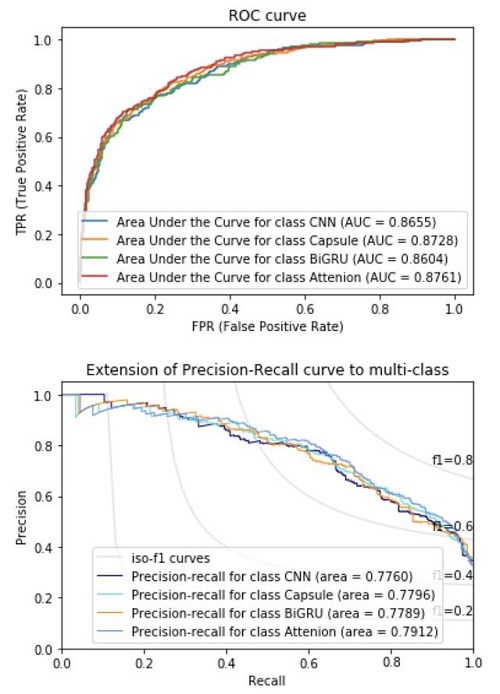
上图是使用拼接后的高维向量作为词向量,多个网络模型在支付宝投诉文本上的一组实验示例。第一张图是该组模型的ROC曲线,第二张图是该组模型的Precision/Recall曲线。
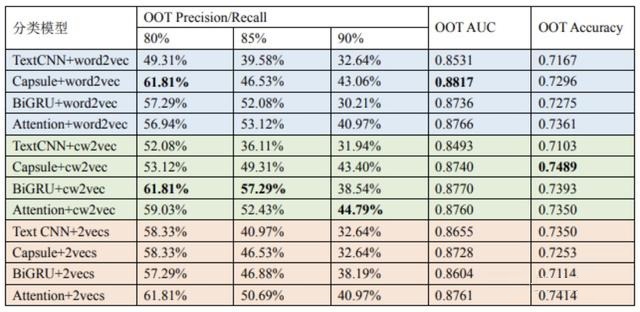
备注:其中2vecs是指将300维cw2vec词向量和300维word2vec词向量拼接在一起,形成一个600维词向量。AUC的计算方式是根据三分类共同的预测结果和真实标签计算得出的。三分类准确度(Accuracy)的计算方式是根据三分类结果的最大值来确定类别的,而Precision/Recall是仅根据三分类中的欺诈类的结果计算出来的。
实验中词向量算法分别用到了word2vec和cw2vec,其中word2vec中包含了cbow和skip-gram各150维的词向量,cw2vec中包含了基于笔画和拼音各150维的词向量。其中拼接后的高维词向量(2vecs)是同时包含cw2vec和word2vec的600维词向量。
上述实验表明,不管在使用word2vec,cw2vec以及拼接后的高维词向量作为词向量,我们用Capsule Network网络结构训练的模型在Precision/Recall值和AUC值上都比原先TextCNN的效果好。比较两者的三分类准确度,仅在使用拼接后的词向量的准确度上Capsule Network略低于TextCNN。因此,实验证明Capsule Network的整体表现优于原先的TextCNN。
在比较BiGRU模型和Attention模型时,我们可以发现在较低Precision下的Recall值时,BiGRU模型的分值略高于Attention模型。但在较高Precision下的Recall时,Attention模型的分值则明显高于BiGRU模型。如表中Attention+word2vec在80%Precision下Recall值略低于BiGRU+word2vec。但在85% 和90%Precision下,Attention+word2vec的Recall值则明显高于BiGRU+word2vec。在比较两者的AUC值和Accuracy值,在使用word2vec词向量和拼接的高维词向量时,Attention模型的分数较高。
在词向量间的对比中,可以看到仅使用cw2vec作为词向量网络模型整体上比word2vec和拼接的词向量效果更好。
讨论与展望
Capsule网络结构在文本分类中能够深入理解文字的位置信息、语义信息、语法结构等信息,而Attention机制能够让RNN网络更加关注于整理文本的重要性。
希望Capsule网络结构和Attention机制可以在更多的场景发挥效果,非常欢迎随时联系我们交流讨论!
感谢各位技术同学的热心帮助,以及蚂蚁金服机器学习平台-PAI平台的技术支持,实验中的cw2vec和word2vec两种词向量的生成是在PAI平台上实现的,为实验对比提供了很大的帮助,在数据中PAI的统计组件来进行建模的前的EDA。使用Pai-Tensorflow的GPU资源及分布式Tensorflow的支持,极快地加速了整个实验流程。也希望大家能够享受机器学习的乐趣!
参考文献
[1] Mikolov et al. Distributedrepresentations of words and phrases and their compositionality[C]. NIPS. 2013.
[2] Kim Y. Convolutional neuralnetworks for sentence classification[J]. arXiv preprint arXiv:1408.5882, 2014.
[3] Liu P, Qiu X, Huang X.Recurrent neural network for text classification with multi-task learning[J].arXiv preprint arXiv:1605.05101, 2016.
[4] Schuster M, Paliwal K K.Bidirectional recurrent neural networks[J]. IEEE Transactions on SignalProcessing, 1997, 45(11): 2673-2681.
[5] Hochreiter S, Schmidhuber J.Long short-term memory[J]. Neural computation, 1997, 9(8): 1735-1780.
[6] Cho K, Van Merriënboer B,Gulcehre C, et al. Learning phrase representations using RNN encoder-decoderfor statistical machine translation[J]. arXiv preprint arXiv:1406.1078, 2014.
[7] Cao et al. cw2vec: LearningChinese Word Embeddings with Stroke n-gram Information. AAAI 2018.
[8] Sabour S, Frosst N, Hinton G E.Dynamic routing between capsules[C]//Advances in Neural Information ProcessingSystems. 2017: 3856-3866.
[9] Zhao W, Ye J, Yang M, et al.Investigating Capsule Networks with Dynamic Routing for Text Classification[J].arXiv preprint arXiv:1804.00538, 2018.
[10] Bahdanau D, Cho K, Bengio Y.Neural machine translation by jointly learning to align and translate[J]. arXivpreprint arXiv:1409.0473, 2014.
[11] Yang Z, Yang D, Dyer C, et al.Hierarchical attention networks for document classification[C]//Proceedings ofthe 2016 Conference of the North American Chapter of the Association forComputational Linguistics: Human Language Technologies. 2016: 1480-1489.
来源:云栖社区

时间:2018-08-18 22:22 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















