干货:Spark在360商业数据部的应用实践
Spark的应用现状
Spark需求背景
随着数据规模的持续增长,数据需求越来越多,原有的以MapReduce为代表的Hadoop平台越来越显示出其局限性。主要体现在以下两点:
• 任务执行时间比较长。特别是某些复杂的SQL任务,或者一些复杂的机器学习迭代。
• 不能很好的支持像机器学习、实时处理这种新的大数据处理需求。
Spark作为新一代大数据处理的计算平台,使得我们可以用Spark这一种平台统一处理数据处理的各种复杂需求,非常好的支持了我们目前现有的业务。与原有MapReduce模型相比,其具有下面3个特点:
• 充分使用内存作为框架计算过程存储的介质,与磁盘相比大大提高了数据读取速度。利用内存缓存,显著降低算法迭代时频繁读取数据的开销。
• 更好的DAG框架。原有在MapReduce M-R-M-R的模型,在Spark框架下,更类似与M-R-R,优化掉无用流程节点。
• 丰富的组件支持。如支持对结构化数据执行SQL操作的组件Spark-SQL,支持实时处理的组件Spark-Streaming,支持机器学习的组件Mllib,支持图形学习的Graphx。
以Spark为核心的数据平台结构
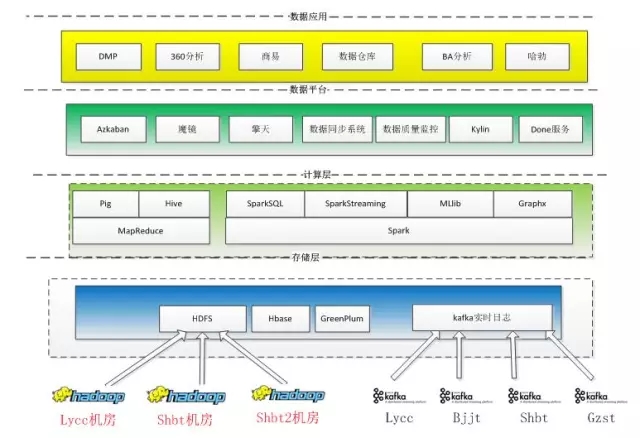
商业数据部的数据平台架构如上图所示,Spark在其中起到一个非常核心作用。目前每天提交的Spark作业有1200多个,使用的资源数Max Resources:
Spark的几种典型应用
基于SparkStreaming的实时处理需求
商业数据部内部有大量的实时数据处理需求,如实时广告收入计算,实时线上ctr预估,实时广告重定向等,目前主要通过SparkStreaming完成。
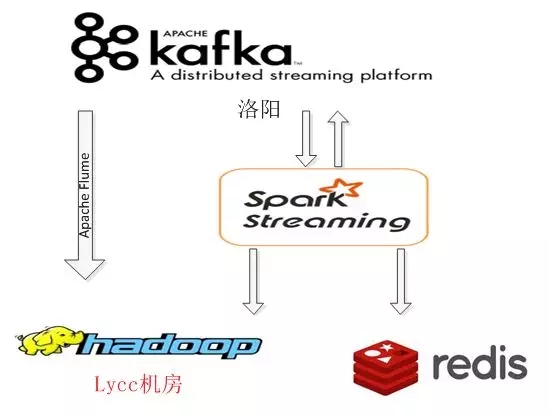
实时数据处理的第一步,需要有实时的数据。360的用户产品,几乎全国各地都部署有机房,主要有4大主力机房。实时数据的收集过程如下:

使用Apache flume实时将服务器的日志上传至本地机房的Kafka,数据延迟在100ms以内。
使用Kafka MirorMaker将各大主力机房的数据汇总至中心机房洛阳,数据延迟在200ms以内。由于公司的网络环境不是很好,为了保证低延迟,在MirorMaker机房的机器上,申请了带宽的QOS保 证,以降低延迟。
数据处理的实时链路如下所示:
• 1种方式是通过Apache Flume实时写入Hdfs,用于第二天全量数据的离线计算
• 1种方式是通过SparkSteaming实时处理,处理后数据会回流至Kafka或者Redis,便于后续流程使用。
基于SparkSQL和DataFrame的数据分析需求
SparkSQL是Spark的核心组件,作为新一代的SQL on Hadoop的解决方案,完美的支持了对现有Hive数据的存取。在与Hive进行集成的同时,Spark SQL也提供了JDBC/ODBC接口,便于第三方工具如Tableau、Qlik等通过该接口接入Spark SQL。
由于之前大部分数据分析工作都是通过使用hive命令行完成的,为了将迁移至SparkSQL的代价最小,360系统部的同事开发了SparkSQL的命令行版本spark-hive。原有的以hive 命令运行的脚本,简单的改成spark-hive便可以运行。360系统部的同事也做了大量兼容性的工作。spark-hive目前已经比较稳定,成为数据分析的首选。
DataFrma是Spark 1.3引入的新API,与RDD类似,DataFrame也是一个分布式数据容器。
但与RDD不同的是,DataFrame除了数据以外,还掌握更多数据的结构信息,即schema。同时,与Hive类似,DataFrame也支持嵌套数据类型(struct、array和map)。从API易用性的角度上 看,DataFrame API提供的是一套高层的关系操作,比函数式的RDD API要更加友好,门槛更低。
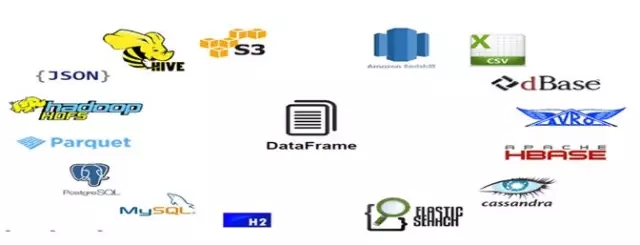
大数据开发过程中,可能会遇到各种类型的数据源,而DataFrame与生俱来就支持各种数据类型,如下图,包括JSON文件、Parquet文件、Hive表格、本地文件系统、分布式文件系统(HDFS)以及云存储(S3)。同时,配合JDBC,它还可以读取外部关系型数据库系统如Mysql,Oracle中的数据。对于自带Schema的数据类型,如Parquet,DataFrame还能够自动解析列类型。
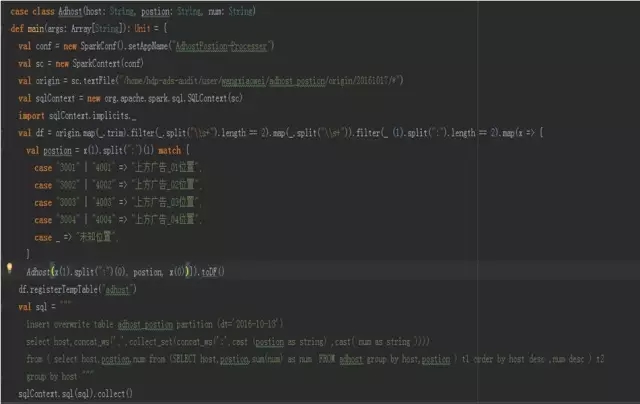
通过组合使用DataFrame和SparkSQL,与MapReduce比较大大减少了代码行数,同时执行效率也得到了提升。如下示例是处理广告主位置信息的scala代码。
基于MLLib的机器学习需求
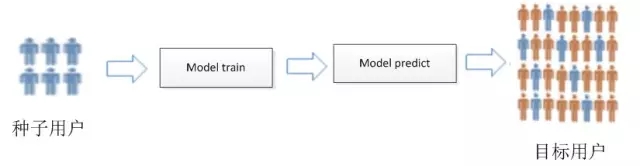
360DMP提供人群扩展功能(Look-alike)。所谓人群扩展,是基于广告主创建的种子用户,根据这些种子用户的特征,挖掘、筛选、识别、拓展更多具有相似特征的用户,以增加广告的受众。
业界的Look-alike有2种做法。第一种做法就是显性的定位。广告主先选中一部分种子用户,根据种子用户的标签再定位扩展一部分其他用户。比如如果种子用户选择的都是“化妆品-护肤”这个标签,那么根据这个标签可以找到其他的用户,作为扩展用户。这种做法的缺点是不够精确,扩展出来的用户过大。第二种方法是通过一个机器学习的模型,将问题转化为机器学习模型,来定位广告主的潜在用户。我们采用的是这种方法。
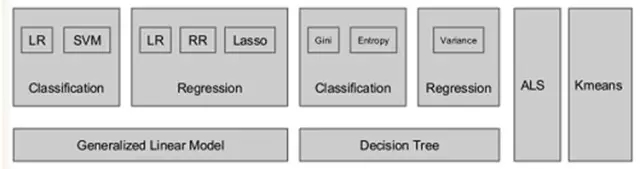
在做Look-alike的过程中,用到了Spark中的Mlilib库。MLlib算法库的核心库如上,选择的是Classification中LR算法,主要原因有两个:
• 模型比较简单,易于理解和实现
• 模型训练起来速度比较快,时间可控。
LookAlike的第一步是建立模型。在这里,广告主会首先提交一批种子用户,作为机器学习的正样本。其他的非种子用户作为负样本。于是问题就转化为一个二分类的模型,正负样本组成学习的样本。训练模型之后,通过模型预测,最后得到广告主需要的目标人群。
部分经验总结
使用Direct模式处理kafka数据
SparkStreaming读取Kafka数据时,有两种方法:Direct和Receiver。我们选择的是Direct方法。与基于Receiver的方法相比,Direct具有以下优点:
简化并行性。无需创建多个输入Kafka流和联合它们。使用directStream,Spark Streaming将创建与要消费的Kafka分区一样多的RDD分区,这将从Kafka并行读取数据。因此,Kafka和RDD分区之间存在一对一映射,这更容易理解和调整。
效率。在第一种方法中实现零数据丢失需要将数据存储在预写日志中,该日志进一步复制数据。这实际上是低效的,因为数据有效地被复制两次。第二种方法消除了问题,因为没有接收器,因此不需要预写日志。
Exactly-once语义。第一种方法使用Kafka的高级API在Zookeeper中存储消耗的偏移量。这是传统上消费Kafka数据的方式。虽然这种方法(与预写日志结合)可以确保零数据丢失(即至少一次语义),但是一些记录在一些故障下可能被消费两次,这是因为Spark Streaming可靠接收的数据与Zookeeper跟踪的偏移之间存在不一致。因此,在第二种方法中,我们使用不基于Zookeeper的简单的Kafka API,偏移由Spark Streaming在其检查点内跟踪。这消除了Spark Streaming和Zookeeper / Kafka之间的不一致,所以每个记录被Spark Streaming有效地接收一次。
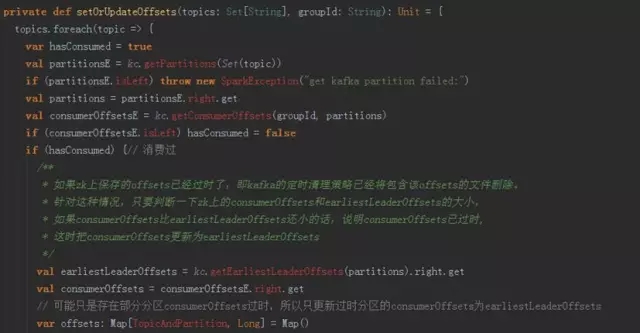
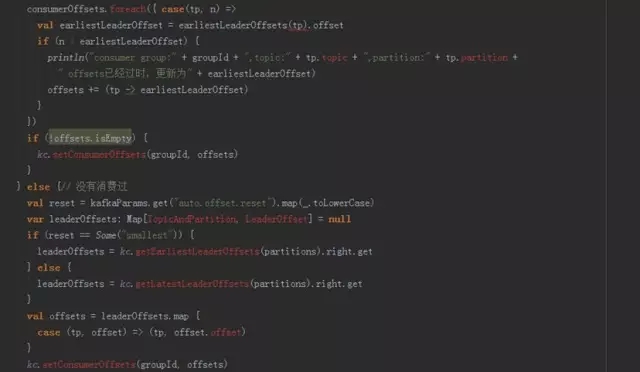
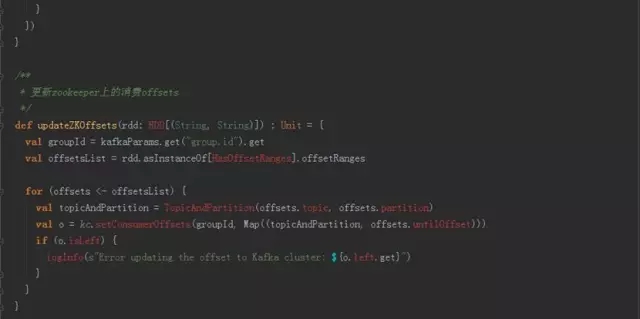
Direct方法需要自己控制消费的kafka offset,参考代码如下。
SparkSQL中使用Parquet
相比传统的行式存储引擎,列式存储引擎因其更高的压缩比,更少的IO操作而越来越受到重视。这是因为在互联网公司的大数据应用中,大部分情况下,数据量很大并且数据字段数目比较多,但是大部分查询只是查询其中的部分行,部分列。这个时候,使用列式存储就能极大的发挥其优势。
Parquet是Spark中优先支持的列存方案。与使用文本相比,Parquet 让 Spark SQL 的性能平均提高了 10 倍,这要感谢初级的读取器过滤器、高效的执行计划,以及 Spark 1.6.0 中经过改进的扫描吞吐量。
• SparSQL的Parquet的几个操作:
1)创建Parquet格式的Hive表
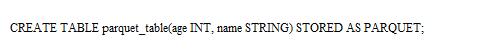
2)读取Parquet格式的文件
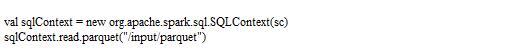

3)保存为Parquet格式文件

Spark参数调优
1)spark.sql.shuffle.partitions:在做Join或者Group的时候,可以通过适当提高该值避免数据倾斜。
2)spark.testing.reserveMemory:Spark executor jvm启动的时候,会默认保留一部分内存,默认为300m。适当的减少这个值,可以增加 spark执行时Storage Memory的值。设置方式是启动spark shell的时候加上参数:--conf spark.testing.reservedMemory= 104857600。
3)spark.serializer:Spark内部会涉及到很多对数据进行序列化的地方,默认使用的是Java的序列化机制。Spark同时支持使用Kryo序列化库,Kryo序列化类库的性能比Java序列化类库的性能要高很多。官方介绍,Kryo序列化机制比Java序列化机制,性能高10倍左右。Spark之所以默认没有使用Kryo作为序列化类库,是因为Kryo要求最好要注册所有需要进行序列化的自定义类型,因此对于开发者来说,这种方式比较麻烦。设置方法是conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")。

时间:2018-08-06 17:39 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
下一篇:美团R语言数据运营实战
相关文章:
相关推荐:
网友评论:















