银行大数据的演变趋势是什么?
银行业一直走在数字化转型的前沿,客户画像、精准营销、反欺诈等几乎所有的业务都与数据息息相关,而在这些业务背后做支撑的就是银行的大数据平台。首届 Kylin Data Summit 特别邀请了建信金融科技的架构团队技术总监朱志,为大家分享银行大数据架构的演变过程、未来展望和深度思考。朱志先生长期从事信息技术规划、架构管理、大数据分析平台研发、数据及技术标准化等工作。
银行大数据的过去与现在
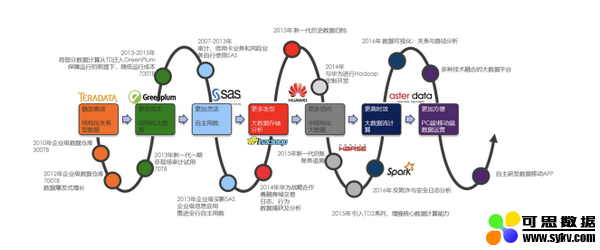
建设银行长期以来持续关注着大数据行业技术和趋势的发展。跟随着数据技术的不断更新,建设银行每年都会同步更新自己的路线图。建行一边在数据驱动,一边应用驱动,不断地找新亮点来突破我们自己的行业。

(Big Data Landscape 2018)
在两三年前,建行就把数据和敏捷开发结合在一起,实现了一个内部的数据应用。当很多人还需要大量页面开发来实现仪表盘功能时,建行就已经实现了用一个很小团队,支撑全行所有人在手机上使用数据,所有数据像同花顺股票一样可以定制,不需要开发,而且可以支撑几十万用户的访问。
回看过去,从数据仓库一体机,到 Hadoop 崛起,到今天进入了一个混沌状态,没有人知道大数据未来。但是在我们看来,我们期待未来一定会有一个技术能够突破出来,变成指数级增长。
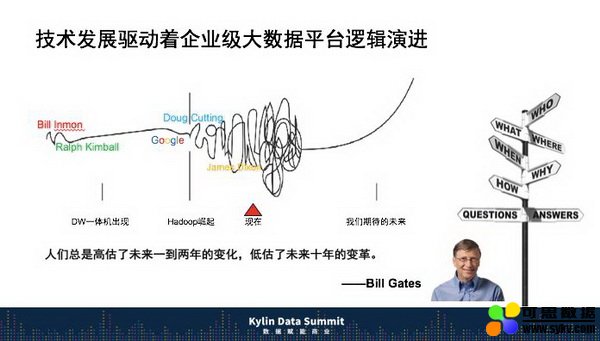
整个过程其实是大数据架构演进的过程,从开始 INMON 和 KIMBALL 不断地争吵,卖一体机的非常喜欢 INMON 。做服务的人喜欢 KIMBALL ,可以快速启动一个数据项目。他俩打架打了 30 年,银行就在他们争论中演进了 30 年。一直走到有一天谷歌写了三篇著名的关于分布式的论文。这三篇论文是一个基点,而把这个文章给放大出来的人,是 Doug Cutting。而最近新一轮的混乱是谁引起的?James Dixon,Pentaho 的 CTO,他提出了 Data Lake。
从事架构工作一直要回答路线之争。对于银行业来说,未来到底是数据湖还是数据仓库?数据湖会不会替代数据仓库? Gartner 还提出了 Data Hub。这就是我们今天面临的现状,我们迫切希望尽早突破这种混沌,走到未来一个指数级的数据区间。
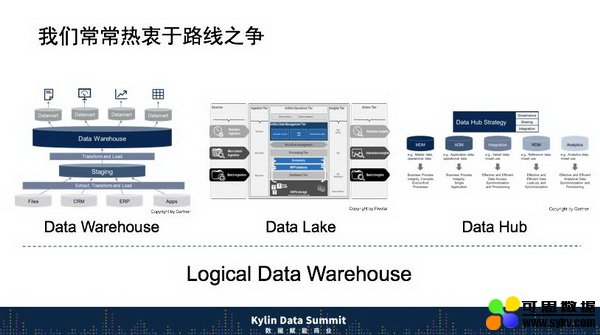
Data Lake 根据数据不同的时效性,可以更方便进行业务洞察,有了这样的架构。Data Hub ,我发现跟我们十几年前 ODS 差不多,多了个云数据。各方面的争论太多了,Gartner 又提出了一个词叫 Logical Data Warehouse,希望能够统一这些路线。而关于这些路线之争深刻困扰着架构工程师们,目前建行在内部走成了如下图这个结构,Data Hub 在建行内部叫数据复制组件,可以由业务人员自己定制将数据,将数据复制到指定位置,因此有些工程师将开始失业了。
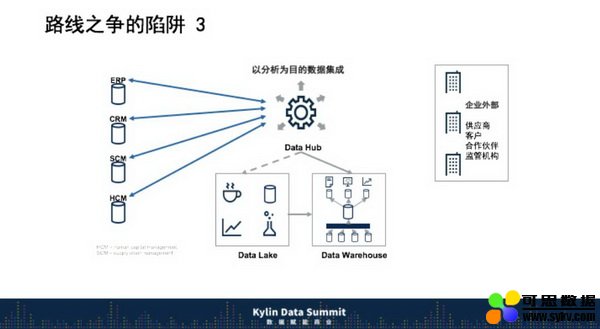
同时,我们也还在使用传统的数据仓库,因为银行有大量监管的东西没法替代。但是整个数据探索,就是所谓的数据湖在不断地增长,所以最后走成了今天这个样子。但我觉得还是个陷阱,因为这里面耗费了大量的资源和人力。
前进中遇到的困难
一起看下面这张图,我们从问题和数据两个维度看,什么样的东西应该用什么架构。我们发现创新与探索适用于未知的问题和未知的数据,用 Data Lake 更合适;而左下角已知数据和已知问题用 Data Warehouse 用容易一些。Gartner 发布了一个更复杂的图,但是现实情况并不是这么具有逻辑性。在银行业大家都知道,银行业非常依赖外包,无论是外包,还是互联网,大家都很想做 to B 业务。

在 to B 业务领域内,很多一体机厂商喊了非常多年 TCO,实际在甲方做决定时,没有人能拿出 TCO 这个数据。新技术的演进很快,从一体机到 Hadoop、Spark、Flink 再到 Kylin。但无论技术怎么进步,我发现我们的外包厂商只会写 SQL。我们做了非常多 SQL,沉淀了 20 年,业务部门不会为过去的努力买单,我们所有新技术似乎只能做新的业务场景,这就是我们今天乃至过去五六年,作为银行业的架构师所面临的窘境。
这个窘境怎么解决呢?我们做过一个尝试。这个架构图展示了建行如何去做一个混合的数据架构。我们面对外包服务人员写的 SQL,随意挑出一个 SQL 语句可以打五到六页 A4 纸大小,我们想方设法地把一个 SQL 语句从一个技术搬到另外一个技术,比如常见的就是比如说 Teradata 搬到 SQL Server, SQL Server 搬到 Oracle,Oracle 搬到 Greenplum,还想搬到 Hadoop 上。
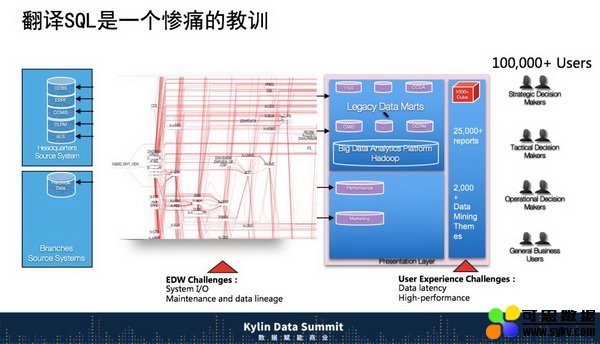
当迁移到 Hadoop 的时候问题就来了。我们分析这些 SQL,分析完了以后看起来很漂亮,其实没有用。我们做了大量的解释语句,我们付出的惨痛代价得到了一个教训。当技术的基础逻辑改变的时候,我们不应该翻译 SQL,这个只会牵绊住我们。当我们简单保持逻辑,把 SQL 语句从一个地方翻译到另外一个地方,遭遇了更大的挑战,数据 IO 遇到很大挑战,数据血缘关系上碰到了挑战,数据整个时间窗口碰到挑战,包括数据性能也碰到挑战。保持业务一致性,其实牺牲了所有跟技术相关的东西,这就是我们最大的教训。
银行业未来的格局
今天看,如果只从技术出发来解决解决问题,是走不出这个混沌的。去年我参加了金融科技战略规划的会议,在这个会议上看到了银行业未来,这也是我们成立建信金融科技公司原因。刚开始银行和互联网业独立发展,到现在其实开始慢慢合作了,未来很多数据会在金融科技公司,这将会形成相互的引流。
比尔盖茨:“我们需要银行业,但不需要银行”。
下面这张图介绍的是 wells Fargo 一家美国银行的在线业务,每一个线上业务都可以找到一个美国金融科技公司替代。我们必须通过回到银行业的本质来找整个数据平台未来的模式。

对于银行业来说,第一原理是什么?过去银行都是在钢筋水泥中,今天银行是线上,线上银行有什么变化呢?有什么没有变的呢?
银行业本质就是存贷汇。存,是资金端创新,也就是互联网金融过去十年做的事情;贷,这是接下来银行业热点,我们要把资金端和优秀资产端对接;汇,就是发生交易的地方,这就是银行业本质,就是完成资源在时间和空间上的错配,这就是银行业本质。
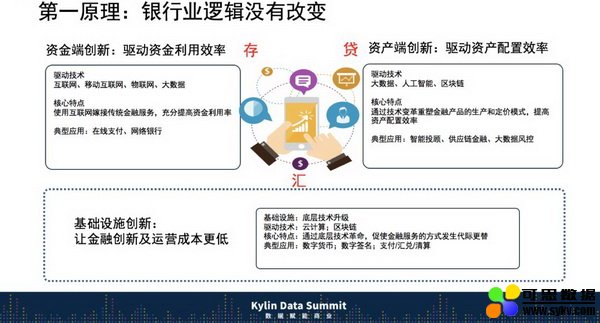
而每一个改变,都是技术驱动,任何一个点都离不开数据,银行业未来是什么呢?
第一:虚拟化。首先它是一个分布式架构,这个分布式架构不是指在不同机器上存储数据,而指在不同的法人实体间,就像今天建信金融科技跟建设银行之间的关系,它是指不同法人之间关系。
第二:贯穿企业的内部运营和外部环境之间的关系。过去做数据仓库的时候,更多使用企业内部信息,而今天可能你不知道自己要在哪里分析数据,需要结合环境、企业应用以及所涉及的问题。
第三:用户想在哪看数据,应该在哪看数据,就可以在哪看数据。昨天是 PC,今天是手机,明天可能是一个可以操纵的物体,最后一个重要的事情是不能用逻辑驱动这个技术,而需要靠 TCO、SLA 来驱动这个变化,
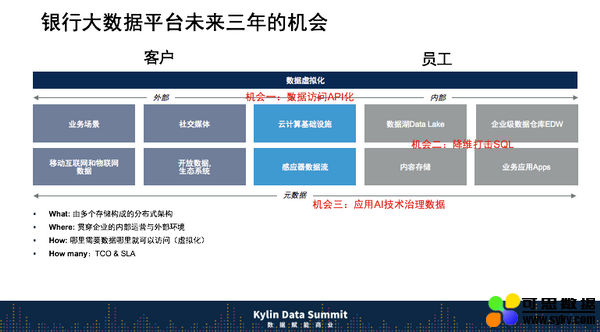
未来,银行大数据平台的三个机会
第一个机会:数据访问 API 化。这句话是讲给,从事 to B 业务,也包括自己。完成数据 API 化,打通内部和外部,包括打通内部之间不同形态的技术。
第二个机会:降维打击 SQL。我们需要更多方式来解析数据,包括 Gartner 提到的,我们可以用一些自然语言,自然语言有点太先进了,过去微软提出来 MDX,还有最近提出来的函数式编程,还有更多的编程模式来替代 SQL,来提高效率。
第三个机会,应用更多 AI 技术治理数据。

时间:2019-08-05 18:48 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















