数据科学中模型可解释性差?你考虑了各种不确

当深度神经网络(DNN)变得越来越强大的时候,它们的复杂性也在一并与日俱增,而这种复杂性也给研究员带来了一系列新的挑战,其中就包括模型的可解释性。
可解释性对于构建更加强大且具有抵抗对抗性攻击能力的模型而言至关重要。此外,当我们需要为一个全新的、还未得到深入研究的领域设计模型时,如果我们能够解释模型的运行机制,这将有助于我们更好地去设计和分析模型。
在过去几年里,因为意识到了模型可解释性的重要作用,研究员们已经研究出了好几种方法,并且在去年的 NIPS 会议中也有一个专门的研究展示会(workshop) 负责讨论相关主题。提供模型可解释性的方法包括:
-
LIME:这是一种通过局部线性逼近(Local linear approximation)来解释模型预测的方法。
-
激活值最大化(Activation Maximization):该方法可用于理解哪些输入模式(Input patterns)会产生最大的模型响应(Model response)。
-
特征可视化。
-
将一个深度神经网络层嵌入低维度可解释空间。
-
借用认知心理学的方法进行解释。
- 不确定性评估方法——这正是本篇文章的重点。
不过在开始深入探究如何使用不确定性来调试和解释模型之前,让我们先来理解为什么不确定性如此重要。
为何我们需要关注不确定性?
一个显著的例子就是高风险应用。假设你正在设计一个模型,用以辅助医生决定患者的最佳治疗方案。在这种情况下,我们不仅要关注模型预测结果的准确性,还要关注模型对预测结果的确定性程度。如果结果的不确定性过高,那么医生应该进行慎重考虑。
自动驾驶汽车是另外一个有趣的例子。当模型不确定道路上是否有行人时,我们可以使用此信息来减慢车速或者是触发警报,以便于驾驶员进行处理。
不确定性也可以帮助我们解决因为数据样本(Data examples)而导致的问题。如果模型没有学习过与目标样本相似的数据,那么它对目标样本的预测结果最好是「对不起,我不清楚」。这样就可以避免诸如谷歌照片之前将非洲裔美国人误认为大猩猩这样的尴尬错误。这种错误有时是因为训练集不够多样化而导致的。
不确定性的最后一种应用方式是,它可以作为从业者调试模型的工具,而这也是本文的重点。我们稍后会深入探讨这个问题,但是在这之前,让我们先来了解一下不同类型的不确定性。
不确定性的类型
当前存在有不同类型的不确定性和建模方式,并且每种都有不同的用途。
模型不确定性,也就是认知不确定性(Epistemic uncertainty):假设你只有一个数据点,并且你还想知道哪种线性模型最能解释你的数据。但实际情况是,这时你是无法确定哪条线是正确的——我们需要更多的数据!
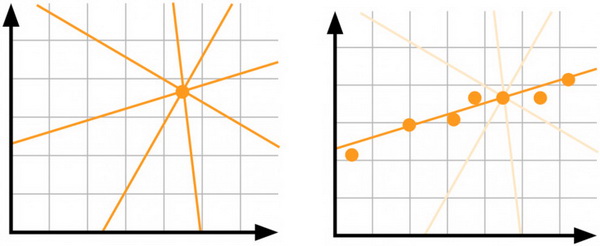
左边:数据不足导致了高度不确定性。右边:数据越多不确定性越小。
认知不确定性解释了模型参数的不确定性。我们并不确定哪种模型权重能够最好地描述数据,但是拥有更多的数据却能降低这种不确定性。这种不确定性在高风险应用和处理小型稀疏数据时非常重要。

举个例子,假设你想要建立一个能够判断输入图像中的动物是否有可能会吃掉你的模型。然后你的模型只在包含了狮子和长颈鹿的数据集上进行训练,而现在给出一张僵尸的图片作为输入。由于该模型没有学习过僵尸的图片,因此预测结果的不确定性会很高。这种不确定性属于模型的结果,然后如果你在数据集中给出了更多的僵尸图片,那么模型的不确定性将会降低。
数据不确定性或者称为随机不确定性(Aleatoric uncertainty),指的是观测中固有的噪音。有时事件本身就是随机的,所以在这种情况下,获取更多的数据对我们并没有帮助,因为噪声属于数据固有的。
为了理解这一点,让我们回到判别食肉动物的模型中。我们的模型可以判断出一张图像中存在狮子,因此会预测出你可能被吃掉。但是,如果狮子现在并不饿呢?这种不确定性就来自于数据。另一个例子则是,有两条看起来一样的蛇,但是其中一条有毒,另一条则没有毒。
随机不确定性可以分为两类:
同方差不确定性(Homoscedastic uncertainty):这时所有输入具有相同的不确定性。
异方差不确定性(Heteroscedastic uncertainty):这种不确定性取决于具体的输入数据。例如,对于预测图像中深度信息的模型,毫无特征的平面墙(Featureless wall)将比拥有强消失线(Vanishing lines)的图像具有更高的不确定性。
测量不确定性(Measurement uncertainty):另一个不确定性的来源是测量本身。当测量存在噪声时,不确定性将增加。在上述判别食肉动物的模型中,如果某些图像是通过质量较差的摄像机拍摄的话,那么就有可能会损害模型的置信度。或者在拍摄一只愤怒河马的过程中,由于我们是边跑边拍的,结果导致了成像模糊。
标签噪声(Noisy labels):在监督学习中我们使用标签来训练模型。而如果标签本身带有噪声,那么不确定性也会增加。
不过当前也存在许多方法可以实现对各种类型的不确定性进行建模。这些方法将在本系列的后续文章中进行介绍。现在,假设有一个黑盒模型暴露了自己对预测结果的不确定性,那我们该如果借助这点来调试模型呢?
让我们以 Taboola 中的一个模型为例,该模型可用于预测用户点击某个推荐内容的可能性。
使用不确定性调试模型
该模型具有许多由嵌入向量表示的分类特征,然而它却难以学习稀有值的通用嵌入向量(Generalized embedding)。解决此问题的常用方法是,使用特殊的 Out of Vocabulary(OOV) 嵌入向量。
想想一篇文章的广告客户,如果所有稀有的广告客户都共享同一个 OOV 嵌入向量,那么从模型的角度来看,它们基本上就是同一个广告客户。此 OOV 广告客户有许多不同的商品,每个商品都有不同的点击通过率(CTR)。如果我们仅使用广告客户作为点击通过率的预测因子,那么 OOV 将产生很高的不确定性。
为了验证模型输出 OOV 的高度不确定性,我们采用了验证集并将所有广告客户嵌入向量转换为 OOV。接下来,我们检查了向量转换前后模型的不确定性。正如预期那样,由于向量的转换,模型的不确定性增加了。如果给予信息丰富的广告客户嵌入向量,该模型的不确定性将降低。
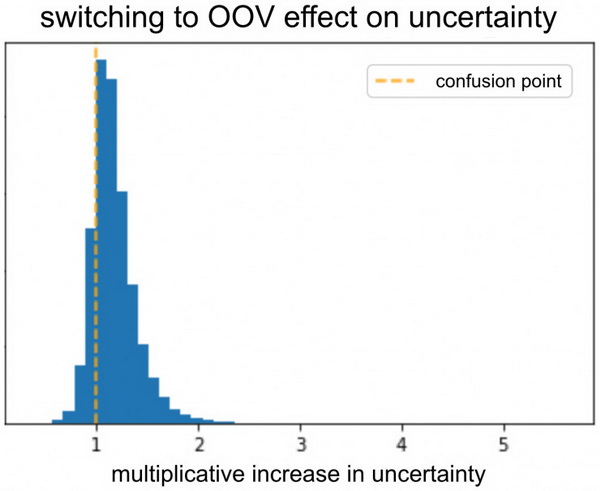
我们可以针对不同的特征重复这一点,然后找出那些在采用 OOV 嵌入向量替换时导致较低不确定性的特征。这些特征都是不提供信息的,或者是因为我们将它们提供给模型的方式不对。
我们甚至可以采用更精细的粒度:某些广告客户在不同商品的点击通过率之间存在着较高的可变性,而其他广告客户的点击通过率则大致相同。我们希望该模型对第一类广告客户具有更高的不确定性。因此,一种有用的分析策略是,关注广告客户中不确定性和点击通过率可变性之间的相关性。如果相关性不是正的,则意味着模型未能了解与每个广告客户相关联的不确定性。该工具允许我们了解训练过程或模型架构中是否出了问题,并指示我们是否应该进一步调试它。
我们可以执行类似的分析,然后看看与特定事项相关的不确定性是否会减少我们展示它的次数(即向更多的用户/地方展示)。同样,我们希望模型变得更加确定,如果模型依然不确定,我们将继续调试。
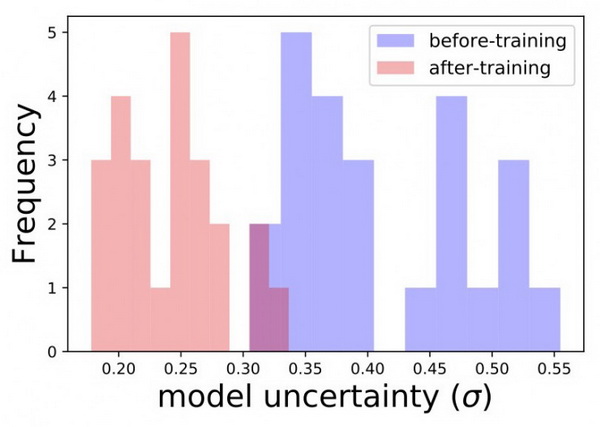
另一个很酷的例子就是标题特征:带有罕见词汇的独特标题应该会带来很高的模型不确定性。这是由于模型缺乏相关学习经验的结果。我们可以从验证集中找出那些含有罕见词汇的标题,并估计模型在这些标题上的不确定性。然后我们将使用其中一个标题重新训练模型,再观察模型在这些标题上的不确定性是否有所降低。从下面图表中我们能够获得更好的了解。
结束语
不确定性在许多领域都是一个大问题。在特定任务中明晰问题属于哪种类型的不确定性很重要的。一旦你知道如何建模,就可以通过各种方式使用它们。在这篇文章中,我们讨论了如何使用它们来调试模型。在下一篇文章中,我们将讨论从模型中获得不确定性估计的不同方法。
Via 《Using Uncertainty to Interpret your Model》

时间:2018-08-08 13:04 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















