工业4.0的大数据挑战
横跨18世纪后半叶和19世纪上半叶的第一次工业革命使世界发生了翻天覆地的变化:机械化和引擎驱动的生产工艺和工具取代了人工方法。第一次工业革命催生了工厂制度和大规模生产。
而在200年之后,21世纪的制造业将被工业4.0,也就是第四次工业革命所颠覆。先进的数字技术正被用于优化和自动化生产,包括上游供应链流程。工业4.0的最终目标是嵌入在机器和组件中,并采用始终连接的传感器将实时数据传输到网络IT系统。反过来,这些应用机器学习和人工智能算法来分析和获取这些的见解,并根据需要自动调整其过程。
工业4.0的革命本身并不是大数据,因为制造商已经在很长一段时间内生成了大量的实时生产和质量数据。然而,由于缺乏能够真正利用这些不同数据源并提取总体见解以提高质量和生产力的平台,这些孤岛数据的浪费并不罕见。换句话说,其症结不是生成和收集数据,而是能够有效地从中提取价值。
最大的挑战:从制造业大数据中提取价值 工业4.0大数据来自许多不同的来源:
•产品和/或机器设计数据,如阈值参数
•来自控制系统的机器操作数据
•产品和过程质量数据
•工作人员实施的人工操作记录
•制造执行系统
•有关制造和运营成本的信息
•故障检测和其他系统监控部署
•物流信息,包括第三方物流
•有关产品使用、反馈等的客户信息 其中一些数据源是结构化的(例如传感器信号),一些是半结构化的(例如人工操作的记录),还有一些是完全非结构化的(例如图像文件)。然而,在很多情况下,大多数数据或者是未使用的,或者只是用于非常具体的战术目的。工业4.0大数据通常没有战略利用的一个关键因素是不兼容的技术、系统和数据类型之间的互操作性较差;第二个关键因素是传统IT系统无法存储、操作和管理高速生成的大量不同数据。
因此,企业需要的是能够充分利用机器学习、人工智能和预测分析制造大数据的价值的先进平台。
工业4.0大数据愿景 如今,制造商寻求通过收集、分析和共享所有关键功能领域的数据来实现真正的商业智能。在这种体系结构中,生产系统不仅效率更高,而且能够及时响应不断变化的业务需求,其中包括来自合作伙伴和客户的信号。
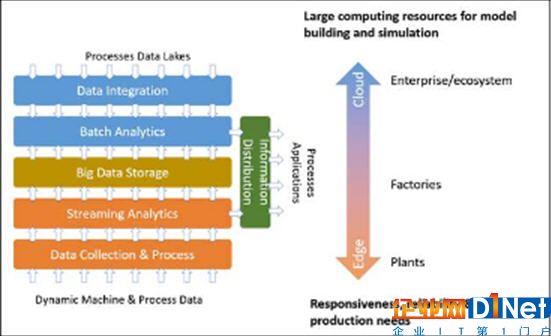
该模型更专注于工厂和工厂级别的大数据和分析流程 下层的(橙色)堆栈快速并可扩展地收集、处理和分析来自生产车间的数据流。上层(蓝色)堆栈用于大规模和密集的批量分析,很可能在基于的大数据框架中实现。请注意,批处理分析堆栈还将存储的工厂/厂商大数据作为输入。然后,数据流和批量分析输出都作为信息分发,以优化制造流程和应用程序。
工业4.0大数据用例 2016年,普华永道公司对航空航天、国防与安全、汽车、电子和工业制造等各行业采用工业4.0的情况进行了全球性调查。平均而言,受访者表示,到2020年工业4.0实施(包括大数据分析)将使其生产和运营成本降低3.6%,累计节省4210亿美元。 以下是一些说明工业4.0大数据愿景如何为制造商带来可衡量价值所选定的实际例子:
•合并质量和生产数据以提高生产质量:半导体制造商开始将生产过程结束时测试阶段捕获的单芯片数据与在流程早期收集的过程数据相关联。制造商可以在早期识别出有缺陷的芯片,并大大提高生产过程的质量。
•授权客户:汽车行业热衷于采用工业4.0,以经济有效地满足消费者对更加实惠和数字连接汽车的期望。在联网汽车将生成的大量大数据用例中,其中就有与制造商无缝交换数据。除了为车主提供更好的售后服务外,还可以使用有关汽车性能的汇总信息来改进质量流程和未来的设计。
•减少停机时间:适用于许多工业部门,工业4.0大数据分析可以在机器或流程故障发生前发现预测模式。机器主管将能够实时评估过程或机器性能,在许多情况下,还可以防止计划外停机。
最后的说明 随着物联网和其他传感器的迅速普及,数据的数量和速度只会随着工业制造业的增长而增长。正如其他行业已经采用尖端技术以从大数据(边缘计算、雾计算、云计算等)中提取价值一样,工业4.0正在为广泛的大数据分析铺平道路。制造商的投资回报率已经在提高运营效率、提高质量,以及更快地响应不断变化的市场信号方面具有吸引力。
如今,制造商需要参与工业4.0革命的供应商提供解决方案,并为多个行业的客户带来可衡量的价值。他们需要收集、处理和生成来自多个不同来源数据的解决方案,并合并这些数据,以便为全天候实施自动化规则和自适应机器学习提供实时的透视分析。最重要的是,制造商需要这些解决方案与现有企业系统无缝集成,以便使生产和质量流程与其核心业务目标保持一致。

时间:2019-05-10 00:17 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















