美团R语言数据运营实战
一、引言
近年来,随着分布式数据处理技术的不断革新,Hive、Spark、Kylin、Impala、Presto 等工具不断推陈出新,对大数据集合的计算和存储成为现实,数据仓库/商业分析部门日益成为各类企业和机构的标配。在这种背景下,是否能探索和挖掘数据价值,具备精细化数据运营的能力,就成为判定一个数据团队成功与否的关键。
在数据从后台走向前台的过程中,数据展示是最后一步关键环节。与冰冷的表格展示相比,将数据转化成图表并进行适当的内容组织,往往能更快速、更直观的传递信息,进而更好的提供决策支持。从结构化数据到最终的展示,需要通过一系列的探索和分析过程去完成产品思路的沉淀,这个过程也伴随着大量的数据二次处理。
上述这些场合 R 语言有着独特的优势。本文将基于美团到店餐饮技术部的精细化数据运营实践,介绍 R 在数据分析与可视化方面的工程能力,希望能够抛砖引玉,也欢迎业界同行给我们提供更多的建议。
二、数据运营产品分类与 R 的优势
2.1 数据运营产品分类
在企业数据运营过程中,考虑使用场景、产品特点、实施角色以及可利用的工具,大致可以将数据运营需求分为四类,如下表所示:
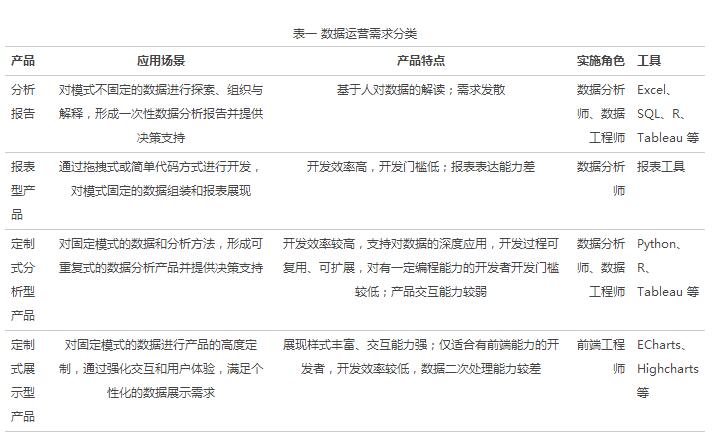
表一 数据运营需求分类
2.2 R 在数据运营上的优势
如上节所述,在精细化数据运营过程中,经常需要使用高度定制的数据处理、可视化、分析等手段,这些过程 Excel、Tableau、企业级报表工具都无法面面俱到,而恰好是 R 的强项。一般来说,R 具备的如下特征,让其有了“数据分析领域的瑞士军刀”的名号:
• 免费、开源、可扩展:截至到 2018-08-02,“The CRAN package repository features 12858 available packages. ”,CRAN 上的软件包涉及贝叶斯分析、运筹学、金融、基因分析、遗传学等方方面面,并在持续新增和迭代。
• 可编程:R 本身是一门解释型语言,可以通过代码控制执行过程,并能通过 rPython、rJava 等软件包实现和 Python、Java 语言的互相调用。
• 强大的数据操控能力:
• 数据源接入:通过 RMySQL、SparkR、elastic 等软件包,可以实现从 MySQL、Spark、Elasticsearch 等外部数据引擎获取数据。
• 数据处理:内置 vector、list、matrix、data.frame 等数据结构,并能通过 sqldf、tidyr、dplyr、reshape2 等软件包实现对数据的二次加工。
• 数据可视化:ggplot2、plotly、dygraph 等可视化包可以实现高度定制化的图表渲染。
• 数据分析与挖掘:R 本身是一门由统计学家发起的面向统计分析的语言,通过自行编程实现或者第三方软件包调用,可以轻松实现线性回归、方差分析、主成分分析等分析与挖掘功能。
• 初具雏形的服务框架:
• Web 编程框架:例如不精通前端和系统开发的同学,通过 shiny 软件包开发自己的数据应用。
• 服务化能力:例如通过 rserve 包,可以实现 R 和其他语言通信的 C/S 架构服务。
对于以数据为中心的应用来说,Python 和 R 都是不错的选择,两门语言在发展过程中也互有借鉴。“越接近统计研究与数据分析,越倾向 R;越接近工程开发工程环境的人,越倾向 Python”,Python 是一个全能型“运动员”,R 则更像是一个统计分析领域的“剑客”,“Python 并未建立起一个能与 CRAN 媲美的巨大的代码库,R 在这方面具有绝对领先优势。统计学并不是 Python 的核心使命”。各技术网站上有大量“Python VS R ”的讨论,感兴趣的读者可以自行了解和作出选择。
三、R 的数据处理、可视化、可重复性数据分析能力
对于具备编程能力的分析师或者具备分析能力的开发人员来说,在进行一系列长期的数据分析工程时,使用 R 既可以满足“一次开发,终身受用”,又可以满足“调整灵活,图形丰富”的要求。下文将分别介绍 R 的数据处理能力、可视化能力和可重复性数据分析能力。
3.1 数据处理
在企业级数据系统中,数据清洗、计算和整合工作会通过数据仓库、Hive、Spark、Kylin 等工具完成。对于数据运营项目,虽然 R 操作的是结果数据集,但也不能避免需要在查询层进行二次数据处理。
在数据查询层,R 生态现成就存在众多的组件支持,例如可以通过 RMySQL 包进行 MySQL 库表的查询,可以使用 Elastic 包对 Elasticsearch 索引文档进行搜索。对于 Kylin 等新技术,在 R 生态的组件支持没有跟上时,可以通过使用 Python、Java 等系统语言进行查询接口封装,在 R 内部使用 rPython、rJava 组件进行第三方查询接口调用。通过查询组件获取的数据一般以 data.frame、list 等类型对象存在。
另外 R 本身也拥有比较完备的二次数据处理能力。例如可以通过 sqldf 使用 sql 对 data.frame 对象进行数据处理,可以使用 reshape2 进行宽格式和窄格式的转化,可以使用 stringr 完成各种字符串处理,其他如排序、分组处理、缺失值填充等功能,也都具备完善的语言本身和生态的支持。
3.2 数据可视化
数据可视化是数据探索过程和结果呈现的关键环节,而 “R is a free software environment for statistical computing and graphics. ”,绘图(可视化)系统也是 R 的最大优势之一。
目前 R 主流支持的有三套可视化系统:
• 内置系统:包括有 base、grid 和 lattice 三个内置发行包,支持以相对比较朴素的方式完成图形绘制。
• ggplot2:由 RStudio 的首席科学家 Hadley Wickham 开发,ggplot2 通过一套图形语法支持,支持通过图层叠加以组合的方式支持高度定制的可视化。这一理念也逐步影响了包括 Plotly、阿里 AntV 等国内外数据可视化解决方案。截至到 2018-08-02,CRAN 已经落地了 40 个 ggplot2 扩展包,参考链接。
• htmlwidgets for R:这一系统是在 RStudio 支持下于 2016 年开始逐步发展壮大,提供基于 JavaScript 可视化的 R 接口。htmlwidgets for R 作为前端可视化(for 前端工程师)和数据分析可视化(for 数据工程师)的桥梁,发挥了两套技术领域之间的组合优势。截至到 2018-08-02,经过两年多的发展,目前 CRAN 上已经有 101 个基于 htmlwidgets 开发的第三方包,参考链接。
实际数据运营分析过程中,可以固化常规的图表展现和可视化分析过程,实现代码复用,提高开发效率。下图是美团到店餐饮技术部数据团队积累的部分可视化组件示例:
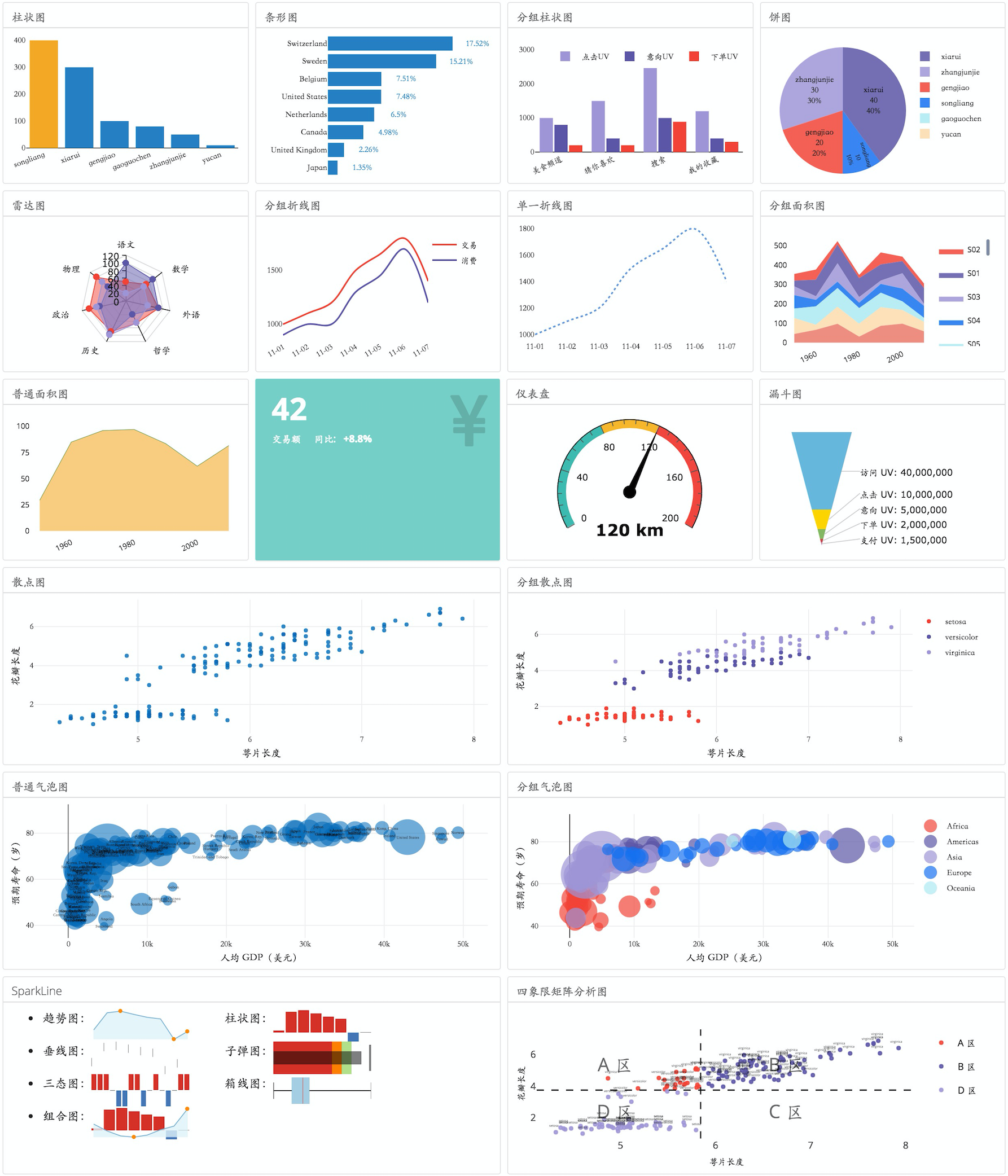
图一 可视化组件示例
基于可视化组件库,一个可视化过程只需要一行代码即可完成,能极大提升开发效率。上图中最后的四象限矩阵分析示例图的代码如下:

茲再附四象限矩阵分析可视化组件的函数声明:

3.3 可重复性数据分析
数据运营分析往往是一个重复性的、重人工参与的过程,最终会落地一套数据分析框架,这套数据分析框架适配具体的数据,用于支持企业数据决策。
RStudio 通过 rmarkdown + knitr 的方式提供了一套基于文学编程的数据分析报告产出方案,开发者可以将 R 代码嵌入 Markdown 文档中执行并得到渲染结果(渲染结果可以是 HTML、PDF、Word 文档格式),实际数据分析过程中,开发者最终能形成一套数据分析模版,每次适配不同的数据,就能产出一份新的数据分析报告。
rmarkdown 本身具备简单的页面布局能力并可以使用 flexdashboard 进行扩展,因此这套方案不仅能实现重复性分析过程,还能实现分析结果的高度定制化展示,可以使用 HTML、CSS、JavaScript 前端三大件对数据分析报告进行展示和交互的细节调整。最终实现人力的节省和数据分析结果的快速、高效产出。
四、R 服务化改造
4.1 R 服务化框架
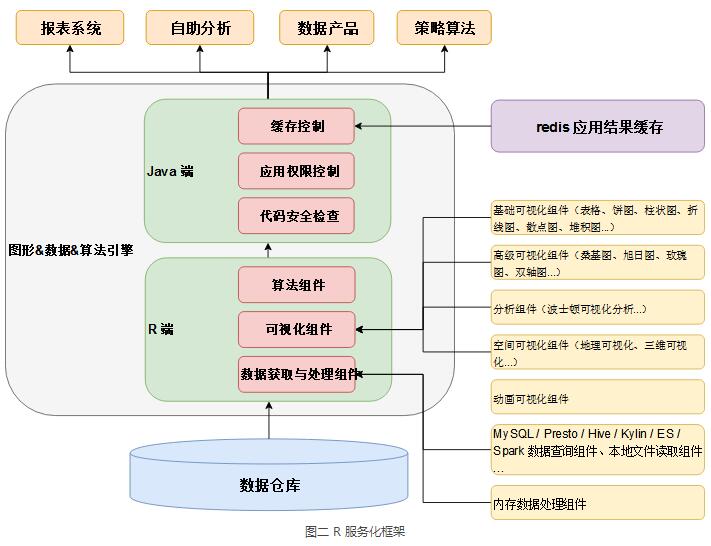
R 本身既是一门语言、也是一个跨平台的操作环境,具备强大的数据处理、数据分析、和数据可视化能力。除了在个人电脑的 Windows/MacOS 环境中上充当个人统计分析工具外,也可以运行在 Linux 服务环境中,因此可以将 R 作为分析展现引擎,外围通过 Java 等系统开发语言完成缓存、安全检查、权限控制等功能,开发企业报表系统或数据分析(挖掘)框架,而不仅仅只是将 R 作为一个桌面软件。
企业报表系统或数据分析(挖掘)框架设计方案如下图所示:
4.2 foreach + doParallel 多核并行方案
作为一门统计学家开发的解释性语言,R 运行的是 CPU 单核上的单线程程序、并且需要将全部数据加载到内存进行处理,因此和 Java、Python 等系统语言相比,计算性能是 R 的软肋。对于大数据集合的计算场景,需要尽量将数据计算部分通过 Hive、Kylin 等分布式计算引擎完成,尽量让 R 只处理结果数据集;另外也可以通过 doParallel + foreach 方案,通过多核并行提升计算效率,代码示例如下:

4.3 图形化数据报告渲染性能
在数据分析过程中,R 最重要的是充当图形引擎的角色,因此有必要了解其图形渲染性能。针对主流的基于 rmarkdown + flexdashboard 的数据分析报告渲染方案,其性能测试结果如下:
系统环境:
• 4 核 CPU,8 G 内存,2.20GHz 主频。
• Linux version 3.10.0-123.el7.x86_64。
测试方法:
测试在不同并发度下、不同复杂度的渲染模式下,重复渲染 100 次的耗时。
测试结果:
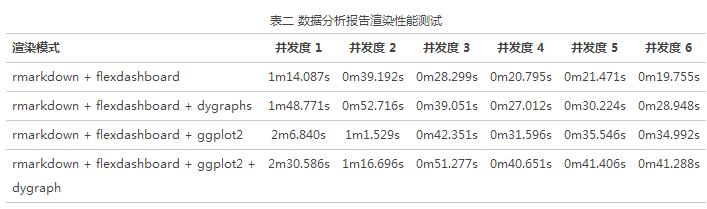
表二 数据分析报告渲染性能测试
根据测试结果可知:
单应用平均渲染时长在 0.74s 以上,具体的渲染时长视计算复杂度而定(可以通过上节介绍的“foreach + doParallel 多核并行方案 ”加快处理过程)。根据经验,大部分应用能在秒级完成渲染。
由于单核单线程模式所限,当并发请求超过 CPU 核数时,渲染吞吐量并不会相应提升。需要根据实际业务场景匹配对应的服务端机器配置,并在请求转发时设置并发执行上限。对于内部运营性质的数据系统,单台 4 核 8 G 机器基本能满足要求。
五、R 在美团数据产品中的落地实践
美团到店餐饮数据团队从 2015 年开始逐步将 R 作为数据产品的辅助开发语言,截至 2018 年 8 月,已经成功应用在面向管理层的日周月数据报告、面向数据仓库治理的分析工具、面向内部运营与分析师的数据 Dashboard、面向大客户销售的品牌商家数据分析系统等多个项目中。目前所有的面向部门内部的定制式分析型产品,都首选使用 R 进行开发。
另外我们也在逐步沉淀 R 可视化与分析组件、开发基于 R 引擎的配置化 BI 产品开发框架,以期进一步降低 R 的使用门槛、提升 R 的普及范围。
下图是美团到店餐饮数据团队在数据治理过程中,使用 R 开发的 ETL 间依赖关系可视化工具:
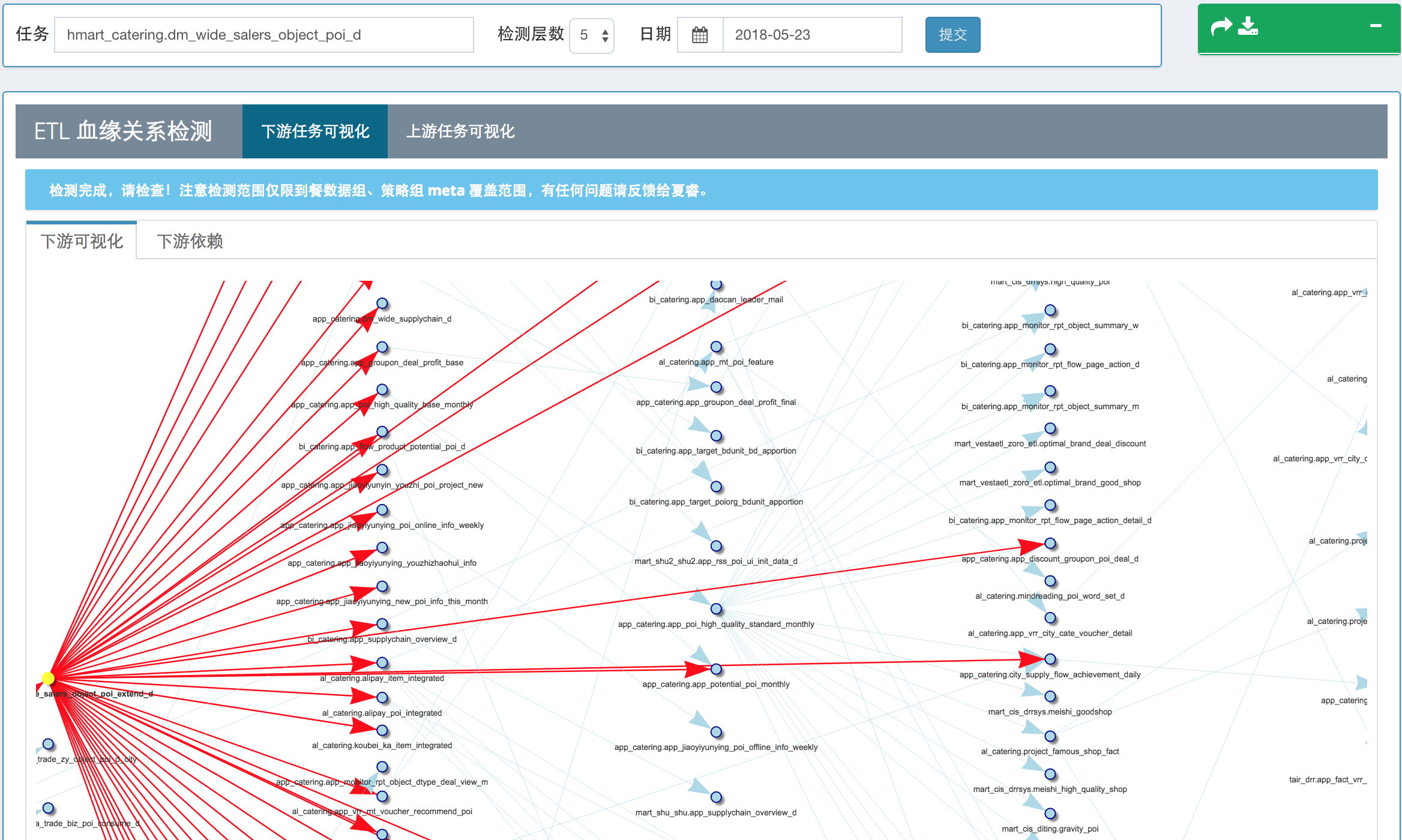
图三 ETL 间依赖关系可视化工具
六、结语
综上所述,R 可以在企业数据运营实践中扮演关键技术杠杆,但作为一门面向统计分析的领域语言,在很长一段时间,R 的发展主要由统计学家驱动。随着近年的数据爆发式增长与应用浪潮,R 得到越来越多工业界的支持,譬如微软收购基于 R 的企业级数据解决方案提供商 Revolution Analytics、在 SQL Server 2016 集成 R、并从 Visual Studio 2015 开始正式通过 RTVS 集成了 R 开发环境,一系列事件标志着微软在数据分析领域对 R 的高度重视。
作者撰写本文的目的,也是希望给从事数据相关工作的同学们一个新的、更具优势的可选项。
关于作者:喻灿,美团到店餐饮技术部数据系统与数据产品团队负责人

时间:2018-08-06 17:39 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















