TOP 3大开源Python数据分析工具!

本文选取的示例数据是最近几天从某网站获取的实际生产日志数据,从技术层面来看,这些数据并不能算作是大数据,因为它的大小只有大约2Mb,但就演示来说已经足够了。
如果你想获取这些示例数据,可以使用git从作者的公共GitHub存储库中下载:admintome / access-log-data
数据是一个简单的CSV文件,因此每行代表一个单独的日志,字段用逗号分隔:

以下是日志行架构:
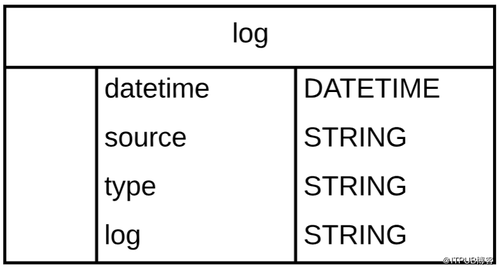
由于对数据可执行的操作的复杂性不确定,因此本文重点选取加载数据和获取数据样本两个操作来讲解三个工具。
1、Python Pandas
我们讨论的第一个工具是Python Pandas。正如它的网站所述,Pandas是一个开源的Python数据分析库。它最初由AQR Capital Management于2008年4月开发,并于2009年底开源,目前由专注于Python数据包开发的PyData开发团队继续开发和维护,属于PyData项目的一部分。Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。
首先,启动IPython并对示例数据进行一些操作。(因为pandas是python的第三方库所以使用前需要安装一下,直接使用pip install pandas 就会自动安装pandas以及相关组件)

大约一秒后,我们会收到如下回复:

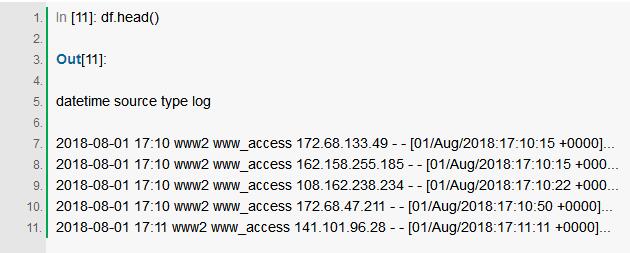
如上所见,我们有大约7000行数据,它从中找到了四个与上述模式匹配的列。
Pandas自动创建了一个表示CSV文件的DataFrame对象,Pandas中的DataFrame数据既可以存储在SQL数据库中,也可以直接存储在CSV文件中。接下来我们使用head()函数导入数据样本。
使用Python Pandas可以做很多事情, 数据科学家通常将Python Pandas与IPython一起使用,以交互方式分析大量数据集,并从该数据中获取有意义的商业智能。
2、PySpark
我们讨论的第二个工具是PySpark,该工具来自Apache Spark项目的大数据分析库。
PySpark提供了许多用于在Python中分析大数据的功能,它自带shell,用户可以从命令行运行。
这会加载pyspark shell:
当你启动shell时,你会得到一个Web GUI查看你的工作状态,只需浏览到http:// localhost:4040即可获得PySpark Web GUI。
让我们使用PySpark Shell加载示例数据:

PySpark提供了已创建的DataFrame示例:
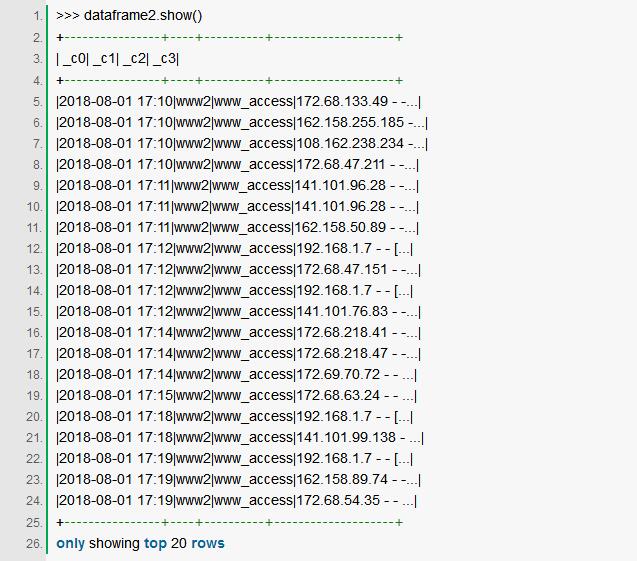
我们再次看到DataFrame中有四列与我们的模式匹配,DataFrame此处可以被视为数据库表或Excel电子表格。
3、Python SciKit-Learn
任何关于大数据的讨论都会引发关于机器学习的讨论,幸运的是,Python开发人员有很多选择来使用机器学习算法。
在没有详细介绍机器学习的情况下,我们需要获得一些执行机器学习的数据,我在本文中提供的示例数据不能正常工作,因为它不是数字类型的数据。我们需要操纵数据并将其呈现为数字格式,这超出了本文的范围,例如,我们可以按时间映射日志以获得具有两列的DataFrame:一分钟内的日志数和当前时间:

通过这种形式的数据,我们可以执行机器学习算法来预测未来可能获得的访客数量,SciKit-Learn附带了一些样本数据集,我们可以加载一些示例数据,来看一下具体如何运作。

这将加载两个用于机器学习分类的算法,用于对数据进行分类。
结论
在大数据领域,Python、R以及Scala是主要的参与者,开源社区中有不少针对这三者的工具,国内互联网企业一向很喜欢基于开源工具自研,选择之前不妨做好功课,抽取使用人数较多且应用场景最接近实际需求的方案。

时间:2018-08-14 13:13 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















