Flink 在饿了么的应用与实战
本文分享来自于易伟平 他目前在饿了么主要负责大数据平台的架构和维护,对大数据实时计算引擎Storm、Spark、Flink有一定的了解,对离线SQL on Hadoop引擎有一定的研究。
本文主要内容如下:
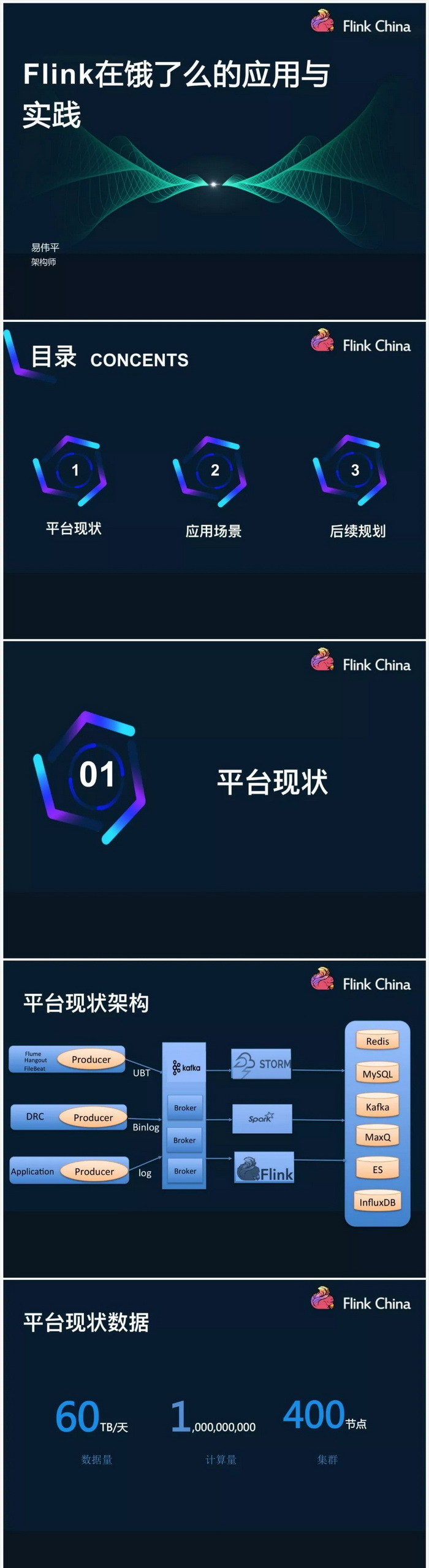
介绍了饿了么的平台架构实现,数据源有应用的日志、DRC、Flume/Hangout等,以Kafka作为消息中间件,计算平台Storm、Spark和Flink都有用,Storm占据2/3,Spark占据1/3,Flink目前用的比较少,存储backend涉及到redis、mysql、kafka等
目前的数据现状是每天60TB的量,集群规模为400个节点
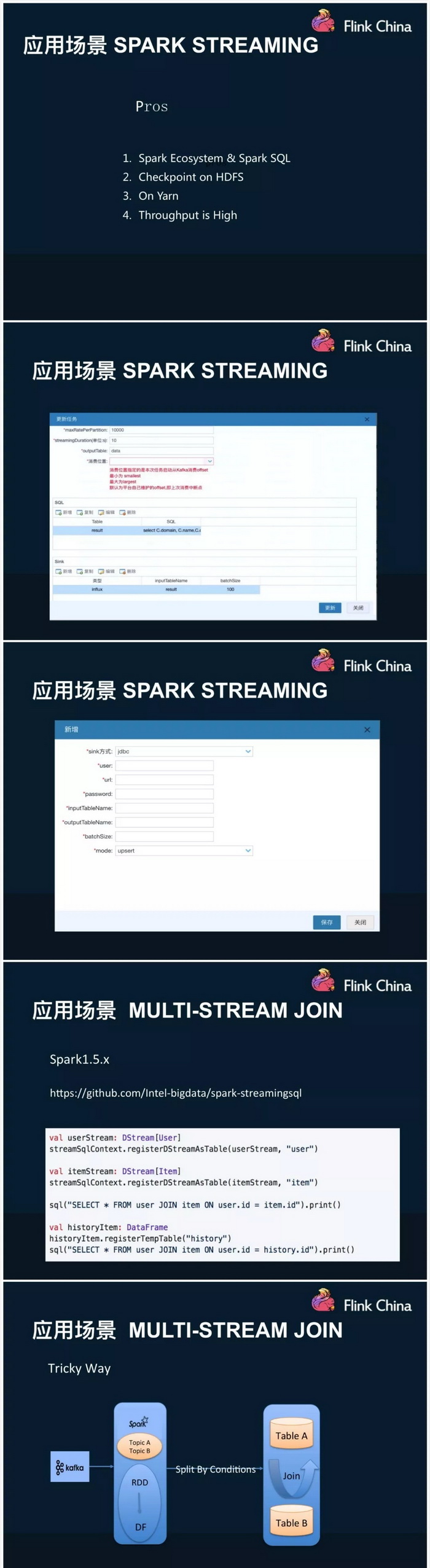
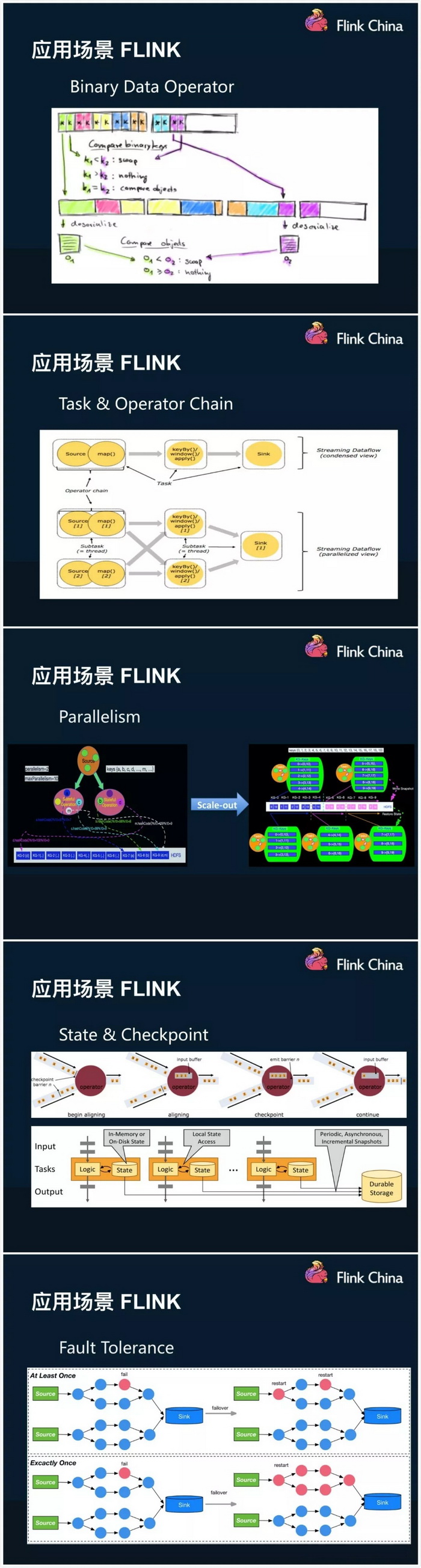
介绍了三个计算平台各自的优缺点,以及内部应用场景;单独介绍了一致性语义问题,认为目前exactly-once=at-least-once+幂等操作(emmm,我发现分享了很多基础知识)
因为饿了么现在是阿里系了嘛,所以,未来Flink的参与度要提高




来源: Hadoop技术博文

时间:2018-08-14 13:12 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:
最新文章

热门文章














